
Podcast
Best AI papers explained
Hosted by Enoch H. Kang · EN
Cut through the noise. We curate and break down the most important AI papers so you don’t have to.
98episodes
Episodes
Newest firstAll episodes

Reject, Resample, Repeat: Understanding Parallel Reasoning in Language Model Inference
2d ago00:22:30Tap to summarizeThis research paper investigates Sequential Monte Carlo (SMC) and other particle filtering algorithms as a theoretical framework for improving large language model (LLM) inference. The authors introduce a principled approach to analyze inference-time interventions, such as parallel reasoning and pruning, by utilizing process reward models to steer generation. Their findings establish non-asymptotic guarantees for SMC based on criteria like bounded action-level coverage and divergence between true and approximate reward distributions. To address limitations in standard SMC, they propose SMC with Rejection Sampling (SMC-RS), which maintains high accuracy even when reward models are nearly perfect. Empirically, the study demonstrates that SMC consistently outperforms Best-of-N sampling on complex mathematical reasoning tasks and benchmarks. Ultimately, the work bridges the gap between ad hoc sampling heuristics and rigorous statistical theory to optimize the accuracy-cost tradeoff in AI inference.
Transcribe →
Rethinking the Evaluation of Harness Evolution for Agents
2d ago00:22:30Tap to summarizeThis research paper critically examines automatic harness evolution, a method where AI agents iteratively improve the prompts, tools, and logic used to interact with environments. The authors argue that current evaluations are flawed because they often test evolved harnesses on the same data used for optimization, risking overfitting rather than genuine design improvement. By comparing harness evolution against simpler test-time scaling baselines—such as parallel sampling and sequential refinement—the study finds that evolution does not consistently provide superior results. Furthermore, experiments demonstrate that the performance gains from harness evolution often fail to generalize to new, unseen tasks. The findings suggest that many apparent improvements stem from memorizing task-specific shortcuts rather than distilling reusable engineering principles. Ultimately, the paper calls for more rigorous evaluation protocols that use disjoint search and testing sets to accurately measure the utility of automated agent scaffolds.
Transcribe →
From Reasoning Traces to Reusable Modules: Understanding Compositional Generalization in Language Model Reasoning
3d ago00:18:38Tap to summarizeThis paper studies how post-training pipelines transform large language models into effective reasoners through compositional generalization. The authors propose a hierarchical latent selection model that separates reasoning into atomic skills, such as local operations, and routing mechanisms that dictate how information is composed. Their theory suggests that supervised fine-tuning (SFT) provides the necessary raw materials, while reinforcement learning (RL) identifies and decomposes these elements into reusable modules. Controlled experiments validate that RL enables models to solve novel tasks by recombining learned atoms in ways not seen during training. Ultimately, the study concludes that SFT should focus on broad module coverage while RL should target genuinely new compositions to maximize out-of-distribution performance.
Transcribe →
Position: Interpretability can be actionable
4d ago00:24:42Tap to summarizeThis research paper advocates for actionable interpretability as the primary standard for evaluating how effectively we explain deep learning models. The authors argue that current studies often lack real-world impact because they prioritize theoretical understanding over practical utility and concrete decision-making. To bridge this gap, the text introduces a framework and checklist designed to help researchers move beyond exploratory insights toward measurable interventions. By focusing on five key domains—including surgical interventions and alignment—the paper suggests that interpretability can lead to tangible improvements in model safety and performance. Ultimately, the work calls for a shift in academic incentives to reward findings that enable specific actions by developers and policymakers.
Transcribe →
High-accuracy sampling for diffusion models and log-concave distributions
5d ago00:22:29Tap to summarizeThis paper introduces a new algorithm called first-order rejection sampling (FORS) to achieve high-accuracy sampling for diffusion models and log-concave distributions. By utilizing only score estimates (the gradient of the log-density) rather than density evaluations, the researchers provide a method that converges exponentially fast, requiring only polylogarithmic steps relative to the target error. This represents an exponential improvement over previous sampling techniques that typically scaled polynomially. The authors demonstrate that their approach is robust under minimal data assumptions, with complexity primarily determined by the intrinsic dimension of the data. Furthermore, the framework successfully addresses the log-concave sampling problem, matching state-of-the-art performance without needing complex density-based filters.
Transcribe →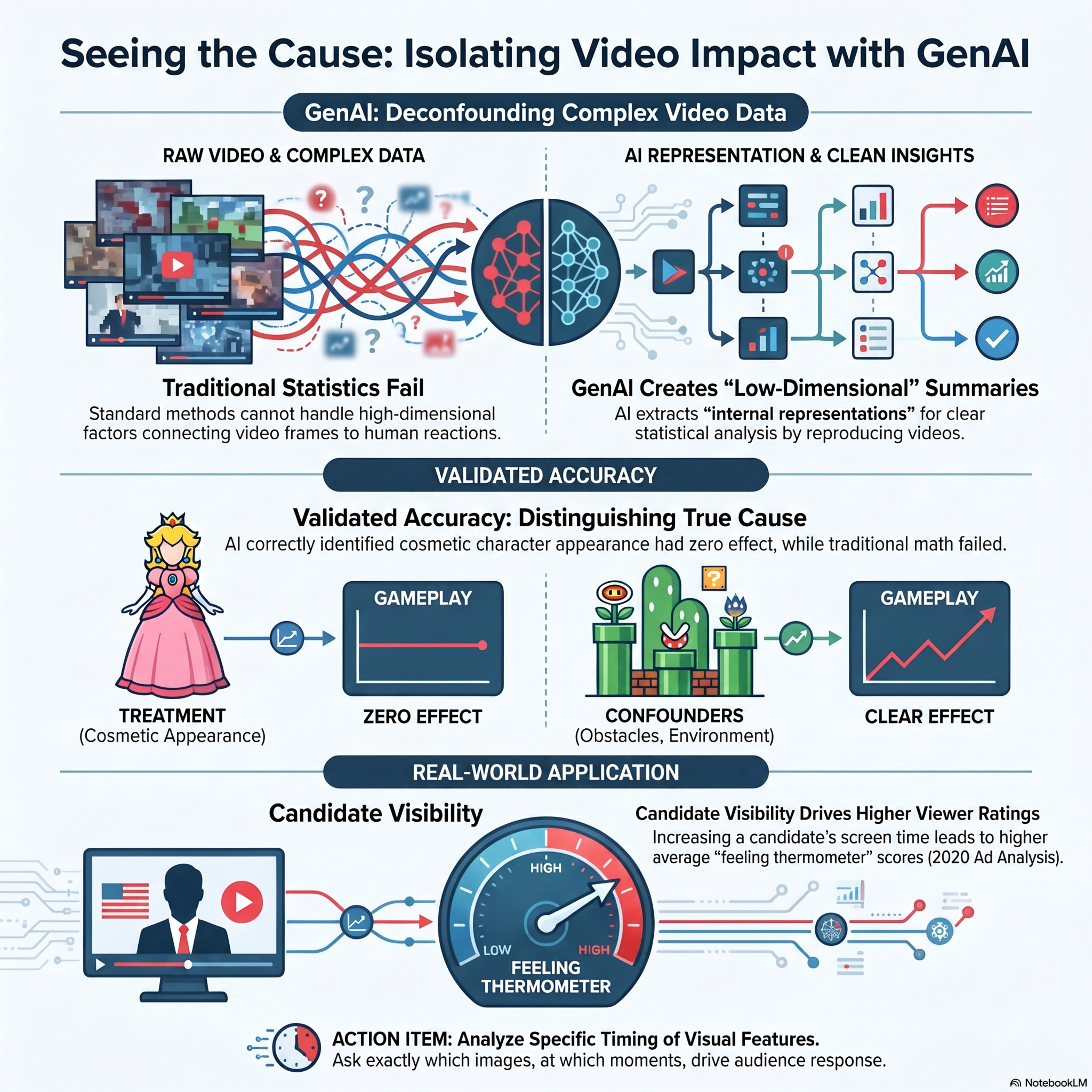
Causal Inference with Video Features as Treatments
6d ago00:22:13Tap to summarizehis research paper introduces a novel statistical framework for conducting causal inference using video features as treatments, a significant advancement for analyzing high-dimensional, unstructured data. To overcome the challenges of latent and dynamic confounding, the authors utilize deep generative artificial intelligence to extract low-dimensional internal representations that serve as summaries of video content. They propose a consistent and asymptotically normal estimator based on a longitudinal neural network architecture, allowing for the identification of potential-outcome trajectories under dynamic stochastic interventions. The methodology is empirically validated through a Super Mario Bros.™ benchmark with known ground-truth effects and an application to 2020 U.S. presidential campaign advertisements. Their findings demonstrate that increasing the appearance of a candidate in a video segment directly correlates with higher viewer evaluations, providing a robust tool for future social science research.
Transcribe →
What Does Thompson Sampling Optimize?
1w ago00:22:18Tap to summarizeThis research paper investigates the underlying mechanisms of Thompson Sampling, a popular bandit algorithm, by reframing it as an online optimization process. While traditionally viewed as a simple heuristic, the authors prove that Thompson Sampling actually minimizes instantaneous squared regret regularized by a specific measure of residual uncertainty. By comparing this mechanism to a Bellman-optimal benchmark, the study identifies a performance gap caused by Thompson Sampling's failure to account for the "tension" between exploration and exploitation. To address this, the authors propose a principled fix that adaptively shuts down exploration when the leading arm also provides the most information. Ultimately, this framework provides a theoretical compass for improving randomized algorithms by treating policy design as regularizer engineering.
Transcribe →
Globally Convergent Offline Reinforcement Learning with Smoothed Bellman Residual Minimization
1w ago00:12:25Tap to summarizeThis paper introduces **Off-GLADIUS**, a novel algorithm designed for **offline reinforcement learning** that utilizes **Bellman Residual Minimization (BRM)**. While traditional BRM methods often struggle with stability and convergence issues, this research proves that the proposed approach achieves **global optimality** by satisfying a **Polyak–Łojasiewicz (PL) condition**. The authors establish that for linear and sufficiently wide **neural networks**, the algorithm converges linearly to the global optimum despite the non-convex nature of the objective function. This theoretical breakthrough addresses a long-standing open question regarding the convergence guarantees of gradient-based BRM in offline settings. Empirically, the study demonstrates that **Off-GLADIUS** matches or exceeds the performance of established baselines like **Conservative Q-Learning (CQL)** and **OptiDICE** across various control benchmarks. Ultimately, the paper bridges the gap between theoretical stability and practical effectiveness, offering a rigorous framework for learning optimal policies from fixed datasets.
Transcribe →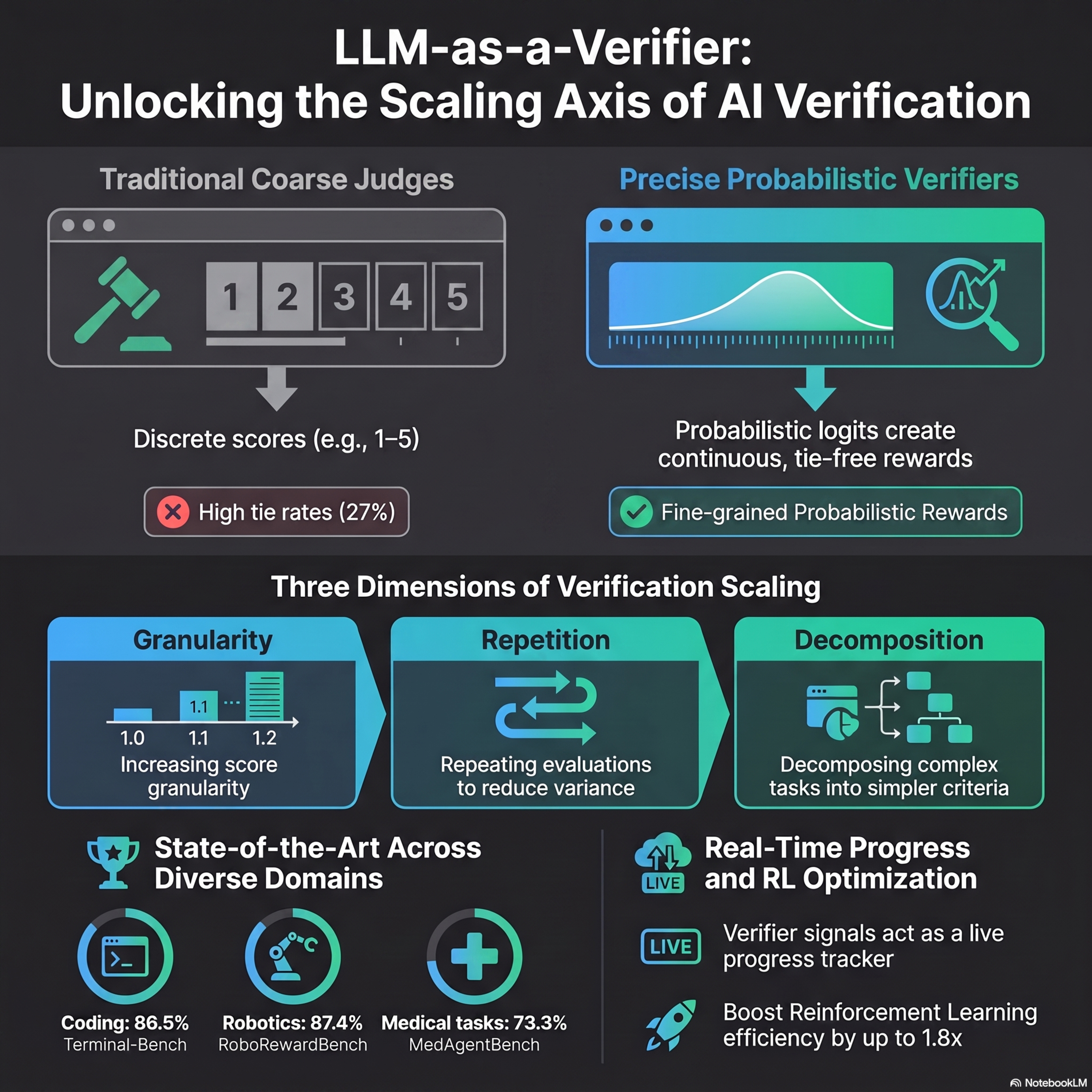
LLM-as-a-Verifier: A General-Purpose Verification Framework
2w ago00:20:02Tap to summarizeResearchers from Stanford, UC Berkeley, and NVIDIA have introduced LLM-as-a-Verifier, a novel framework designed to improve how artificial intelligence evaluates its own work. Unlike traditional methods that use simple pass-fail scores, this system calculates continuous scores by analyzing the underlying probability of specific words within a language model’s output. This approach allows the system to scale its accuracy by increasing score detail, performing multiple evaluations, and breaking complex tasks into simpler parts. The framework has set new records for accuracy in specialized fields like computer programming, robotic control, and medical tasks. Beyond grading results, the technology can track an agent's real-time progress and provide the detailed feedback necessary to train robots more efficiently. Ultimately, the study suggests that refining how models verify information is a critical new path for making autonomous systems more reliable and capable.
Transcribe →
How Much Do Language Models Memorize?
2w ago00:23:52Tap to summarizeThis research paper investigates language model capacity by introducing a new method to measure how much a model truly memorizes versus what it generalizes. The authors distinguish between unintended memorization, which is specific data storage, and generalization, which is the understanding of broader patterns. By testing the GPT family, they determine these models possess a storage capacity of approximately 3.6 bits-per-parameter. The study reveals that the double descent phenomenon occurs specifically when a dataset's size surpasses the model's total bit capacity. Furthermore, the researchers established scaling laws to predict the success of membership inference attacks, which identify if a specific datapoint was used in training. Their findings suggest that modern models are trained on so much data that standard membership inference is increasingly difficult for average samples.
Transcribe →