
Podcast
晚点聊 LateTalk
Hosted by 晚点 LatePost · ZH
《晚点聊 LateTalk》由《晚点 LatePost》出品。 最一手的科技访谈,最真实的从业者思考。
64episodes
Episodes
Newest firstAll episodes

172: Momenta IPO后再访曹旭东:就是想做没有尽头的AI
3d ago02:03:20Tap to summarize过去六年我曾四次采访曹旭东,每次见面他都穿着 Momenta 的文化衫,这一次也是。 他里面穿着一件 T-short,胸前印着 Momenta 的飞轮图示。“一个飞轮、两条腿”这是 Momenta 从成立到现在,说了十年、做了十年的战略。以至于 Momenta 有员工会戏称自己在“飞轮公司”上班。 T 恤外面,他套着另一件公司夹克,印着 Momenta 的十年愿景和百年愿景: 十年愿景有三条,最重要的一条是印在衣服背后的“十年挽救百万生命”。(另外两条是:十年解放百分百时间、十年物流出行效率翻倍。) 百年愿景则没有限定在智能驾驶,“Better AI, Better Life” ,这句简短的话被印在长袖外套的袖口,抬手即见。 曹旭东说,当时之所以定下这个百年愿景,是想给自己和公司树立一个有生之年做不到头的 AI 目标。 而之所以在公司的衣服、杯子等各种周边上都印满“飞轮”和愿景,是因为重要的事得不停重复说,提醒自己,提醒团队。「你必须活得像一句广告。」两年前的上一次采访中,他用脑海里冒出这句陈奕迅歌词形容这个方法论。 从 30 岁开始创业,曹旭东和 Momenta 联创团队是中国第一批 AI 研究员出身的科技创业者,他们没有任何产业背景,而十年后,Momenta 在第三方城区 NOA 的份额超过 65% ,比华为等其他对手的总和还多。 Momenta 的故事可以帮助回答一个问题——出发时只有技术能力的公司,如何在复杂、多变的商业世界里,既维持技术竞争力,又完成商业落地? 《对话 Momenta 曹旭东:超越智驾的摩尔定律》 两年前的专访我们也发过播客,可见《晚点聊》77 期。那一次我们更多聊了具体方法论。 这一次发生在 IPO 前后的专访,我与曹旭东聊了他的思考和判断方式如何形成,和下一个十年,他面向具身智能和物理 AI 的推演。 本期节目已发布图文版: 《Momenta IPO 后专访曹旭东:聪明人如何下笨功夫》 本期嘉宾: 曹旭东,Momenta 创始人 本期主播: 程曼祺,《晚点 LatePost》科技报道负责人 时间线: -量产智驾的战争结束了 03:54 什么叫“竞争结束”?改变格局的窗口正在关闭 07:59 智驾从 nice to have 走到了 must have 17:50 车企的竞争力不在于能做智驾 -机器人和物理 AI:2030 会发生什么 27:41 家庭场景拐点将至,R7 验证了世界模型 34:54 同样创业十年的 Momenta 和宇树 39:06 RoboVan > RoboTruck > RoboTaxi 44:54 量产智驾、Robo 和机器人,世界模型是共同底座 48:52 “规模不是我们思考的出发点” -当一个学物理的人想做 AI 58:04 一旦思考起智能,停不下来 01:04:55 从孙剑那儿学到的:超一流的人是聪明人下苦功夫 01:09:09 加入商汤,十年前的 AI 赋能百业 01:15:33 不再只是研究员:天性偏好、底层愿望 01:20:27 创立 Momenta:感知和认知的结合点 01:23:30 为什么十年前就看到“数据驱动”? 01:29:12 数据驱动的推演:要量产,不要 Waymo -现在的“不复杂”,过去的“很痛苦” 01:34:27 从一个研究院到真的创业公司 01:38:46 从“血肉模糊”的首个客户到研发和交付的“主线原则” 01:47:50 “相信”和“真的相信”不一样 01:49:52 回到一线,回到一线,回到一线 01:57:50 狐狸知道很多事,刺猬知道一件大事 相关链接: 《Momenta IPO 后专访曹旭东:聪明人如何下笨功夫》 晚点聊 77 期:《不仅是车企的战争,与 Momenta 创始人曹旭东聊智驾供应商生存法》 《对话 Momenta 曹旭东:超越智驾的摩尔定律》 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →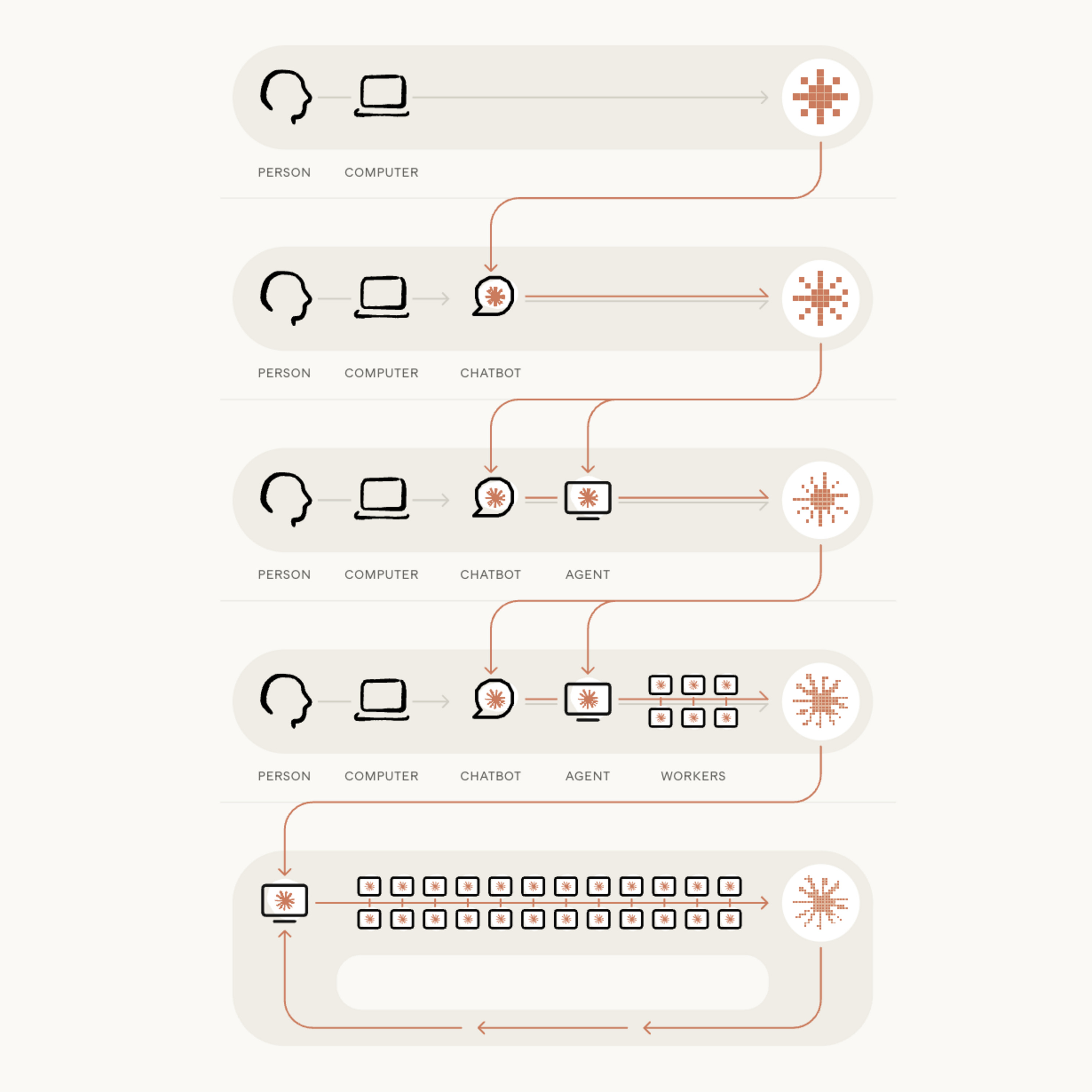
171: 【AI季报 26Q2】从 coding 到 RSI,强者愈强的未来?
2w ago01:39:42Tap to summarize眼下的竞争 & 未来的焦点。 继续带来 2026 年 Q2 的 AI 季报,嘉宾仍是 MoE Capital 创始合伙人 Henry Yin。 这个季度,我们沿两条脉络来看 AI 的进展,一是推进智能前沿: OpenAI 和 Anthropic 间的竞争:上季度季报预言的 Codex “反扑”,本季发展如何? - RSI(Recursive Self-Improvement,递归自进化):延续上季季报的 AutoResearch/自进化的讨论,RSI 在 Q2 大热,Anthropic 专门写了 RSI 长文《When AI builds itself》,更多新创业公司正在涌现。上周内,我就了解到数个在这一方向创业的新团队,有些已经官宣,更多还在水下。 本期播客封面,即是这篇文章中,Anthropic 对过去的工作循环和未来 AI 参与更多的 RSI 状态的设想图示。 Robotics 和物理 AI:不仅 Sam Altman 在 5 月底官宣了 OpenAI Robotics 团队,行业传言, Anthropic 也在考虑这个方向。 第二条线是智能的扩散: 更多企业客户想要自己的模型——这成为 Fireworks、Applied Compute 等美国科技公司和智谱 GLM 等中国开源模型的共同机会。 交互创新:OpenAI 带来了 Record and Replay,Claude 终于接入 Slack 群协作(Claude Tag);Thinking Machines Lab 带来创新的流式语音模型 Interaction Model。 最后,我们补充聊了 Google、Meta、xAI 的近况,还有很久没上头条的 Midjourney,它居然做起了超声波医学影像设备。创始人 Holz 聊起新业务时说:“我们甚至还没用到 AI”。 *一个小说明:我们录这期节目时是 6 月 27 日。这之后行业又有重要变化,如 Anthropic Fable 5 恢复全量上线。节目里的这部分内容有滞后。 本期节目的图文版也已经发布:AI 季报 26Q2:从 coding 到 RSI,强者愈强的未来? 节目中聊到的一些新公司、人物和行业术语,可先参考 shownotes 末尾的「附录」。 本期嘉宾: Henry Yin,MoE Capital 创始合伙人 本期主播: 程曼祺,晚点科技报道负责人 时间线: 04:20 上季季报回顾:延续的、反转的 【推进智能前沿】 -OpenAI vs Anthropic 08:21 当前竞争:两家的新模型、coding Agent 份额和价格战 19:26 相关第三方:被收购的 Cursor,创业公司中的第一名仍有高额溢价 22:01 对模型已最强的公司来说,不是”模型即产品“ -RSI 递归自进化 28:04 是什么?为什么火?涌现的新团队 32:14 Anthropic 长文《When AI builds itself》 39:15 Recursive Superintelligence 6 月中旬的第一批具体成果 -物理 AI 43:14 OpenAI 官宣 Robotics 团队,Anthropic 为何也考虑做机器人? 46:24 《世界模型》研究报告的梳理与发现 【智能的扩散】 51:39 美国公司用中国开源模型,自己拥有自己的模型 01:05:59 新的交互:Record & Replay、Claude Tag;TML 和 OpenAI realtime 的本季语音新模型 【其它重点公司】 01:23:25 Meta、Google、xAI 近况;赶上最强梯队的可能性? 01:34:26 Midjourney 的”不务正业“,发布超声波医学影像设备全身扫描器 剪辑:Nick、甜食 相关链接: 往期 AI 季报: 156 期 【AI季报 26Q1】OpenClaw、OpenAI vs Anthropic的三重对阵、自进化 156 期 图文版 往期具身季报: 170 期 【具身季报 26Q2】世界模型大风不停,和不想被贴标签的人 170 期 图文版 157 期 【具身季报 26Q1】宇树招股书、人形再思考、英伟达世界模型、高自由度灵巧手 157 期 图文版 2025 年末回顾: 150 期 年末 AI 回顾:从模型到应用、从技术到商战,拽住洪流中的意义之线 150 期 图文版 附录:本期中出现的一些公司、人物、技术术语: 公司/机构 & 相关人物 Recursive Superintelligence(RSI) — Richard Socher(前 Salesforce 首席科学家、You.com 创始人)、田渊栋(前Meta FAIR研究总监)、施天麟(Tim Shi,Cresta 联创)等 8 位联合创始人一起创立的 Neo Lab,做“递归自我改进”研究,6 月初官宣,估值 46.5 亿美元。 Mirendil — 由 Anthropic 负责 AI 科研相关团队的 Behnam Neyshabur 和 Harsh Mehta 等人创立,“用 AI 自动化AI研究”,6 月 25日官宣,估值 10 亿美元。 Core Automation — 由前 OpenAI 研究VP Jerry Tworek 创立,打造自动化程度最高的 AI 实验室,探索超越预训练和 Transformer 架构的新方法。 Dream Labs — 由Nvidia GEAR Lab的研究员 Joe Jang 创立,主导过DreamGen、DreamZero、DreamDojo 等机器人世界模型研究。 Applied Compute — 由前 OpenAI 研究员 Yash Patil、Rhythm Garg、Linden Li 创立,主营“后训练即服务”,帮企业在开源模型基础上训练专属模型。 Fireworks(AI) — 模型托管与推理服务平台,创始人兼CEO Lin Qiao 曾是 Meta PyTorch 团队负责人。 Harvey — 法律AI公司,本季度先后与 Applied Compute、Fireworks 合作,在 GLM-5.1 等开源模型基础上训练法律agent,在自家 Legal Agent Benchmark 上超过了 Anthropic 和 OpenAI 的模型。 Windsurf — Cursor 曾经的直接竞品,2025 年被 Google 支付约 24 亿美元获得核心团队与技术授权(不是整体收购),后来做出了Google Antigravity 这款 agent IDE。 Devin(Cognition)— 做AI软件工程师agent的公司,除了卖工具,也直接卖服务。 Palo Alto Networks — 网络安全公司,与 Anthropic 有安全领域的深度合作(Project Glasswing),其 CEO 本季度在X上公开呼吁Anthropic给Claude降价。 其它人物: Boris Cherny、Cat(Catherine)Wu — Anthropic Claude Code的核心工程与产品负责人,两人在X上都有大量关注者,是 Claude Code 声量的重要来源。 Aditya Ramesh — OpenAI 机器人团队负责人,此前领导过 Sora 和 DALL-E 的研发。 Noam Shazeer — Transformer 论文(Attention Is All You Need)八位作者之一,2026 年 6 月从 Google(时任Gemini 联合负责人)跳槽到 OpenAI。 技术/行业术语: 本期中提到的一系列 Benchmark:SWE-bench Pro、Terminal-bench、Agents' Last Exam、OS World 分别衡量编程能力、终端里多步骤且需要用工具的任务能力、综合 agent 能力,以及computer use(电脑操作)能力。 Harness — AI agent 运行时的“脚手架”,决定它怎么调用工具、怎么组织多步任务,不是模型本身,但直接影响实际表现。 FDE(Forward Deployed Engineer,前向部署工程师) — 派驻到客户现场、帮企业把AI能力落地到具体业务里的工程师,近期很热门的岗位。 VAD(Voice Activity Detection,语音活动检测) — 判断说话人是否停顿、该轮到谁说话的技术,目前大多数"实时语音"AI靠这个模拟对话感,本质还是轮流说话的"对讲机"模式。 Token maximalism — 2026年一季度企业鼓励员工尽量多用AI token的一波风潮,后来因为投入产出不成比例,逐渐降温、被用量配额取代。 MCI — Meta 内部一个通过在员工电脑上装软件、录制操作过程来训练 AI 的项目,因隐私争议和数据泄露被叫停。 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →
170: 【具身季报 26Q2】世界模型大风不停,和不想被贴标签的人
3w ago01:53:50Tap to summarize「人形马拉松、Figure AI 直播、中国灵巧手亮相 ICRA、英伟达Cosomos3 & 世界模型投资热、Generalist 和 Pi 的模型进展。」 这期是《晚点聊》「具身季报」系列第二期,我继续邀请风投机构 Alphaist 的创始合伙人陈哲,来和我们分享最新的具身智能动态和趋势。 本期节目也会在 Alphaist 的播客《The Alphaist》 串台播出。 本期季报,依然按 TOP 5 进展和事件展开,包括: 人形机器人马拉松:荣耀夺冠的更多意味 Figure 的 200 小时直播:物流为什么是人形机器人好场景? 灵巧手和灵巧操作:谁是手中 G1? 英伟达的世界模型 Cosmos 3 和世界模型创投热 全球领先的具身模型进展: GEN-1 和 π 0.7。 我们也延展讨论了一些资本市场的变化、新玩家进入——OpenAI 的 Robotics team 官宣——和行业落地 vs 推进智能的节奏与取舍。 图注:英伟达对“robotics”领域世界模型的分类。 图注:Figure AI 直播截图,机器人要处理的任务是在流水线上快速地翻转包裹,让二维码一面朝上。 本期节目的图文版也已经发布:具身季报 26Q2:世界模型大风不停,和不想被贴标签的人 本期嘉宾:陈哲,Alphaist Partners 创始合伙人 本期主播:程曼祺,晚点科技报道负责人 剪辑:甜食 时间线: 02:54 -Q2 Top 5 总览 07:17 -人形马拉松,荣耀夺冠、大厂加码的先声 -Figure 连续直播 14:56 物流,为何是人形机器人的好场景? 21:19 遥操从不是争议点,是真实部署时的必要模块 25:24 星动纪元合作中国邮政,总结过往 to B 机器人的场景选择 28:55 数采范式的 3 次变化 -灵巧手和灵巧操作 34:48 ICRA 最大亮点:舞肌等中国高自由度灵巧手 43:03 灵巧操作:Demo 很惊艳,技术在早期 53:32 再论直驱和绳驱:大厂继续跟绳驱(Optimus),长期仍看好直驱 -世界模型 01:02:57 英伟达 Cosmos 3:从生成视频到直接生成动作 01:08:51 具身的世界模型分类:3 个相交圆 01:14:04 世界模型投资热:大模型教会投资人的事,追逐智能 -Gen-1、π0.7 和不在标签里的公司 01:19:55 π0.7:VLA 融合轻量世界模型 01:22:46 Gen-1:从头预训练,不被路线定义 01:28:40 Google 发布 ER1.6,OpenAI Robotics 团队官宣 -更多讨论 01:37:56 智能部分是否赢家通吃?Omni 模型是个变量 01:42:46 “对长期不确定性探索的容忍度依然差” 01:47:50 -下季度展望:终端大厂加快入场 相关链接: 157 期:【具身季报 26Q1】宇树招股书、人形再思考、英伟达世界模型、高自由度灵巧手 上次季报至今,我们在具身智能、物理 AI 方向的访谈: 166 期:许华哲再次具身创业:不想错过最大的西瓜 165 期:GEAR 高深远:世界模型、自进化循环、DreamDojo 161 期:原力灵机唐文斌:中国最早的 AI 创业者和他的具身新旅程 160 期:群核IPO后与黄晓煌聊这15年:被嫌弃的GPU、冠军酷家乐、空间智能、六小龙 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →
169: 访谈Cerebras早期投资人周楠:英伟达挑战者?Scaling Law的萌芽、被遗忘的百度美研
Jun 1601:39:15Tap to summarize「一段鲜少被人提及的故事。」 今天的嘉宾是目前任职于高通创投(Qualcomm Ventrues)的投资人周楠。她是 5 月中旬 IPO 的 Cerebras Systems 的早期投资人之一。这是一家提供新架构 AI 算力的芯片与系统公司,被外界视作英伟达的补充,甚至是挑战者。 9 年前完成这笔投资时,周楠刚从投行加入百度的硅谷人工智能实验室。那时吴恩达是百度人工智能业务负责人,Anthropic 的创始人 Dario 也曾在百度美研工作,期间作为一作发表了 DeepSpeech2: End-to-End Speech Recognition in English and Mandarin 一文。 今天这期节目,我们从 Cerebras 的 IPO 切入,聊了 AI 算力的趋势,也通过回顾这段投资过程,回到了 10 年前,scaling law 在硅谷萌芽的阶段和当时百度美研的状态。 那是一段现在的地缘环境下,鲜少被人提及的故事,但它值得在 AI 历史中有一席之地。 本期节目的图文版也已经发布:从 Cerebras IPO 聊起:AI 算力变化、Scaling law 的萌芽和百度美研往事 本期嘉宾:周楠(Nan Zhou),Qualcomm Ventures 投资人 本期主播:程曼祺 《晚点 LatePost》科技报道负责人 时间线跳转: -Cerebras IPO,英伟达之外的 AI 算力 03:26 Cerebras 离“英伟达挑战者”还有多远? 11:16 从 Sam Altman 最早投 Cerebras 到如今与 OpenAI 的 200 亿美元订单 18:27 Cerebras 的上限与下限,WSE 架构优劣 -9 年前的那笔非共识投资 23:28 为什么百度当时要投芯片? 29:02 Dario Amodei 的早期代表作 DeepSpeech 2,Scaling laws 的萌芽 32:17 Cerebras, Graphcore, Wave Computing,三选一 37:06 与研究员一起做尽调,逐一排查风险点 46:18 IC 投决过程,未流片前的决策 53:35 Cerebras 的至暗两年,如何挺过流片不顺 -“遗落”的百度美研 01:00:02 “黄埔军校”和一份生不逢时的 deal list 01:04:04 OpenAI 和 Anthropic 早期都未得典型 VC 支持 01:09:04 他们后来为什么离开百度? 01:12:23 起了大早,赶了晚集,一部分是“宿命” -新的非共识 01:18:30 推理优化和 Infra 的更多创新 01:26:11 真正的早期投资变难,一股趋势是募大钱投显然的 winner 01:31:11 物理 AI,下一阶段的大分歧和机会 **01:35:49 连点成线* 剪辑:甜食 相关链接: 《晚点聊》159 期:马斯克Terafab太空算力、英伟达重拾CPU|与Fusion Fund张璐聊AI算力新趋势 《晚点聊》156 期:【AI季报_26Q1】:OpenClaw、OpenAI vs Anthropic的三重对阵、自进化 附录:一些术语解释 WSE(Wafer Scale Engine,晶圆级引擎):由 Cerebras 公司推出,是将整片晶圆封装为单一芯片的超大算力处理器。 ASIC:专用集成电路,专为特定功能定制设计的芯片。 模拟验证:通过仿真测试电路功能、性能,排查设计缺陷的芯片研发环节。 流片:把芯片设计版图交由晶圆厂,正式量产制造芯片的过程。(本期聊到,百度当时投资 Cerebras 时,Cerebras 尚未完成第一次流片,处于模拟验证的研发阶段。百度对 Cerebras 的性能尽调也是基于模拟推测的。) Adept AI:曾推出 Devin 的美国创业公司,核心成员 Erich Elsen 曾在百度工作。 Egien AI:本期后面聊到的,被 Nebius 收购的一家 Infra 公司。 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →
168: 对话王新宇:美团龙珠怎么投科技?
Jun 1002:07:27Tap to summarize“具身的泡沫什么时候破?” 王新宇的答案却是:中国投入这个领域的钱不是太多,而是太少。 他是美团龙珠的合伙人,十年前入行时就在投科技,先后在 GGV、昆仑万维战投部工作,2021 年加入美团龙珠,开始负责科技投资。 整个美团系——包括美团战投和美团龙珠——现在是宇树最大的外部股东,累计投资宇树超 4 亿元,合计占股约 9.65%。其中,美团战投持股 7.61%,是宇树科技的早期战略投资者;美团龙珠随后投资,目前持股 2.04%。 宇树刚刚在上周完成科创板 IPO 过会,这成为龙珠科技投资不可忽视的一笔。 王新宇也在 2023 年 7 月的早期阶段就投了月之暗面,这是龙珠重注的一家大模型创业公司。龙珠先后投资月暗 4 轮,并领投了 200 亿美元估值的最新一轮。 从王兴兴到杨植麟,王新宇反复看到一种新的创业范式:由热爱驱动的创业——热爱带来极致的专注和力争世界第一的雄心。他也看到了一类反复出现创业者——“年轻的大哥”:他们实际年龄小,但在某个领域已深耕多年。 本次采访,我们回顾了王新宇十年科技投资的思考和故事和龙珠的科技投资布局。 本期节目的图文版也已经发布:从王兴兴到杨植麟,美团龙珠怎么投科技? 本期嘉宾:王新宇,美团龙珠合伙人 本期主播:程曼祺,《晚点 LatePost》科技报道负责人 剪辑:吴宇量 时间线跳转: -GGV、昆仑万维:“我能不能吃投资这碗饭?” 01:31 2008 级 5023,“复旦最牛宿舍” 11:37 计算机视觉背景,为何没投 CV 四小龙? 17:05 离开大机构,验证自己能否长期做投资 -美团龙珠:三纵三横里的科技机会 23:37 理想汽车是一笔传奇投资,王兴有不灭的好奇心 33:20 龙珠的“三纵三横”科技推演 38:08 2023 年 7 月投资月之暗面,“见面后,杨植麟打消了我的一切负面疑问” 47:10 DeepSeek 冲击,“人教人教不会,事教人一次就会” 51:27 已投十余家 AI 应用公司,创始人出生高峰是 1997 年 -投入具身智能的钱不是太多,而是太少 01:01:08 2023 年底之后,看懂了宇树,也看到了具身智能大概率会发生 01:11:15 具身智能的链主不一定自己造本体 01:12:47 谈“泡沫”:投入具身的钱不是太多,而是太少 01:19:37 怎么定义具身智能的 GPT-3.5 时刻? 01:28:38 类比自动驾驶,为什么 2019 年是个拐点? 01:33:02 十年前的王兴兴,十年前的宇树 01:43:55 具身市场推演:集中度、产业链分工 01:54:19 语言模型和具身智能之外 02:01:26 一个思想游戏:如果 AI 今天被质子锁死,然后呢? 相关链接: 《晚点聊》 148 期:它石智航陈亦伦:具身的三道曙光和第一道关卡 《晚点聊》 145 期:极壳孙宽:首个「消费级外骨骼」的诞生 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →
167: 洋葱学园杨临风:用AI制造捷径,是在杀死真学习
May 2801:44:31Tap to summarize「AI 来了,学习这件事会怎么变」 本期嘉宾是洋葱学园联合创始人和 CEO 杨临风,而他一直不怎么追风。 在哈佛读本科时,杨临风修的是计算机,而毕业后,他和朱若辰、李诺在 2013 年创立洋葱学园,做了教育科技,想让更多学生驾驭自主学习。 几年后在线教育融资汹涌,最火的形式是双师直播课、名师录播课等,而洋葱学园都没有做,他们不想做培训,继续用 5~8 分钟的动画内容吸引孩子课外自学。 今天我们聊 AI,临风也不怎么讲流行技术词汇,更多聊学习本身。 与其说洋葱是一家教育公司,它更像一家学习公司。他们一直在研究孩子可以如何自发、自主地学习。这在今天变得更重要了。也可以说,AI 正加速让学习回归本来面目。 本期节目由洋葱学园支持播出。 本期嘉宾: 杨临风,洋葱学园联合创始人 & CEO 本期主播: 程曼祺,晚点 LatePost 科技报道负责人 时间线跳转: -从公益到创业,追求实现“自主学习” 02:32 哈佛支教、阳光书屋 08:58 自主学习是意愿、能力和工具的协同 16:04 为什么数学?为什么 5~8 分钟动画 28:23 AI 能提升制作教育内容的效率,但提升有限 -在线教育最疯狂的那几年 39:13 不做双师大班课,不追风口 48:30 就算没有双减,双师大班也很难满足教育新需求 -AI 热潮之后 52:51 洋葱、猿辅导、与爱为舞……AI 教育的不同思路 01:05:45 AI 动摇应试教育,但学知识的过程依然必要,学校依然必要 01:11:00 K12 最重要目标:学会自立 01:15:52 各家大模型在教育场景的表现 -回归自主学习 01:18:14 曾经受到的最大质疑:自主学习只适合少数人? 01:28:38 过去相信先赚钱再实现目标,后来发现不必如此 01:33:55 创业不是开不开心的问题 连点成线 相关链接: 108 期:与马毅聊智能史:“DNA是最早的大模型”,智能的本质是减熵 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →
166: 许华哲再次具身创业:不想错过最大的西瓜
May 2502:25:40Tap to summarize「回到智能,进入家庭。」 从 2026 年 3 月开始,许华哲有了一个新身份:破壳机器人的创始人。之前的两年多里,许华哲是星海图的联创和首席科学家。 这次重新创业,许华哲想自己主导推动一个大梦想:通用机器人,第一步就是家庭机器人。 他也想跳出此前中国具身智能行业的一些路径依赖,更回归通用智能的探索:他说具身智能不是 robotics、不是自动驾驶,也不是“史前深度学习”。 这并不是现在最流行的叙事,他是怎么想的?破壳会怎么做? 本期节目的图文版也已经发布:对许华哲:具身智能不是机器人学,不是自动驾驶,是世界上的新物种 本期嘉宾:许华哲,破壳机器人创始人 & CEO 本期主播:程曼祺,晚点科技报道负责人 时间线跳转: -科学家创业,不好吗? 01:56 离开星海图,看到家庭机器人 17:02 再次创业的信号与 concern 26:27 “学习好”对创业前所未有地重要 -再次出发的 bet 41:11 不是 Robotics,不是自动驾驶,也不是史前深度学习 56:46 强化学习可能被低估了 01:06:06 “不要小瞧投资人的梦想” 01:10:14 18~24 个月后会?重资源竞争、大公司入场 01:16:32 最好的会在中国发生,但别错过最大的西瓜 -技术之美:简单的、一致的 01:29:18 从游戏到物理世界 01:35:56 大多数科研是“噪音” 01:51:49 技术之美:简单的、一致的 01:57:26 具身智能的“时间检验奖”还没出现 02:08:48 一场尽力的马拉松 02:18:29 创业后,找回曾经的自己 02:23:55 连点成线 剪辑:宇亮、Nick 相关链接,《晚点聊》的往期具身智能创业者访谈: 86 期:国家从无到有,拢共分几步?|工业化之路 01 161 期:原力灵机唐文斌:中国最早的 AI 创业者和他的具身新旅程 155 期:至简动力贾鹏:从英伟达到理想,具身智能的六边形战士 152 期:访谈千寻创始人韩峰涛:20 亿新融资、具身模型淘汰赛、落地非共识 148 期:它石智航陈亦伦:具身的三道曙光和第一道关卡 112 期:与千寻高阳聊具身:一个像机器人的人,怎么做像人的机器人 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →165: GEAR 高深远:世界模型、自进化循环、DreamDojo
May 1801:49:03Tap to summarize本期《晚点聊》,我与刚从港科大博士毕业的一位年轻研究者高深远,他从去年开始在英伟达实习,接下来马上会正式加入英伟达的具身智能实验室 GEAR。 我们聊了深远 2024 年以来一直专注的方向:世界模型。 前 1 个多小时,我们展开了整个世界模型的大图景:它的分类?它是为了解决什么问题?它的现状、瓶颈和未来方向,以及各主要公司的思路。 很多人认为世界模型的说法太模糊、涵盖太多,这是一些早期技术的常见现象,这期正好厘清,目前有哪些做世界模型的方法和思路。 后一部分,我们聊了GearLab 在世界模型上的一些实践。尤其是去年底至今,他们陆续发布的世界模型 DreamDojo,(深远是这个工作的联合一作)以及被认为有可能会取代 VLA 的世界动作模型 DreamZero 的研发历程和具体创新点。也延展聊了世界模型可能的竞争局面。 深远描绘了他认为非常有前景的一种自进化循环——它由世界模型、策略模型(如 VLA、WAM 等)和连接二者的 Agent 构成。在英伟达,世界模型和策略模型有 DreamDojo-DreamZero 的组合,在 DeepMind 有 Genie-SIMA的组合。以下的图示更容易帮助理解播客里的讨论。 图注:图中大脑代表 agent,机器人代表 policy,地球代表世界模型,中间是数据集。世界模型的输出(对世界下一刻的预测)是 agent 的输入,供 agent 给预测打分,打分可用以优化 policy;同时世界模型的输出也是 policy 的输入,而 policy 的输出(动作)是世界模型的输入。同时,agent 也给 policy 做任务规划。 世界模型到 agent 和 policy 是用视频/图像通信;policy 到世界模型是用 action 通信;agent 到 policy 是用文本通信;agent 优化 policy 可以是一个打分数值,也可以是由文本媒介转过来的一种分数信号。 本期节目的图文版也已经发布:与英伟达 GEAR 高深远聊世界模型、自进化循环和 DreamDojo 本期嘉宾:高深远,英伟达 GEAR 研究员 本期主播:程曼祺,《晚点 LatePost》科技报道负责人 剪辑:Nick、甜食 时间线跳转: - 世界模型大图景 02:19 世界模型是什么? 施加动作,预测世界下一刻的状态 05:35 多 Agent(车/机器人)互联的世界模型 09:57 按世界状态的表征方式分类: 4 种世界模型 15:33 最看好 video 世界模型, 因为数据够丰富 19:36 世界模型为何热起来? 数据增多 + 策略模型变强了 - 世界模型、策略模型和 Agent 的自进化循环 21:42 策略是什么?和世界模型的关系 23:39 WAM(DreamZero)相比 VLM 的变化 28:26 世界模型的一大价值是服务策略: 测评、生成数据、突破物理限制的虚拟强化学习 33:42 循环三要素: 世界模型、策略、Agent,它们如何彼此连接、优化 - 世界模型的未来 43:07 当前最大瓶颈,突破泛化: 物理的泛化、动作的泛化 51:49 世界模型难以横评, 难以直观看到不同模型的差别 55:28 各团队的世界模型进展: DeepMind、Nvidia、OpenAI、General Intuition - 从自动驾驶到具身,从 AI Lab 到 GEAR 01:02:44 “在学界继续做自动驾驶世界模型没意思了” 01:06:30 加入 GEAR,DreamDojo 和 DreamZero 的发起 01:14:12 在英伟达构建最大规模 Human Center 数据 01:21:05 跨本体的 Latent action,以后还需要吗? 01:28:41 DreamDojo 的评测: 自建 6 个 benchmark 的逻辑 01:34:50 自己不掌握视频基模,能做出有竞争力的世界模型吗? - 01:45:44 连点成线 相关链接: 157 期:【具身季报 26Q1】宇树招股书、人形再思考、英伟达世界模型、高自由度灵巧手 150 期:【年末AI回顾】从模型到应用、从技术到商战,拽住洪流中的意义之线|Solo 148 期:它石智航陈亦伦:具身的三道曙光和第一道关卡 附录:一些名词解释 - 级联误差,Cascade Error:指在包含多个串联模块或阶段的系统中,前一阶段产生的误差未被纠正,直接传递给下一阶段,误差被放大。 - Genie(Generative Interactive Environments):DeepMind 团队发布的基础世界模型。它能通过一张图或一段文字描述生成一个动作可控的虚拟世界。目前发布到 Genie 3 - SIMA(Scalable Instructable Multiworld Agent):DeepMind团队开发的虚拟角色策略模型(DeepMind 称其为 Agent),能理解玩家用自然语言下达的指令(如“向左转”、“拿起斧头”),在 Genie 等各种虚拟环境中操控角色执行任务(产生动作)。 -** Intuition**:一家希望打造空间智能的美国创业公司。 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →164: 当AI“杀死”SaaS,与明略吴明辉聊多Agent网络、软件业转型和 AI 新组织
May 1402:28:58Tap to summarize「闭源软件价值消失,从 token 和模型上赚钱。」 今天的嘉宾是明略科技创始人吴明辉。2004 年时,他就在北大计算机系做人工智能研究,硕士期间开始创业。 在这一轮大模型热潮前,明略曾在 2020 年尝试用 AI 做组织智能,大举扩张,包括收购了 Manus 创始人肖宏的上一家创业公司,夜莺科技。这一次 AI 尝试以失败告终。 这没有影响吴明辉现在对 AI 的热情。24 年以来,明略陆续发布了自己的行业模型,完成了上市。在 OpenClaw 引起个人 Agent 热潮后,他们也开始了一场更彻底的变革。 这一期我们聊了 AI 怎么影响 SaaS 和软件,明略做出的应对,他们即将开源发布的多 Agent 协同网络章鱼,以及一个存在已久的组织可以怎么被 AI 改变。 本期节目的图文版也已经发布:对话明略吴明辉:AI 正在杀死 SaaS,但我找到了一条新路 本期嘉宾 吴明辉 明略科技创始人 本期主播 程曼祺 《晚点》科技报道负责人 时间线跳转: SaaS 已死,软件系统本身会走向开源 01:42 Agent 正杀死 SaaS 已死,数据和上下文的价值更大了 05:53 OpenClaw 开启的新可能:穷人版(不从基模入手的)持续学习 11:53 明略的主业数据挖掘和分析,如何被 AI 改变 19:51 新探索:Agentic Service。软件开源、自训模型赚 Token。 多 Agent 协同网络,“龙虾哲学” 29:15 章鱼想构建集体学习网络, (eˣ)' = eˣ 的指数级增长要给自己造工具 35:51 章鱼开发过程:小团队+AI,核心改造是:认人+权限+信任机制 + 品鉴信号 46:23 龙虾的哲学:康德的义务论约束不了人,但可以约束龙虾 56:30 vs 巨头:章鱼直接开源,“飞书做 AI 转型,也得开源” 01:05:51 自研 GUI-VLA 模型,最大场景是软件自动测试 01:14:35 vs 更小初创企业:1800 人的明略会变得更像“投资公司” 从 Scaling up 到 Scaling Out:站在"被AI欺负的人"那边 01:20:33 scaling up 是追求单性能突破,scaling out 是横向扩展 agent 网络;后者对人的价值更友好 01:26:37 专注行业小型模型,将开源web retriever数据集;Agent 网络可实现个性化持续学习 01:34:19 验证标准:商业成功+ 科学发现能力;风险是“物理猝死”,大脑太活跃 5 年前做 EIP(企业智能平台), 失败的教训 01:37:47 技术判断太乐观,团队共识不够: 01:45:29 1000 多人大团队,"八方神仙"做一个没人懂的产品 01:55:23 从春风得意到减半裁员:看到人的存在;所以现在不裁员,给每个人 AI 船票 01:58:58 希望本身产生力量,尤其是众人的希望 02:03:29 新的 AI 投入何时表现在财务上? AI 原生一代 02:08:11 看女儿用 AI:AI 原生一代的观察与启发 02:11:37 不再和孩子一起刷奥数题,识别 beautiful 的题才做 02:15:14 没有危险的专业,而是只会 Think 是危险的 02:18:43 工程师的新价值:在不断变化的应用环境里判断需求,这仍是 AI 无法做的 02:24:29 Scaling Out一定会发生:小公司会先做出来 连点成线:Coding is eating the world,从软件重塑世界到代码重塑世界 剪辑:Nick 相关链接: 156期:AI季报26Q1:OpenClaw、OpenAI vs Anthropic的三重对阵、自进化 151期:MuleRun 陈宇森:Claude Code 带来 Agent 创作新范式、未来的软件是日抛式的 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →
163: 详解DeepSeekV4:Infra巨鲸、百万上下文走进现实、极致效率优化
Apr 3001:33:52Tap to summarize「走进不同团队的成果,创新从来是连续的,不是跳跃的。」 上周五,DeepSeek V4 发布。我们邀请了两位一线 AI 从业者一起详解 DeepSeek V4 的技术实现和创新想法。 如果一句话概括:DeepSeek V4 并没有带来新的“范式变化”,它是继续在 R1 的“测试时扩展”范式下,用一系列组合创新和工程优化,让百万上下文从理论进入实用。 超长上下文上的稳定表现,正是 Agent 和多步复杂任务亟需的能力之一。 本期涉及的诸多技术术语见 Shownotes 末尾注释。 本期节目的图文版也已经发布:详解 DeepSeek V4:Infra 巨鲸 “四连击”,百万上下文走进现实 本期嘉宾 赵晨阳,RadixArk 工程师,SGLang 开源推理框架开发者 刘益枫,UCLA 博士生 本期主播 程曼祺,晚点科技报道负责人 时间线: 体感、对比、消失的成本、DeepSeek 的节奏 03:01 编程能力与“御三家”有差距;不再采用 DeepSeek 自己提出的 MLA 07:44 不再披露训练成本,“用模型能力说话” 09:23 延期推测:四个耦合的新 feature (新注意力+Muon+mHC+FP4)一起上,难度爆炸 12:36 不是范式创新,沿现有范式仍有巨大提升空间 性能与效率 14:32 提出新的能力方向比刷单个 benchmark 重要 16:41 坦诚的内部评测:9% DeepSeek 工程师不会把V4 Pro 作为编程首选 23:03 单 token 推理的计算量和 KV cache 大幅优化,但解决同样问题的 token 消耗更多了 V4 具体进展 28:32 整体思路:极致的稀疏 33:45 混合稀疏注意力:放弃 MLA,SWA滑动窗口+CSA稀疏压缩+HCA稠密压缩,层间预定义分工 39:37 Muon 优化器已成检验工程能力试金石 48:52 mHC:从 Seed 提出 HC 到 mHC;Kimi 的 Attention Residuals 54:24 Infra 两个关键词:TileLang & FP4 01:10:11 多专家训练+蒸馏的后训练 01:13:20 评测危机:benchmark会过时饱和,evaluation是永恒追求,agent评估未共识 更多讨论 01:19:25 近期模型共性:架构趋同(MOE+Muon),优化方向驱动(agent、coding) 01:25:18 美国追新能力、高定价;中国追性价比、工程极限 01:28:00 V4 最有可能被记住的思想:极致压缩+低激活比+低单token成本,成为后续开源模型起点 剪辑:Nick 相关链接: 158期:V4发布前的DeepSeek:人才竞争、组织特点和独特的AGI目标 143期:再聊 Attention:阿里、Kimi 都在用的 DeltaNet 和线性注意力新改进 104期:我给线性注意力找“金主”,字节 say No,MiniMax say Yes 103期:用Attention串起大模型优化史,详解DeepSeek、Kimi最新注意力机制改进 102期:DeepSeek 启动开源周,大模型开源到底在开什么? 附录:术语、概念解释 - 模型架构相关 Token-wise(词元级)改进:优化模型处理单 token 的过程,通常用于提升注意力计算、上下文建模或推理效率。 Layer-wise 的改进:优化模型不同网络层的结构或计算方式,通常用于提升训练稳定性、表达能力或整体计算效率。 MoE:Mixture of Experts 混合专家网络,让不同“专家”子网络处理不同输入,降低单次计算成本。 哈希路由:把 token、样本或请求分配到不同专家、节点或存储位置的方法。V4 在前几层 MoE 用了哈希路由,避免起始层路由塌缩。 Engram:DeepSeek 之前提出的一种带 N-gram 编码器的辅助模块,通过额外编码连续 token 片段,帮助模型利用局部短语级信息。V4 未使用 Engram。 - 注意力相关 MLA:Multi-head Latent Attention,多头潜在注意力,引入潜在表示压缩 KV 信息的注意力机制,能降低显存占用和计算开销。 MQA:Multi-Query Attention,多查询注意力结构,共享 Key/Value,仅保留多头 Query,提升推理效率并减少 KV cache。 线性注意力:通过核函数或近似方法将注意力复杂度从二次降低为线性(一维),是改进原初注意力随上下文长度增加,计算和显存爆炸的方向之一。 稀疏注意力:仅计算部分 token 间的注意力(而非全连接),改进原初注意力问题的另一主流方向。 滑动窗口注意力:限制注意力仅在局部窗口内计算的一种稀疏注意力。 CSA:Compressed Sparse Attention,压缩稀疏注意力。用于长上下文建模的注意力机制。把序列分组压缩成更少的token,query再从中挑选出最相关的部分。V4中的压缩比是4:1。 HCA:Heavily Compressed Attention,高度压缩注意力。同样用于长上下文建模。相比CSA压缩比例更高(128:1),query无需挑选token。 NSA/DSA:V4发布之前,DeepSeek 在年初和 9 月先后提出的两种稀疏注意力方案。 - 优化器相关 AdamW:一种改进的 Adam 优化器,通过解耦权重衰减(weight decay)提升训练稳定性和泛化能力。 Muon:一种面向大模型训练的优化算法,通过改进梯度更新或内存效率来提升训练性能。 Learning Rate:学习率,控制模型参数每次更新步长的超参数,对训练稳定性和收敛速度至关重要。 牛顿-舒尔茨迭代:一种用于矩阵归一化或求逆的数值迭代方法。Muon 作者 Jordan 提到通常使用 5 次迭代,V4 中采用了 10 次迭代。 - 残差相关 HC:Hidden/Highway Connection,一类改进残差连接的信息通路设计,用于增强信息传递或控制梯度流。 mHC:Manifold-Constrained Hyper-Connections 流形约束超连。DeepSeek 在 HC 基础上的改造,解决了 HC 在大规模训练时的数值不稳定问题。mHC 使用了双随机矩阵,即每行和、每列和都等于 1 的矩阵,以约束信息流。 Attention Residuals:注意力残差连接,将注意力模块输出与输入相加,用于稳定训练并保留原始信息。 - Infra 相关 矩阵乘法:深度学习中最核心的基础计算操作(如向量与权重相乘)。 Kernel:算子核,指在底层硬件(如 GPU)上执行的高效计算函数,是深度学习算子的实现基础。比如矩阵乘法就要写 Kernel 去实现。 CUDA:英伟达开发的能使用 GPU 的一层软件系统,也指一套语言,本次访谈语境里指编写 GPU 算子 kernel 的语言。 Triton:由 OpenAI 开源,是对 CUDA 的一层抽象,能更简单的写 Kernel。 TileLang:一种面向 AI 高性能算子的 tile 级 DSL / 编译框架,把矩阵乘法、注意力等张量计算映射到 GPU 等硬件上执行,在 Triton 的易用性和 CUDA 的控制力之间取得了较好的平衡。 FP8、FP4、INT4:低精度数值格式,分别用 8 位、4 位浮点和 4 位整数表示模型中的权重或中间数据,用于降低显存和带宽压力、提升训练或推理效率。 FP4 比 FP8 更省显存和带宽,又比 INT4 更保留浮点动态范围,因此更适合复杂训练/采样链路,但收益取决于硬件、缩放策略和 kernel 实现。V4 在 1.6T 参数规模上实现 FP4 训练是个不小的挑战。 小红书@曼祺_火柴Q即刻@曼祺_火柴Q ☆《晚点聊 LateTalk》建立「 播客听友群」啦!☆ 欢迎关注科技、商业大公司动态和创业创新的小伙伴进群交流,第一时间收听新节目。 这里有更多互动,更多话题讨论。欢迎贡献选题 & 推荐嘉宾。 请先添加「晚点」小助手的微信号,备注:“晚点聊”,我们邀请您入群。 关注公众号《晚点 LatePost》和《晚点对话》,阅读更多商业、科技文章:
Transcribe →