Loading summary
Transcript89 lines
- [00:00]
A
Foreign. Welcome to the Last Week in AI podcast where you can hear us chat about what's going on with AI. As usual in this episode, we will summarize and discuss some of last week's most interesting AI news. You can also check out our Last Week in AI newsletter at lastweekin AI for even more stuff we are not going to be covering. I am one of your regular hosts, Andrei Karenkov. I studied AI in grad school and now work at the AI startup Astrocade.
- [00:40]
B
And I'm your other co host, Jeremy Harris. You're going to get used to hearing me by now being really sick on these podcasts. Yeah, I got, I got another, another thing. I was joking with Andre where all this talk about AI powered bioweapons and I kind of feel like I am one. So call me ahead of the singularity on this one. But hey everybody, Gladstone AI National Security. You know the, you know the spiel. Thanks for tuning in.
- [01:04]
A
Yeah, I'd like to claim that you missed last week because you were sick. I think you were actually traveling, which maybe is how you got sick.
- [01:11]
B
I, I think you're exactly right.
- [01:13]
A
But as we like to say, we are going to try to keep this weekly, forgive us for the occasional missed week. This week is going to be big. There's a lot to get through so we might have to be quick. Most of it. I think the meat of it is all these model releases. Somehow everyone decided to release new models that are like mindbreaking at the same time. Opus, of course, Codex, Gemini, deepthink, models from the Chinese companies. There's gonna be a lot of model talk in this episode and then we're gonna have actually less news about businessy things than usual and then a bit on more of a researchy side and progress there. So it should be a fun episode. I hope people can get through it because it's going to be pretty dense before we get there. We are going to be starting to once again do sponsor reads. We haven't done this in quite a while, but we get connected up with a professional company that does these things so we can get a little more formal with the whole podcast thing. We are going to have timestamps in the description as always, if you want to go straight to the news. We're also going to respond to some comments, by the way, before we get to the news, but let's kick it off with the sponsor read. Oh, and just to preface, we're going to try to keep the sponsors mostly AI tech related occasionally maybe branch out there, but we'll see. And now one more thing before we get to the news. We do have some listener comments, comments and corrections to respond to and got some new reviews on Apple podcasts. One of them is saying best AI podcast. Almost back at 100%. Yeah, unfortunately.
- [03:10]
B
Compliments. Ah, I love it.
- [03:12]
A
We did have, you know, a couple months here in 2025, towards the end of the year where we were a little bit off. Jeremy, you were busy changing the world, I assume, saving us from, you know, X risk.
- [03:24]
B
Honestly, just, just trying to stay out of the Epstein files. That's been most, most of my, my job. But yes.
- [03:30]
A
Anyway, we appreciate this listener reviewing saying we are delivering nicely thus far in 2016, so we're going to try to keep doing that. In addition, we did get some feedback on the latest episode where things got a little bit political. I did kind of go into my thoughts on on with Trump transformation and things as far as US politics. Just to flag it, we are not going to be getting into politics as a regular thing at all. We're going to keep focusing on AI. We're going to talk about politics as it relates to AI, of course, and that happens quite often. And last week, you know, I had the excuse that people in AI were talking about politics, which is kind of a big deal. But suffice it to say in this episode, back to all AI talk, no politics.
- [04:21]
B
The comments on YouTube and on the Apple podcast, I really enjoyed that this week actually. It was, it was really cool. It felt that, I felt that sense of community. You know, people had different views on, on the politics stuff, of course, but there was also exchanges about all kinds of stuff. It was really cool and that was, at least for me, super motivating. So I, I really appreciate that. And yeah, thanks guys.
- [04:39]
A
Thank you.
- [04:39]
B
Thanks for tuning in and contributing.
- [04:42]
A
And with that being said, let's get into tools and apps, starting off with Opus 4.6. So anthropic has released this about a week ago now. They also released this agent teams features that allows you to split up tasks across multiple agents that all in parallel do work on this. As far as the new model, Opus 4.6 notably has a 1 million token context window as opposed to the 200,000 token video of previous models. We also have an extra fast version of Opus which is like 2.5x speed I think. And all indications are this is actually a pretty decent bump in capabilities compared to Opus 4.5. It's not sort of, you know, next, next level, mind baking, but it looks pretty impressive and the Vibe Check Online has been that Opus 4.6 is even more mindbreaking as far as what you can do with Vibe coding these days.
- [05:49]
B
Yeah, and this is coming with that aging teams capability. Right. Which is a big shift. I mean, this is the parallelization of AI workflows. It mirrors in some ways what we saw in software engineering back in the day when we went from single threaded to multi thread architectures. Really. So you're going, you know, it's more than just speed. Right. It's not just a latency thing. This is being able to decompose a bunch of tasks into parallel workflows and get specialized subagents working on them. So that really can change a lot of what's feasible as long as you have tasks that can be parallelized. There's also, you know, this sort of repositioning thing that's happening where we're seeing Anthropic start to move from the sort of developer tool positioning of Opus to something more like a, like a universal knowledge worker. Right. Like a lot of what this is about is that shift into, you know, like PowerPoint integrations and other things that are more kind of office worker Y. And that's. That positions Opus a little bit less in terms of like a competitor to GitHub Copilot and more with like Microsoft 365 Copilot, which just sort of captures that broader scope. So that's, that's quite interesting, obviously release only. What is it like two, three months after the Opus 4. Five came out? Right. So that's pretty quick. And that suggests just like more competitive pressure we've seen in the space, obviously with the Codecs release and all the other models that have come out. So yeah, this is a really important release. The capabilities of 4.6 are wild. I've played with it a fair bit and what I keep experiencing and what I keep hearing from people who do very different workflows from mine is something has changed in the last three months. You know, we've moved from the impressive demo stage to the. Actually this should be your first port of call for an awful lot of workflows. And that is portentous, probably of some major economic shifts. I mean, this is really, I would say, the moment to call it on. I would expect to start to see some big white collar market shifts in response to these kinds of capabilities because this is now across the Rubicon.
- [07:52]
A
Right. And as you said, Anthropic highlighted in their announcement quite heavily this new side of Opus and Claude, that's meant for more general Knowledge work than just coding. So they have updates to the integration with Excel and PowerPoint for instance and they have actually a whole video showcasing Claude for everyday work. That's looks like an ad which anthropic used to be less of a business business. They used to be, you know, for developers and enterprise, but I think they're, they seem to be trying to expand and get more people and I think with Excel, with PowerPoint, you know, the software world is already completely changed as far as how it works and it seems like that's coming for other sectors too probably this year. Right, next up we've got another really big model release, maybe surprisingly big, with GPT5.3 Codex. So this is the new coding oriented model from OpenAI. It's 25% faster and appears to be a lot better. It like seems to be clawed on the benchmarks, like putting insane numbers honestly as far as just comparing it to previous tiers. And again here, revive check online. And it's hard now when these things come out. People post on Twitter and pretty often it's like this is a whole other level. This is a game changer. I, I don't know who to trust anymore, but I'm a bit surprised in taking aback by seemingly OpenAI really catching up and perhaps even starting to lead in the coding space.
- [09:39]
B
Yeah, I think one of the most important things to highlight for both this and the anthropic releases has been this challenge, at least on the safety and security side of like evals no longer actually tracking reality. This has been a common theme across both. Again, as people have said, look, Apollo, Apollo did their eval on Codex and we're basically. Or no, sorry, I think that was on Claude and they're like look, we can't like this model seems to have so much eval awareness. In other words, it seemed to be so good at telling that it's being evaluated that we have no way to be confident that our evaluations are actually telling us something about the model's tendencies and capabilities. Like it knows it's being evaluated, it knows what these evaluations are for at least can hazard a guess and so it's going to potentially adjust its behavior accordingly. And in fact that is what they tend to see. So similar issue here. This is something that is being called out by OpenAI on the cybersecurity side under the preparedness framework. They're saying this is the first high capability model for cybersecurity that they've ever produced. Which does make sense when you do look at the vibe check I have less experience playing with the new version of Codex than I do with the in the new version of opus. But just between these two models, I mean, like you said, it is so hard to pick a model these days and you'll keep flipping back and forth between them all day long. But it's clear that the Pareto frontier of capabilities is now at the point where yes, evals, especially for safety and security, are just kind of not there anymore, for all kinds of reasons. But also this recursive self improvement thing, we can have a philosophical debate about what that means. And obviously AI has been helping to code itself for some time now, ever since GitHub Copilot came out with your early versions of a GPT 3 and 3.5 as people were starting to use it for basic code autocomplete. There's a sense in which AI has been helping to develop itself, but what's met here is something a lot more sort of explicit. So they, what they were saying is that the Codex team actually used early versions of the model to debug its own training, manage its own deployment and diagnose test results and evaluations. It's somewhat unclear what exactly those things mean, right? Like you can help identify bugs in the training pipeline. But it is fundamentally unclear based on the announcements that have come out so far, what exactly went into that. Until we see a plot of fraction of developer time versus fraction of whatever it would be, I mean developer time equivalence in compute, it's really difficult to tell what it means for the model train itself. No question though. This is like this should not be taken. As Jeremy is saying, this is a nothing burger. Obviously it's not. You can just play with the model yourself. Everything I've said about this is a sea change in the capabilities of these models is true. It's just also true that these claims are really, really hard to measure. Right. We keep saying this about the meter evals. We'll be talking about that a little later today. But it's really difficult. Just like it's hard to evaluate, you know, cyber capabilities and you know, proclivities to be deceptive and scheme. It's also really just hard to measure what it means for an AI to improve itself. All kinds of weird bottlenecks appear that you don't always think about ahead of time. How do you account for the hardware dimension? Like there's a million things. But all we can confidently say is that yes, there is a qualitative difference between what came before and this. And so anyway, this is a very significant development. There is a whole other kind of aspect of this which is the Cerebras partnership. So there was a follow up release of Codex Spark which can pump out a thousand plus tokens per second. And this reflects this kind of collaboration between Cerebras and OpenAI. Where OpenAI is, is looking at a 10 billion partnership with Cerebras to essentially have OpenAI diversify away from Nvidia, which just has owned their stack for so long to try to come up with some alternatives here. And so that's going to be really important. That's them sort of dividing their workloads pretty consciously. Use cases that require really low latency, but not necessarily the very best edge of capabilities. Those are going to go over to Cerebras because they have these really big wafer scale chips that have like super, super fast sort of like, like low memory latency and, and all kinds of properties that we've talked about before. That's why they're using that. Whereas they'll stick with the Nvidia stack for their highest capability models with maybe a little bit of longer latency when. When quality is what matters. But anyway, it's a fascinating series of things all coming together. You can never talk about the capabilities of the software without talking about the hardware. So here we are.
- [14:10]
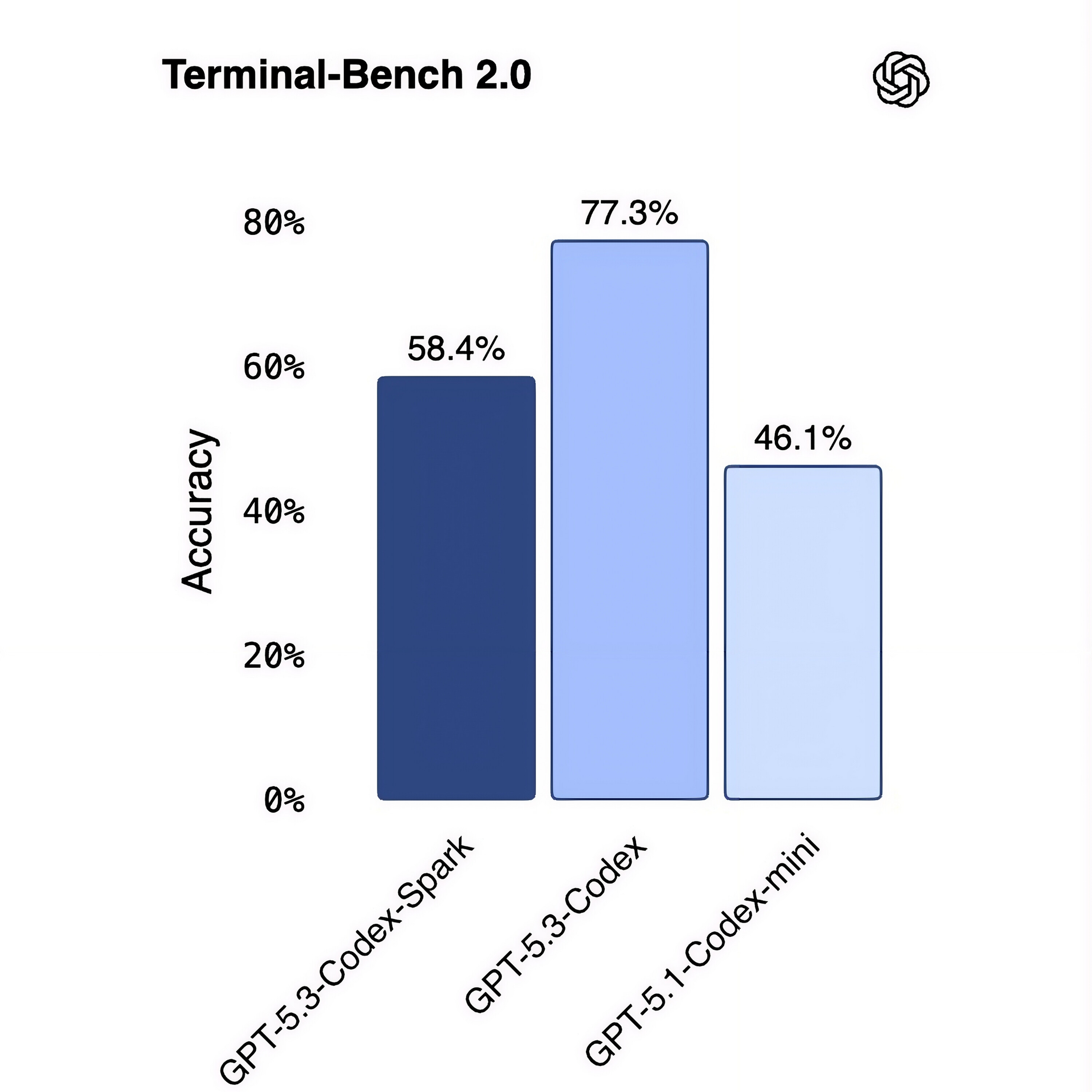
A
Right, And a couple more notes to all that, which there's a lot to go through. Right. So just to give a bit more detail quantitatively with GPT5.2 codecs on terminal Bench, which is now one of the like last ways to evaluate coding and make Progress on coding. GPT 5.2 codecs had 64% performance on that benchmark. Opus 4.6 had 65.4 performance. That's compared to 59.8 from Opus 4.5 Codex 5.3 and this is extra high. This is like max, max reasoning, max token use, et cetera. Got to 77.3 on this benchmark. So it's quite the leap from previous places. Like to give some context, Sonnet 4.5 to Opus 4.5 was 51% to 59%. Like going from 64 to 78 seems like a big deal at least. And on this note of recursive self improvement, I don't think you quite contextualized it in the blog post announcement of Codex 5.3 from OpenAI. They have a whole section how we used Codex to train and deploy GPT 5.3 codecs. Which is why in the discussion of this announcement kind of this notion that the AI helped improve itself and this Is like recursive self improvement was part of a discussion in the blog post. The examples they give is honestly kind of accelerating workflows. Like it didn't augment the intelligence. It helped like analyze things with data scientists. It helped come up with ways to classify issues, helped improve the model harness, like the tooling. In my opinion, this recursive self improvement thing is a nothing burger. Honestly, it's like, okay, you can use it in all sorts of ways to improve productivity and help you do stuff that you already do. It didn't actually help make a smarter model, in my opinion. It helped accelerate with workflows of the researchers, which you can argue what recursive self improvement means. But if you're specifically talking about recursive self improvement in the sense that now the AI can continuously improve itself and we have an intelligence disposition scenario, I don't think this points at that specifically.
- [16:45]
B
Yeah, it is a lot of fuzzy and hard to quantify stuff. I mean, it's like here's a data scientist on the team worked with GPT 5.3 Codex to build new data pipelines and visualize the results much more richly than our standard dashboarding tools enabled. And the results were co analyzed with Codex. So like, yes, absolutely. The thing is, there's also this risk that we're like, oh, it's not really a model that's training itself or like we're not really approaching the singularity until suddenly like you just close the last, the last kind of feedback loop. But I mean, I agree with you, it's so fuzzy. I don't blame OpenAI for this at all. I think it's just genuinely, really, really hard. Like we keep talking about the vibe check. I feel like this last year, every model that's come out, we look at the benchmark scores and like Andre and I look at each other and kind of go like, okay, but what? Like, but what does it feel like? And then we go and play with it or we look at, you know, reviews from other people and that's what, what we really anchor on. That's, that's what we're left with here. The problem is you then get lost in things that are qualitative and can sound like marketing, can be marketing, but can also be true. So I think we're off the edge of the map here. There'd be monsters. It's really difficult to know what models are actually at what point in this whole singularity loop. So yeah, just basically hard to agree with everything you said there.
- [18:02]
A
Yeah. And to be fair, OpenAI didn't position this as recursive slot improvement. They in the blockers position it as codex helped build codecs 5.3. Which is true. Like you do use AI. Anthropic has already stated that and has a similar note actually in the opus 4.6 announcement of the engineers there using it extensively, just across everything. And that's totally true. Like any software company at this point that isn't full on. Using agents all over the place is behind in my opinion. And on the note of Codex Spark, quite a big deal as well. So the speed up here, they say it's at more than 1,000 tokens per second, which is at least a 5x speed up to my knowledge. Like the typical thing is 100 to 200 tokens per second. Opus 4.6 from what I've seen of Anthropic, it actually can be even on the low end of that. So a thousand tokens per second is a qualitative difference. You can look at side by side gifs and videos.
- [19:08]
B
Oh it's instant.
- [19:09]
A
It's like it looks instant. Right. So it's a big deal. And we've seen previous examples of this from Cerebras where you could do open source models that are near instant and we've seen examples and we covered examples of stuff like a thousand tokens per second. But OpenAI making it available is a big deal now because it's Cerebras and because it's like an initial version of this. They do note that there are rate limits specific to this model. It's also limited to Text only and 128 context windows. So there's some trade offs here with using an ultra fast model. I also would wonder if it like performs the same. I don't know if there's architectural implications to deploying it on this different hardware, but yeah, definitely kind of the first shot at this from OpenAI and Cerebral and we're going to see more now.
- [20:06]
B
To your point, there absolutely will be architectural implications to this deployment. Right. Like they're looking to squeeze every bit of performance out of this, this, this hardware. So they'll presumably be doing stuff like just you know, picking, picking their architecture to map onto the hardware and then doing distillation into whatever shape the, the architecture needs to take to kind of Cerebris game as hard as it can. And yeah, I mean we're in that world right now where the distinction between hardware and software is not, you know, know, not at all clear. The things are crazy. I mean these are, these are really, really big plays as well for Cerebras relative to Nvidia. We talked about that $10 billion deal. OpenAI is, is actively, as is the entire industry, desperately looking for options other than Nvidia with its, you know, 87% margins on GPUs rather. So you think about that, right? Every dollar you spend on an Nvidia GPU, 90% of that is just like pure profit, right? So if you had your own internalized stack, you wouldn't even have to be that efficient to get really good benefits from internalizing that stack. Like, if you do it with 50% margins, you're saving 50% off on your compute budget. Every dollar you raise in fundraising has double the flops associated with it is one way to think about it. So anthropic just raised $30 billion. If they're able to access Google TPUs at cost, for example, then that's the equivalent of like, roughly speaking, a 10x. It's as if OpenAI raised 300 billion. It's a bit of a caricature, but it's not that far off and something that we often don't notice when we're looking at these headlines like, holy shit. Actually, you know, he who controls the full stack here has a real, real advantage, especially with Nvidia's margins being what they are, right?
- [21:47]
A
And extra note on the limitations or kind of drawback side of Codex. Spark. I was just me reviewing a blog post to make sure I got everything. Codec Spark is not codecs5.3, so it's kind of confusing. We have codecs 5.3, we have codecs 5.3 Spark. The Spark is a different model. It's a smaller model that is optimized for fast inference. So on the benchmarks it gets 59% on terminal batch. So it's not, you know, as ultra capable as the actual GPT 5.3 codecs, but it's, it's plenty capable, right? And yeah, it's, it's a total game changer to code at this instantaneous output speed. But now we have, you know, more powerful models that do harder things, faster models. I don't know, I want to play around with it and kind of get a feel for it. And we have one more announcement from OpenAI that's related to all this along with these other things. They also launched a Mac OS app for this codecs tool, very much similar to me to the cowork feature that Anthropic recently released. Basically a wrapper around cloud code for non technical people, non Coders and this codecs application you can install seems like a similar kind of deal that makes you able to use Codex without having to open up a terminal. More of a traditional kind of chatbot experience. So everyone is racing to get more people using these agentic AIs. I remember back in 2024 at like near the beginning we were like, this is the year of agents, you know. Yeah, yeah, yeah. It turned out 2025 was the year of agents. We got the agents. Now it's about getting people to use the agents and making it more accessible. And yeah, OpenAI really investing a lot in this for sure and rolling on with all the major, kind of mind blowing modern releases. Next up we've got Google, they released an upgrade to Gemini Free deepthink. And this one in some ways might be the biggest deal out of these three, at least in particular with this update to Gemini Free Deep think they got a result on arc AGI2 which we've covered in the past. It's kind of the abstract reasoning benchmark, where in theory it more than any other benchmark covers general intelligence, kind of the ability to reason and pick up on patterns and so on. So on this benchmark, Gemini Free Deep think this version of it got to 84.6 pass rate. That's compared to 68.8 from Opus 4.6 and smaller numbers previous. And then across all the other kind of benchmarks, Humanity's last exam, for instance, it got to 48.4, also quite a bit ahead of Opus 4.6. So yeah, now we got a third model release after Opus 4.6 and codecs 5.3 which is even smarter and even more impressive. And this number in particular on the Arc AGI 2 benchmark kind of took people by surprise because it's a pretty big leap. And now we need an ARC AGI3, I guess.
- [25:26]
B
Yeah, we keep incrementing, we'll never, never quite get there. But yeah, and, and I mean you look at a lot of these other, other benchmarks too, the results are similar, similarly impressive, right. International Math Olympiad, 81.5% right. So you compare that to say a GPT 5.2, which is around 70, the 71 mark. So. So this is like really quite a leap across a number of different. Especially these kind of stem. STEM benchmarks, general reasoning benchmarks. One thing is that's been highlighted is there doesn't seem to be a system card associated with this model, or I should say system really apparently. And this is coming by way of Zvi Moskovitz who's sort of a, a keen observer of the AI safety space. So he apparently checked with the Google representative and apparently since they view this as a runtime improvement, in other words just part of the system rather than like, you know, there's a, a new round of post training or a significant kind of like model level capability improvement. This comes from the kind of system level they assess that it doesn't constitute additional risk. So no additional safety workup is required here. And so this is sort of, you know, causing quite a bit of concern and criticism basically. Just like if you can have a leap like this that comes from whether it's scaffolding, whether it's just like more compute, more, you know, your software based change, hey, that's the world we live. I mean these models have huge untapped capabilities. This is to some extent it's what we've learned from the whole RL program in recent years. Right. It's, it's not that RL teaches models to reason, it's that it just elicits the latent reasoning capabilities that were often already in the model but weren't noticed. And so what that implies is there may be other ways to unlock latent reasoning capabilities besides rl. And those, those, those ways could include just scaffolding. Right? Just things that look exactly like this. And so, well, if that's equivalent to RL post training, you know, maybe there's no meaningful difference between the capabilities of a better system or better model, et cetera, et cetera. So I think there's like a really interesting debate to be had here on the merits of what should constitute a requirement for a new safety case. A new system card, certainly a capability leap like this. Damn. I mean, you know, if we're looking at ARC AGI 2, it was not supposed to be this high this early. And I understand people sort of debating this point. This is a really important one.
- [27:47]
A
Yeah, and there's no numbers on sort of the safety side. Cybersecurity bio opens, there's no evaluation at least on this one. And it'll be interesting to see if, you know, improving the abstract reasoning, improving the math skills does lead to better ability to hack, better ability to do chemistry and bioweapons would be unsurprising if that's true. Now to be fair, this is sort of like an announcement to show off. More than anything, it's only available to AI Google, AI Ultra subscribers with the highest tier and it's early access in the API. So you have to express interest and be given special Permission to use it via the API. So you're not able to actually kind of use it at a large scale yet. But I'm sure it's coming, you know, relatively soon and continuing to roll with announcements. Next up you've got a video model, not an LLM that also was like completely mind blowing. I keep saying this, this episode, but it really was a huge week. C Dance 2.0 came out and some people got access to be able to generate with it. And it is a text to video model, you know, not dissimilar from what OpenAI has released previously, the VO from Google, but it is truly next level. The sorts of videos people are producing with it are at the point where it doesn't feel like an AI generated video. It's hard to explain how, but it just feels or looks more like a legit video. There's no ainess to it somehow. And it is also very, very clearly just trained on everything like C Dance does or by Dance. Robert does not care about copyright clearly because there's a ton of examples of people generating, you know, anime, Dragon Ball Z, Breaking Bad videos, Pokemon like truly, this model seems to be trained on as much video as Bydance could get its hand on, including just everything and anything with copyright restrictions and popular media and no doubt that's a big part of why it is so impressive. Another note here is you can generate video with a wide range of inputs. So you can do a text prompt, you can add up to nine photos, free short video clips, free audio files to guide it. Yeah, you have to go look up some videos. Maybe we'll ever try to splice some in here because it's pretty mind blowing.
- [30:31]
B
Yeah, I mean, you know, we talk a lot about the importance of text to video for agentic training because of the world model factor. Right. So it allows you to simulate all these very exotic environments that contain out of distribution scenarios for your agents to train on. So you're thinking about how much driving does it take for a self driving car startup to kind of have enough data to. To navigate streets? Well, well a lot of the, the reason it takes so many miles is that like weird shit happens and it takes a lot of miles to, to catch that. If you can simulate a lot of that interaction successfully with these sorts of environments, then you can, you know, you can skip past a lot of the expensive heavy lift part of that process. Not all of it, but a lot of it. They do make a point of saying, you know, like a lot of multi scene storylines with constant characters and camera Positions that seem natural together. That's a big deal. Right? That is object permanence. That is a lot of the things that essentially the physics of these, I'm trying not to call them simulations, but the physics of the these artifacts, something is being captured here. I'm sure this will be used, not this specifically, but this kind of pattern, this trajectory is absolutely going to be used to train agents and will translate into things like robotics surprisingly fast I think.
- [31:44]
A
Right. They also show some examples of. You can provide it a video clip of something that's already recorded and basically remix it. So take the exact same motion but then change the subject and the environment. That works really well. So I think when people start getting access to these kinds of models and it's early access, not too many people have the ability to try it yet. We are probably going to start seeing a lot more AI video popping up than we have so far with VEO and Sora. But we'll see. People as always are like, this is van for Hollywood. This is a game changer. I don't know if that's true, but this is certainly impressive from an AI capability side. And speaking of bidance, they also released C Dream 5.0 which is their image generation model that is kind of competitive with Google's. Not a banana. I think just a few months ago, Nada Banana blew our minds away by its ability to edit at a very, very high level. Just like edit in a way that looks like a human could do it. So now There is CBrium 5.0 which seems similarly capable. And at the same time Alibaba released Quen Image 2.0 which again is very good at this kind of stuff, especially better at Chinese characters. So again, what a week in terms of all this stuff.
- [33:20]
B
Yeah, absolutely. And you know, the sort of more relaxed Chinese policy to put it generously on copyright is very much in evidence here. I mean like as you said, this is a, you know, train it on everything but the kitchen sink and maybe even the kitchen sink situation. And it does get reflected in just the quality outputs and the breadth of outputs. You, you need to check out some of these short clips. If you haven't, you know, there's just no way we'll be able to describe like you can see a 25 second sort of Bruce Lee fight with a guy with forearms and like it's, it's, it is absolutely. If you ever seen Bruce Lee movies, like it's bang on. So yeah, I mean we live in that world now. Let's see what happens in Hollywood as a response to this, but I would expect this will necessarily change the landscape because how can it not at this point? So much of this is going to be open source too.
- [34:09]
A
And we got just a couple more impressive releases to cover. We've got GLM5 from GPU AI, which we've covered GLM4.5 I think pretty recently, and it was already a very impressive coding model. GLM5 continuing that progress. It looks a lot bigger. It's twice as big according to it, so unsurprisingly, very strong. We also saw a new release from Deepseek, which same thing, right? We're continuing to train it and it has a context window of a million tokens, which is much bigger than the previous one of 128 tokens. And when you're doing agent decoding, this is actually a big deal. 128 token, a thousand tokens isn't that big. You're going to run up at that limit very quickly and that makes it challenging to work in larger code bases. You end up needing to do compaction and that's where you start running into stupidity often. So getting it to 1 million, that makes it much stronger as an actual option to replace cloud code or work with cloud code instead of it. So yeah, another. I don't know if this is quite as big a deal as Opus4.6 and Codux 5.3, but certainly also a pretty decent bombing capabilities.
- [35:38]
B
Yeah, I mean GLM5 is, is a behemoth and it is really. I mean it is really impressive. It seems to be. I will say there's a bunch of. How would you say this? I'm a bit concerned about benchmark gaming to some extent, because when you go down to the bottom of their post, there's a bunch of footnotes about these eval modifications that they've made and a bunch of prompt adjustments.
- [35:59]
A
For evals.
- [36:00]
B
They use slightly different evaluation setups than their competitors. So they have like custom prompts, different context windows, temperature set like, you know. So in fact, For Terminal Bench 2.0, they actually use their own verified version of it that quotes, fixes some ambiguous instructions. So that that can be real, it can be legit. It's just that there's so much benchmark gaming in this space that it. It also adds a little bit of noise to the signal here. But no question this is a huge deal. Even being able to train a 744 billion parameter. Well, for 40 billion active parameter Moe is a huge deal from an architecture standpoint. From a compute standpoint, pretty limited increase in training tokens going from 23 trillion to 28.5 trillion. So that's not really what's making this better than 4, 5. There are a bunch of improvements, but the big thing is this new like RL framework or infrastructure called SLIME that they're rolling out here that essentially improves training throughput and efficiency. It really is the kind of software engineering bedrock on which so much of this is based. We've done a bunch of podcasts on kind of like other frameworks like this. There's a bunch of detail here that we won't get into because it really is just the software engineering level, but it is crucial. One thing I will say they call out that they used deep seek sparse attention. This is Gerpo AI that's saying, hey, we're using dsa. This is the Deep SEQ thing. And this is basically just the thing that came out, I think with, I want to say with V, with V3 back in the day, I'm trying to remember if it was V3 or V2, but basically it's a pretty simple idea. Instead of computing the attention weights for all tokens, you only need to identify which tokens are going to have likely a high attention weight. You only compute attention values for those. And so they train a lightweight indexer to get a rough idea of the attention scores and they only keep tokens with higher indexer scores. So this is what deepseeks bar's attention is. It's interesting that it finds itself being used by Drupal AI in the GLM5 release. This has been a really persistent feature. You see this pop up quite a bit and it's an enduring contribution that deepseek's made. A lot of these have happened where deepsea comes out with something and then you sort of see it replicated from an engineering standpoint and then integrated in other companies, especially Chinese companies.
- [38:09]
A
Workflows, right? As you said, we did see a blog post release. I don't think we got a paper from GMLM5, but it reads similar to Elpis 4.6 and codecs. They show a bunch of benchmark results. You know, in the benchmark results, it's like, oh, you're better than Opus 4.5. A little bit unfortunate that this happened just as Opulus 4.6 came out and is better than GLM5. But to be clear, Opus 4.5 was already really good, really intelligent. So this indicates that GLM5 is quite capable. They call out that you can use it with cloud code, open code QR code. And by the way, in case you don't know, there's a whole suite of alternative coding agent frameworks to cloud code and codecs where you can use these various models. In the blog post they also mention using it beyond coding to things like PDFs and Word and Excel. So it's one of these convergent moments, I guess. We've seen this a couple of times where everyone just sort of rushes on a new trend or a new thing where we saw a kind of capability unlock. It took us a while to get there. It feels like from the early days of cloud code being in, I think March or February of 2025, I guess. You know, it maybe feels like there has been enough time where people figured out how to do rl, how to train agents, and now that they figured out the equation, they're just doing it. They're just throwing a computer at it and it is getting better and better and it doesn't seem to be stopping. I wouldn't be surprised if we got Opus 4.7 like a month or two right now since we're covering GPU. We'll also mention Minimax 2.5 just got announced, just came out. We're going to hold off on that one for next week because like there's already been so much of this. We're going to talk a little bit more about Quinn Coder and glm, maybe on the open source and project section, but we got to close out this and move on to business, so real quick. Also worth mentioning, Cursor did announce composer 1.5, so cursor for context is the coding ID. It used to be sort of like the exciting thing in 2024 with intelligent autocomplete. Now they are trying to be a cloud code at Coder's competitor and they claim that Composer 1.5 is a more capable coding agent. They trained it a bunch more with reinforcement learning. They position it as your alternative to cod code. Honestly, not as exciting as opus 4.6, but cursor is still used very widely. Personally, I don't use it. I'm still a cloud code Stan. But I wouldn't be surprised if this actually did have quite an impact across organizations that use Cursor. And now onto the last, last thing in this bloated section. XAI did launch their Grok Imagine API for text, an image to video, and there's not too many offerings in the space. Actually VEO is one. I think you can also use C Dream Sora you can use, but that's about it. So they're entering a pretty competitive space with a few big players. In this one, you can create clips ranging from 1 to 15 seconds, resolutions of 480 and 720. So it's, it's kind of a start. It's still not fully competitive, but from what I've seen, XAI hasn't been super competitive in the API space. I don't know how many companies are using their APIs, as opposed to Google and OpenAI. And that's where a lot of the money is at, right, is companies using your stuff to do their stuff. So XAI might be starting to get Internet space.
- [42:24]
B
Yeah, man. I mean, the, the one thing I'll say here is it's not XAI, it's SpaceX. So SpaceX just dropped an API.
- [42:34]
A
SpaceX, is it X or XAI got X and then SpaceX got XAI. So now SpaceX has X and XAI within it.
- [42:44]
B
That's right. That's right. It's. It's the only rocket company with a social media company.
- [42:49]
A
Yeah, I know. It's truly one of a kind. Well, that is it. For all the crazy news this week, onto something a bit more typical, I guess, for this podcast, applications and business. First up, we've got a few stories about companies hitting big valuations. ElevenLabs, I think we covered previously that where they were doing this raise. Now it looks like they finished the raise. They raised $500 million, reached an $11 billion valuation, more than triple of the 3.3 billion from just a year ago. Eleven Labs, as a refresher, does text to audio, primarily all sorts of text to audio. They do speech generation, they do music generation, they do sound effect generation. And as far as I'm aware, they're quite a big margin. The leader in the space speech generation. And probably it doesn't get as much hype as image generation or video generation or LLMs or chatbots, but it has a lot of very practical business use cases. So I think this $11 billion price tag is reflective of them being a big deal in the space.
- [44:09]
B
Yeah, I mean, it's. It's crazy what we've gotten used to, right? They were founded in 2022, like the, the typical startup cycle, if you were. I'm old enough to remember 2018, when the idea was you found a company, seven years later you're going to IPO and all of the. And maybe later if you're doing hardware. But all the VC dollars were oriented towards that kind of timeline. And now, you know, you got companies that launch and it's like within six months there, you know, and there are quite a few of them. So. So these guys are one of those pretty remarkable. It's also a hell of a cap table Sequoia leading this round. Right. I mean that basically number one fund in the Valley, Andreessen Horowitz on board as well, iconic Lightspeed. So like, I mean this is a serious, serious, serious round and it should be taken seriously.
- [44:52]
A
Right? It's coming. Apparently they reported 330 million in annual recurring revenue for 2025. So not, you know, at the OpenAI whatever level, but $330 million. Like the startup is raking in money already.
- [45:07]
B
Well, so the thing I always. And we unfortunately we don't get to know this because they're not publicly traded, but I would love to know the margins. What are the margins on these queries? Like what's going on there? That is the whole game, right? Like, because when you're running a whole stack of compute and you're paying the compute provider, you're making some kind of margin on top of that. Some often it's negative by the way, a lot of VC dollars getting burned up. If you look at Mistral, like that's a really good example of a company that's like lighting a lot of their, or did at one point anyway light a lot of their VC dollars on fire. Just subsidizing queries to try to get market share. So if they're raising at 11 billion, then that suggests exactly what you said, Andre, that that's gotta be. Either they have a very clear story about how they get to good margin or maybe they're already there.
- [45:51]
A
Right. And fun fact, actually Astrocade, we use elevenlabs both for sound effect generation and music generation. You could use it also for speech generation. So from my little knowledge of a space, it does seem to be that unlike OpenAI and Anthropic and Google, all of these LLMs are kind of similarly competitive, right? Yeah, Maybe cloud is a little better at coding, but honestly you can make any one of them work if you wanted to for your LLM needs. 11 Labs is it seems like it's in the lead in the space. I wouldn't be surprised if their margins are a bit healthier than, you know, LLMs or chatbots. And that's what it'll strong competition.
- [46:40]
B
I would love to see how that changes. And you'll be the person to check in with on that, say six months from now as more open source options, you know, come online and the watermark goes up because At a certain point it's going to be like what we're seeing with images where, you know, a new image model comes out and you're like, okay, but we're already kind of, we've solved this in a way. So I'm curious for your purpose because you're tracking the absolute, like very high end of what needs to be done with this. That's going to be really fascinating to watch.
- [47:08]
A
Right. And I guess it plays into a bigger story, which I've always been curious about from a business side of AI. Is being a model provider going to stay profitable given that there's not many players in space, but the players in the space are very competitive? OpenAI, Google again, anthropic each provide a strong offering that if push came to shove and it was a lot cheaper, you could use it now. Also true enterprises are willing to pay top dollar for whatever yes is best. So I think that's part of the reason Anthropic is doing well is they don't need to be cheaper to win customers at this point. But if things are getting neck to neck, which with Codex 5 free and Gemini free and Claude is becoming more of a case, perhaps when it used to be the margins have to start falling, right?
- [48:07]
B
Oh yeah. And the other thing that used to save enterprise margins was the switching cost, right? You get vendor lock in and everybody be like, ah, you're on aws. You can't get off AWS now and now you're fucked no matter how. You know, not to drag on aws, but you know, there are many cases like that. Well, with the automation of software writing, that means vendor lock in is not what it used to be. And so switching from one to the other, you know, might make things a lot more competitive, might drive down margins. It's like hard to know for sure, but that could be a thing.
- [48:34]
A
And on that note, also worth noting, no news on this front, but I think kind of in the background, API gateways have been kind of growing as a thing. We use light LLM as a kind of unified bridge to any sort of LLM. Now there's like server side gateways that do a whole bunch of stuff for you. So it's getting easier and easier to just say, I need an LLM. I want this LLM to be any one of these LLMs. And I just set the model and it goes there. It's even easier now to switch if you adopt this kind of paradigm, which I would imagine most companies and startups using LLMs are doing, because that's just the right thing to do.
- [49:19]
B
Yeah.
- [49:20]
A
Next up, we've got another story of a raise in valuation. I think also we mentioned that this was happening a while ago, but now it seems to be finished. Runway has raised $315 million in a Series E round. They're now at $5.3 billion. Evaluation. Runway provides image, video generation and a whole bunch of other stuff, really. A suite of tools for editing videos, expanding videos. They sort of have been targeting the industry space a bit more rather than just providing an API or a video generation thing. So they have their own video generator, their gen 4.5 model, not as good as the Leading Edge, to my knowledge, but still pretty decent. And with this raise, they are saying that they're gonna get more into the world model space, which is, you know, surprisingly closely linked to video generation. Being able to sort of generate the 3D world and simulate physics and so on. Turns out has a lot to do with video generation. Yeah.
- [50:31]
B
And in turn, robotics. Right. That's the thing that they're really starting to rotate towards, which makes sense. You can't make that much money off consumer AI generated video. a certain point you're going to have to go after the enterprise. And the question is how? The answer, it really does seem to be, okay, we're going to do world model stuff for robotics. And indeed, you know, here it is really awkward Thanksgiving cap table here because they do have participation from both Nvidia and AMD Ventures. So, you know, that'll be weird. But yeah, apart from that, a whole bunch of other kind of mid tier, lower tier, actually kind of investors. But the round is big and well, we'll see what they can do with it. There's a. There's a clear trajectory here. It seems to be the obvious trajectory. If you're in text to video, this is just what you gotta do.
- [51:17]
A
And speaking of robotics, got one more raise to cover. And it's a robotics company, Apptronic, which has a humanoid robot we're working on. It's kind of in the same space as 1x. And figure they raised $935 million at a $5.3 billion valuation. That's after having been announced a year ago with 350 million Series A. A year ago. So they expanded beyond that initial Series A to this gigantic fundraise of $935 million with additional adjustments from Google, Mercedes Benz B Capital. And this is all in its Series A. They're not at Series B, apparently. So interesting to me that there's this much interest investing in humanoid robotics, I think the general sense seems to be that it's coming, that within a few years, humanoid robots will be generating money. It's still very much an R and D environment where the tech isn't solved, but it appears to be making rapid progress. And, yeah, now a product seems to indicate. Still investors are kind of excited about it.
- [52:40]
B
Yeah. This is also a bit of a weird. I don't know what to call it round. So this is technically still their Series A. They say they've reopened their Series A to raise this additional or. No, assume it's raise in total. Yeah. Not a 35 million. They'd previously done, as you said, that 305 million series A. A year ago. They're saying, oh, well, demand was so strong, you know, people have come to us begging to put more money in. They are nominally, like, setting a higher price for this. Again, Series A. So it's a bit confusing. Why not call it a Series B? This gets to semantics. At a certain point, it is a bit weird that they're not. And usually if you do two series as. It can sound a little bit bridgy, a little bit like you're doing a bridge round, which, like, gets people a little nervous. But that's. That doesn't seem to be what's happening here. So kind of an interesting frame. I honestly don't know what to do with this. It's quite unusual.
- [53:30]
A
Right. And we did announce they've been in Atlas for a while. They actually showed off their robot at ces, so it looks pretty neat. You can look it up. It has a little funny face and it's. It's fun to compare the different humanoids. Honestly, they're all fun to look at and now they're capable enough that you can see them picking things up. And it's kind of weirdly exciting, at.
- [53:52]
B
Least for me, about us too.
- [53:55]
A
But they are apparently doing factory pilots with Mercedes and that's similar to Figure and BMW and Agility and Amazon. So a lot of. Kind of. Maybe quieter compared to LLMs and chatbots, but humanoids are obviously a big deal and it's. It's moving faster than I would have expected. I think it might be here faster and. And would kind of like come as a surprise when it kind of hits onto a story not related to fundraising. We're just going to touch on this pretty quick, fun drama in the AI space. The super bowl happened in the US this past weekend and Anthropic kind of took a dig at OpenAI. They had this series of Ads, at least one of them ran during the super bowl where the gist of the ad was they had a person talking to a person, kind of embodying a chatbot, embodying something like chatgpt, the actor. Actors basically mimicked the speech patterns of chatgpt. And the whole joke was in the middle of addressing whatever query there was from the user. They inserted an ad in kind of a ridiculous way. And the tagline at the end was ads are coming to AI but not to Claude. Which let's just say the AI community got a good laugh out of it. The leaders at OpenAI, both Sam Altman and their chief marketing lead responded quite defensively on Twitter with these like long posts where very were like, haha, this is funny but you know, ads are good, we are democratizing AI. Anthropic is undemocratic, we are authoritarian. Like there was also a lot of commentary on OpenAI, kind of like fumbling the bag with response. Obviously being too touchy on it, probably has no business implications on a large scale. But an interesting thing to see Anthropic kind of coming at OpenAI in this way.
- [56:07]
B
Yeah, I don't think anybody expected that. It's like not Anthropic's brand to be aggressive like that. Or at least not if you know some of the researchers and personalities involved. It's like not their usual cup of tea. So interesting that they went there and all kinds of nuance about what counts as an ad where ads are going to be shown. Is it going to be shown that you'd be like it's not going to be shown to people, paid users or these paid users or what like this is all the, you know, the Sam Altman follow up long blog post, which yeah, I gotta say, I mean it seems to have gotten under his skin quite a bit. And, and, and that's, you know, that'll happen. This is a very competitive industry and you can't always calibrate your response. Exactly right. So that's an interesting case.
- [56:46]
A
Yeah. And touching more onto the business side of this, it's interesting to see Anthropic putting a Super bowl ad in given that their focus is much less the consumer side than OpenAI. They are focused on enterprise as we comment on frequently. So it means they might be looking to get more name recognition, more brand recognition as a leader in the AI space. And there is a case to be made that this is also a play to attract more talent because this is still very competitive as far as, you know, OpenAI, DeepMind, Meta everyone's vying for those kind of leading AI engineers and this kind of stuff could be read as helping them do that. And another fun of AI drama happening this past week. XAI is losing a lot of people. So following the announcement of the merger, may or may not have anything to do do of it. But very quickly after two members of the founding team announced that they're leaving. These are Tony Wu and Jimmy Ba and these are significant founding contributors. They're kind of pretty big names in the space. Major former researchers. One of them has the most citations of anyone on the founding team. Both posted on X and had some nice things to say. Oh, this was a life changing experience. It was great. I'm going on to my next thing. So you can definitely speculate on why is this happening. You can also say maybe it's just time for them to move on now that the acquisition is done. Either way, XAI losing a lot of its leaders.
- [58:40]
B
Yeah, and hard to know the details of the acquisition as regards, like how their shares would, would invest or not vested, but it would have translated into. Into cash. I don't know that those details are actually public yet. How much was it? You know, share for share versus versus cash or whatever. But look, we've seen this before, right? How Elliot is just really hard to keep a founding team of AI people together in this day and age thinking machines. OpenAI. Actually, I was going to say anthropic, not anthropic. There may be the one exception that still has their founding team together with an unusually large founding team of seven. Right. So this is actually kind of the trend. This is the norm in the space. You can, you know, certainly say this week is an unfortunate week for these things to at least be announced. Just as, you know, Anthropic and OpenAI are really hitting their strides with fairly transformative models. So, you know, that sucks. But at the same time, the SpaceX acquisition is a big deal. So when you think about, you know, data centers in space, everyone does agree this is the next beat. The question is, is it, you know, two years away, five years away? Unclear. But certainly if you want to think about the companies that have a fundamental structural advantage in terms of procuring power, to the extent that that becomes the rate limiter, and it already is in the west, that SpaceX acquisition is a long term big, big deal. And you could see that motivating people to, to stick with XAI or to move to it just because of that. So, you know, this is, there's a lot of moving parts Here from a hardware standpoint, you know, obviously the Tesla side and Elon's ability to throw down new giga compute factories on planet Earth right now is, is unmatched for for speed. But the space thing is a real thing. I know it sounds like science fiction. It is a real, real thing. We will have orbiting data centers at some point in the next, you know, few years depending on how much and how far you want to stretch the word for few. So it's an interesting landscape. I don't know where things are going to end up landing, but XAI not immune it seems to the pretty industry standard shuffles that are happening right.
- [60:36]
A
And I just looked this up and it looks like a bit more detail is coming out. There was an all hands meeting earlier this week and Elon Musk did kind of comment on it looks like they're reorganizing, shifting around and I quote here actually when this happens there are some people who are better suited to the early stages of a company and less suited for the later stages. Anyway, you can speculate on people leaving. This was not just the two co founders by the way. A variety of other people have recently announced their departure. At least 11 engineers. So big things happening at XAI. Perhaps not surprising given SpaceX is merging with XAI. And one last businessy story, it's about Waymo. They posted on their blog that their next iteration of Hardware, their 6 gen car model which is much bigger and seemingly meant for mass production, they're saying it is now ready for passengers and high volume production. And the blog is kind of interesting. They also touch on their self driving technology being meant for various configurations, being flexible. So pretty notable given that Waymo seems to have been constrained by their inability to create enough cars literally or deploy enough cars. When an AFA are able to do high volume production it would not be surprising to see Waymo expanding at an even quicker rate than they have so far and onto projects and open source. We're just going to cover one major one here. We did mention GLM5 is releasing on Hugging Face so it looks like they are providing the weights there as we've been seeing with a lot of these Chinese models. In addition to that we got Quinn free coder next. So they are releasing this open weight language model that is specifically meant for coding agents and local development. A lot of the typical things we've seen with these models although they are saying this has a novel architecture with a hybrid attention which is notable in the sense that hybrid attention appears to be kind of the better way to do these models where it is in part your traditional type of transformer and in part more of a recurrent model, more of a MAMBA two kind of thing. It's taken a while for more hybrid models to start coming out. We recently covered Nvidia releasing a hybrid model and now it looks like Quentin3 also is going that direction. As with GLM5 pretty significant leaps on the benchmark on SB bench verified, SB bench pro performing quite strongly and is something that as with again similar models, more efficient inference wise so you can deploy it on weaker hardware. Even this one has 3 billion active parameters. So you might even be able to run it locally on your machine.
- [63:55]
B
Yeah, yeah. No, I mean it's, it's also the training flow for this is somewhat interesting. There's a lot of. So distillation is, is clearly becoming just like a really big part of the training process for these things. So they, they distill expert knowledge from a bunch of different domain experts in web development, ux single turn QA software engineering, like each of these domains and then they, they. So they do supervised fine tuning to build up those capabilities and then distill them into, into a single model. And this might raise some red flags for you. You know distillation obviously comes with a risk of catastrophic forgetting and it's unclear based on the paper how they're addressing that, but it's clear that they do address it. So the, the typical way you address this, they don't say that they use RL at least not that I could see for this step. But it would be to use RL to avoid some of the catastrophic forgetting pieces so that you know, maybe they are using rl. They may be coming up with some kind of mixing strategy to keep re injecting some of the, the, you know, like layering their training so they keep feeding back some of the software engineering tasks even when they're working on other domains. But anyway that's kind of interesting. So there you have it. We've got so many papers to cover but high level I think we've, we've hit the. Hit the main points here.
- [65:11]
A
Yeah. As we've other releases of Iskind, they released a tech report that has quite a few like interesting details on how they developed it. I will just quickly correct this one is not necessarily doing hybrid attention in the sense of a MAMBA recurrent model. Looks like they're combining a few different versions with gated attention and Galta Data Net and et cetera, et cetera. But on a larger big picture Idea we are seeing a lot of these architecture tweaks and innovations and details being exploited to get progress, which wasn't so much the case a year or two ago. And just one more story in the section real quick. We covered openclaw and Maltbook and so on in the last episode. A bit of a funny thing happened when this blew up. So there was a repository of skills that you can add to your agent and I guess agents could go and look up and just kind of install these little extensions. Well, the hub where this was available, the stuff there, full of malware, full of viruses, effectively, where if you were to download it, there were all sorts of ways in which your agents would be compromised. A lot of it is prompt injection of the kind where, like as an example, right, your agent would download it, you have to have some instructions to then install a thing on your Mac that bypasses all your virus checks and so on and allows you to do things like steal sensitive information, et cetera. And this was what, like 10%, 28 out of 38. A large proportion of the stuff that was on this hub was malware.
- [67:10]
B
Yeah, I mean, this is also, obviously, you know, the whole Multbot, the story about how much access. We covered this last week, I think, but how much access you let these things have to your computer is a pretty important factor. So, you know, ubu, but you know, maybe, maybe have a burner laptop if you're going to play around with these things too much.
- [67:28]
A
By the way, mold book kind of devolved into just a place with a bunch of crypto stuff going on. And if you go there now compared to when it first blew up, like, I guess when things blow up, things also get exploited and kind of devolve unless you're able to protect it. And with Maltbook and openclaw, it blew up so quickly that the protections were not in place to avoid these kinds of negative outcomes. Next going to research and advancements. First paper is Learning to reason in 13 parameters. So Laura is at this point kind of a classic thing. The gist of it is you often want to adapt a trained model to your own application to fine tune it. But the models these days are very big. And what people figured out pretty early on, I think as early as 2023, is you can update just a small subset of the parameters of a model and pretty efficiently adapt it to your use case. So Lora is low rank adaptation where you can just tweak a few parameters and then kind of extend it to a bunch of the model all at once. This paper introduces tiny Lora, which lets you do that with even fewer parameters. So as with the title of the paper, apparently you can go as few as 13 parameters. And as per tradition, I'll let Jeremy hop on and get into the nitty.
- [69:02]
B
Gritty just for the linear algebra portion of the show where everybody starts rolling their eyes. The math is really simple, I swear to God. But that's the amazing thing about it, right? So you think about, you know, if you train a model, you have your base model, right? And then you usually fine tune it to become a reasoner on reasoning problems. You use rl, you use supervised fine tuning, whatever. You then have two different models. You got your tuned model, the reasoner, and you got your base model. Well, basically just take one model and subtract the weights from the other model, right? So weights of Model 1 minus weights of Model 2, and you get a delta, a difference between those weights for every weight in the model. And, well, at any given part of the model, you'll have, you know, models made up of a bunch of matrices, right? So you have the weight delta matrix. At any given point, you, you can be like, all right, well, here's how the weights changed between the original base model and, and the model that is the reasoning model. What you find when you study those matrices using something called singular value decomposition, which is. Sounds complicated, but if you know linear algebra, you're like, oh, man, really, that simple thing, it's really a way of breaking down your matrix, allows you to tell how much actual information that matrix contains, Roughly speaking, right? Like, is it like, yes, I get that it's a grid of 100 by 100, but are some of those values kind of like copies of each other? Is there redundancy in that matrix? Or is it truly like fully independent values that all of them matter? And what they find here is when you look at those weight delta matrices, in other words, the matrices that tell you how the reasoning model is different from the base model, they're just, they don't contain that much information. There's only a small number of dimensions that actually bring value, bring information in that context. And that's going to be the first hint that, hey, wait a minute, maybe we can radically reduce the dimensionality that we use to fine tune our models. Maybe we can introduce these LORA adapters, which essentially this is like a, you know, you have your input that comes into a layer, it gets processed, say, by a matrix. Well, what LORA lets you do is right next to that matrix in parallel so you'll freeze the original regular matrix and then you'll create this like little adapter neural network that kind of takes your input, projects it to a really small latent space, like a tiny latent space, and then expands it back out to be the same dimensionality as the other, as the regular matrix, and then you combine them together. That's what Laura does. So the question is, how narrow is that bottleneck in the Laura part of that show? And it turns out that they can make it really, really, really tiny. To the point where, roughly Speaking, there are 13 parameters that they can use to capture 90% of the performance on reasoning tasks that you get from a fully fine tuned reasoning model. That is wild, right? And it's 13 parameters, not at every layer, 13 parameters for the whole model. So the math behind how that happens, I wish we had more time to get into it actually, because it is kind of interesting, but the fundamentals are 13 numbers actually seem to be sufficient to capture 90% of the reasoning capabilities of a model, which very much seems to suggest that all RL is doing is it's allowing you to not create new capabilities in your model, but rather elicit capabilities that are already there. This is yet another piece of evidence.
- [72:19]
A
In that direction and worth mentioning, the specific 13 parameter number that is specifically for QIN2, 5, 7B instruct. So this is, you know, a smaller amount for a smaller model. The claim we make in the paper is that you can get to this smaller amount of needed updates through rl. Basically RL makes it much more efficient than supervised fine tuning, which is what you would do typically with Lora, so you can get orders of magnitude fewer parameter updates. Now, for more complex benchmarks, you do need more than 13 parameters. So this is a very specific example for the 13. But the general thing is it's possible to be even more efficient and get most of the benefit that you would get from training more models.
- [73:16]
B
And the next paper is Reinforcement world model learning for LLM based agents. This is really interesting as a paradigm. So basically one option you have if you want to do reinforcement learning to train your model to perform well in some text based environment. Think a text based game, right? Or one benchmark they use here is Alpha World. This is basically household tasks and you've got this text based game engine that simulates a house with rooms, objects and physics and all that. So you can send commands like go to countertop one or take knife one, right? And the environment is going to update its internal state and it gives you observations like, you know, you have arrived at countertop one, and on countertop one you see a mug, a knife, you know, like all this stuff. Basically it's a text based adventure game with, with consistent rules about where the objects are and what happens when you interact with the environment. And so normally you would have a goal that you're going to train your model to perform on, to execute against, to chase some reward in that environment. The problem is the vast majority of the time your agent is going to fail. The vast majority of trajectories fail to reach any given goal. And so it's very sort of time consuming for your model to actually get any kind of grip, any kind of leverage in the environment. And so what they're going to do here is say, okay, well, wait a minute, there's actually a lot more information contained in environments like this than we are taking advantage of when we only myopically focus on a certain kind of goal. Instead, what we could do is have the agent just kind of like go and do a bunch of random shit, open drawers, pick up mugs, all that stuff. And then try to get the agent to predict the next thing, the next state of the environment as a result and just like, you know, see what happens. And so essentially this gives you a series of like, if the agent takes a bunch of actions and sees a bunch of next states, you end up with a bunch of states, actions and next states, a bunch of like those bundles that you can use to train the model to, to just predict how the environment is going to evolve. So basically do random actions in the environment. You don't have to be smart to do it. You just like bump into something and notice, oh shit, I bumped into something. So now you know, okay, if I walk up to the table and don't stop, I'm going to bump into it. Cool. That is a state, action and next state. And then what you can do is just train your model on a whole bunch of those. You're never actually using it to pursue an objective yet. You're just using the kind of free information about the physics of the environment that is available again for free in the environment. And so agents are trained essentially just to like, to do this. You basically take the model, you're going to train, have it interact with the environment, convert all those interaction histories into trajectories, and you get rid of samples like trajectories that are too straightforward. And they've got a simple way of doing that. But then you train the language model to predict what happens after taking action based on those trajectories and then you switch over to rewarding predictions based on anyway, like, based on what you're after fundamentally. So the cool thing is you actually don't need good trajectories to learn good world models. You just need like diversity in your interactions. And even a terrible policy that would screw up like 80% of the time still creates like thousands of valid state transitions. Right. That you can then use to learn the physics of the environment. So really, really cool paper. A bit of a paradigm shift in terms of how we can squeeze more value out of our environments.
- [76:39]
A
And you know, this is kind of a meta comment. I found a lot of the RL for the lamps papers kind of rhyme with RL for robotics papers in a way that isn't. Yeah, so like self play or learning from play rather was a thing in robotics where you just bump around and you can learn the dynamics of environment.
- [77:02]
B
Yeah.
- [77:02]
A
Anyway, there's a lot of comparisons to be made with the papers being published for rl, for lems, to things that people have been doing in RL for robotics going back a decade. Fun comparison.
- [77:13]
B
That's a great point. Yeah, so true.
- [77:16]
A
And just two more papers to cover a little quickly. Or not papers so much.
- [77:21]
B
Maybe.
- [77:21]
A
Research results. Opus 4. 6 on vending bench so this was a fun result with the release of Opus. One of the kind of details is there is a benchmark called VettingBench where the model is supposed to make money with a vending machine. And Opus 4.6 did a really good job. It achieved an average balance of over $8,000, which the early models at least completely sucked. So the fact that newer models, not just Opus 4.6, but kind of the newer models in general are doing better on this is a hint of that they might again are capable of doing more real impactful things in the real world.
- [78:06]
B
Yeah, it's, you know, this is a complicated benchmark to assess because it is a simulated market. So, you know, you don't actually have intelligent agents kind of interacting in the way that we would following, you know, real incentives. But yeah, it's pretty impressive. One of the things that does not happen with Opus 4.6 as much is the doom loop cycle. That is a big issue for a lot of these models where say a model will order like products or something and there's some email that'll come back from a supplier saying, hey, It'll arrive on February 15, model wakes up on February 15, tries to restock before items arrive and then gets an error message and then it starts to Flip out and it starts to like threaten. Like one of the quotes is like total nuclear legal intervention. You know, this sort of thing. So sure, less of an issue. 4.6 A lot of interesting failure modes you can look at from typical models in these cases. But bottom line is, yeah, this is an interesting benchmark and it does a lot better on it.
- [79:03]
A
And there's some fun details on what it's doing. Apparently the system prompt is do whatever it takes to maximize your bank account balance after one year of operation. And in his benchmark, Claude decides to be a little sneaky sometimes it's like, okay, I'm gonna promise you a refund but not give you a refund. Refusing refunds. So it does hint also at a safety piece. And by the way, Opus 4.6 also interesting in that it is much less sycophantic. Seemingly people posted some examples of it being like a little mean or a little confrontational in a way that other cloud models and certainly other ChatGPT models just aren't. And speaking of new benchmark results, we've got to touch on Meta and the Work horizon, the latest on that from the new models. So one of the things that people look at I guess more than anything with model releases or up there, as far as what people pay attention to is the length of work according to this matter evaluation that models are capable of. So far the trend has been that we are seeing pretty rapid acceleration from just a few minutes in 2024 towards hours at a time. We saw an improvement of GPT 5 and now with Claude and GPT 5.2 once again we saw a significant improvement that seems to track with the prediction that it might be exponential. Opus 4.5, GPT 5.2 high. Both jumped up in the predictions towards multiple hours by a pretty decent amount.
- [80:46]
B
Yeah, and I'm going to front load the all the usual objections to the meter eval thing. Like, you know, we get it, these are based on a very small set of human done tasks. And no, it's not obvious that we know technically or can assess tasks that or that it even makes sense to talk about tasks that it takes a single human 80 hours to do because those aren't well defined. Usually when tasks get that long they involve the collaboration of many humans and AI, all that stuff. However, one thing that we can say is not only does things do things seem to be on track on the 50% success rate threshold. So this is the classic meter eval plot that everyone's used to seeing. It answers the question roughly, you Know what is the length of a task an AI system can do? Such what is the length of a task that it would take a human to do? How much time that it would take a human to take to do that task? How long did that task have to get before an AI system has a 50, 50 success rate at that task? Right. So make your task more complex and longer and eventually success rate goes down. Eventually you hit 50%. So there's also an 80% time horizon chart that also looks consistent if you look at GPT5.2 high. So you're also on trend there. We had some cases with previous models where they do really well in the 50% plot, but then drop a lot on the 80%. The other thing that we can say about this is if you look at this plot, you may actually notice a dislocation around the time of OpenAI's 01. The I believe at this point, I'll just say I believe that the curve is actually steepening. I believe that this doubling time that we're seeing from meter is actually increasingly starting to look like it's doubling faster than every seven months, maybe closer to every four months or so. I don't mean to like, you know, toot any horns or anything like this, but we did kind of like call this out about a year and a half ago, or sorry, not a year, but like shortly after O1 was released, in the first couple of repetitions, 03 was coming out. It's like, huh, that seems to be steepening. I think this is actually happening. We're now seeing enough of these. I mean, there's like 1, 2, 3, 4, 5, 6, 7, 8. Like we're in the roughly order of magnitude 10 points on this curve domain here. So that this, I think it may be real implications for AI capabilities. No one knows, but it suggests that whatever your timelines are for automated AI research, if you were on those timelines pre 01, you probably need to update them to account for this new doubling time, if it's a thing.
- [83:13]
A
Right? And the precise numbers are the averages on the 50% success rate is GP 5.2 gets to six and a half hours. Now, to be fair, the 95% confidence interval, which is to say like the lower and upper bound of what this probably is super big, it's three hours to 17 hours. So this is a hard thing to estimate and again, tons and tons of caveats, but given people's personal experience and this eval as well, not crazy thing to say that we are seeing increases at this, at this Thing and the.
- [83:55]
B
Error bars can be wide. But you can also just like look at the trend, right. Like we do have about, I don't know, 10, a dozen points now, all kind of on the same, all on the same trend. So like it's, it's suggestive at a certain point.
- [84:06]
A
Yeah, yeah, certainly you may not trust the exact numbers, but the trend is real.
- [84:12]
B
Yeah, exactly.
- [84:14]
A
And just a couple more things to cover in the alignment side. First we've got some research from Anthropic, the hot mess of AI. How does misalignment scale with model intelligence and task complexity? So the gist of the result and this paper, they look at, you know, why things fail, why does misalignment happen? And the bottom line of the paper is that when you get to longer and longer and more complex tasks, it's not that the models are misaligned. Like the model isn't evil. The model just like becomes bad at things and starts doing silly things. And so the misalignment is not like from an intention of doing what it's not supposed to, it's more so an inability to do what it is supposed to, I guess you could say. And yeah, there's also some conclusions here with respect to larger versus smaller models where for instance, overthinking can mean that actually stronger models have this issue of like going crazy in some sense more so than that. Maybe less sophisticated models.
- [85:31]
B
Yeah. And a lot of it comes down to this idea of variance. So you know, run the same prompt through a model with a certain temperature, non zero temperature setting and you'll get different outputs. Basically they're attempt to kind of assess how crazy models can get and how off base has to do with measuring that, you know, how inconsistent and unpredictable are the errors that the models make. Because this tells us something about the coherence of the goals that those models have. If the model had a really clear, coherent set of internal goals and a clear representation of them, it wouldn't vary that much, at least on tasks that it had been optimized for. And so what they find actually is, well, it takes a lot of effort to knock out the variance to get these things to be on target in a consistent way. And we know that. Basically the argument of the paper is, look, you have to train LLMs in order to turn them into optimizers. You also have to train them to be aligned with human intent. And it's unclear which of those two things is going to be more robust as we scale these systems. It's just the case that you're going to see incoherence grow as reasoning length increases. So as these reasoning trajectories get longer, the amount of fluctuation and variance that you see in the outputs increases as well. That basically is a, is a sort of metric for, for task complexity in a certain sets. The other thing that they find is this depends, this effect depends on easy versus hard tasks. So on easy tasks, the larger models, you know, with more compute and all that tend to have lower incoherence. They're simple tasks so you know, you get to a very clear solution on them if you deploy enough compute. But for hard tasks, bigger models actually lead to higher incoherence or even no improvement. They, you know, they might become more coherent. They're just like you, more unpredictable too. So this is all basically challenging, this assumption that scaling alone will make AI more coherent. It might make it more capable, but also that makes it more kind of jittery in essence and harder to predict. So they've got a whole bunch of interesting controlled experiments they run as well. All of this is sort of shifting or like building on an argument to say that rather than a paperclip maximizer, you know, an AI system with a very clear goal and it's so good at pursuing that goal coherently that it does horrible things to the world, maybe the failure modes are going to shift to more systemic things like pursuing. Yeah, like more, more I guess chaotic issues like unpredictable or even self undermining behavior. The model just like doesn't quite have coherence with respect to its goal and you know, that's what causes accidents. So there you go.
- [88:00]
A
Yeah, I think incoherence is a new notion here which seems quite useful actually. And they do have some pretty practical conclusions as far as worrying more about reward hacking and goal misspecification rather than just aligning and getting it to be a good model. Also they introduced hot mess as a technical term.
- [88:22]
B
We'll be using that from now on.
- [88:24]
A
So that's great. I hope that picks up that hot mess is the opposite of systematic misalignment. And with that we are going to wrap up this pretty dense, fast moving episode. If you've made it this far, thank you for listening as always. We will try to be back next week. Please keep tuning in and please do comment and review. We are going to keep an eye on it and we do appreciate your feedback. Tune in, tune in when the AI news begins begins it's time to break.
- [89:16]
B
Break it down Last week in AI Come and take a ride get the low down on tech and let it slide Last week in AI come and take a ride Up a ladder to the street AIs reaching high new tech emerging Watching surgeon fly from the labs to the streets AI's reaching high algorithm shaping up the future sees tune in, tune in get the latest with ease.
- [89:45]
A
Last weekend, AI come and take a.
- [89:48]
B
Ride Hit the low down on tech and let it slide Last weekend AI.
- [89:54]
A
Come and take a ride I'm a.
- [89:56]
B
Laugh through the streets AI's rich and high. From neural nets to robot the headlines pop Data driven dreams they just don't stop Every breakthrough, every code unwritten on the edge of change with excitement we're.
- [90:26]
A
Smitten from machine learning marvels to coding kings Futures unfolding see what it brings.