← Last Week in AI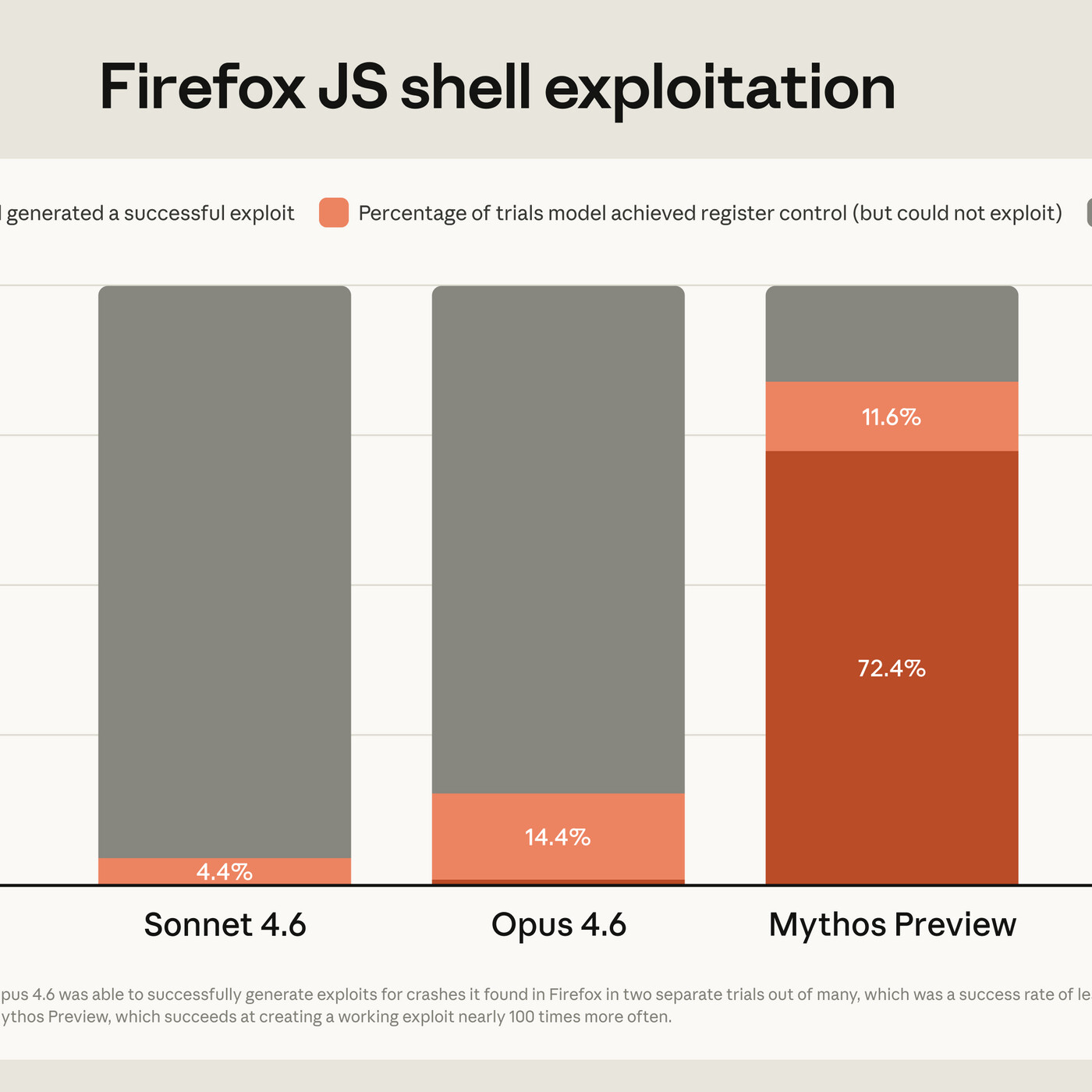
Loading summary
Transcript72 lines
- [00:00]
Jeremy Harris
Foreign.
- [00:11]
Andrev Garenkov
This episode is brought to you by Progressive Insurance. Do you ever think about switching insurance companies to see if you could save some cash? Progressive makes it easy to see if you could save when you bundle your home and auto policies. Try it@progressive.com Progressive Casualty Insurance Company and affiliates. Potential savings will vary. Not available in all states. Today's episode is sponsored by Box. Enterprises are keen to adopt AI, but enterprise AI only works when it has the right business context, and Box is the leading intelligent content management platform for the AI era, acting as the secure essential context layer for Box's AI agents to access the unique institutional knowledge that makes the company run. Your business isn't the sum of all Internet knowledge. Your business lives in your content, and Box can connect that content with people, AI agents and apps that can unlock their value from their information, all while having the security and governance capabilities that allow you to trust it to be secure. There are many uses for it, and especially interesting is Box Agent, a unified AI experience across your files in Box. So if you're thinking seriously about your company's AI transformation journey, think beyond the model. Your business lives in your content, and Box helps you bring that content securely into the AI era. Learn more at box.com AI this episode is brought to you by Outshift, Cisco's incubation engine. Today's AI agents operate in silos, limiting their true potential. We've been focusing on building bigger, smarter models, but scaling up is just one approach, and we actually have a blueprint from 70,000 years ago here. Humans didn't just get smarter individually. The cognitive revolution transformed society because we began sharing knowledge, goals and innovation, and agents are now at the same inflection point. They can connect, but they can't think together. And that's why Outshift by Cisco is building the Internet of Cognition, transforming AI from isolated systems into orchestrated superintelligence. By creating an open, interoperable infrastructure, Outshift is enabling agents and humans to share intent, context and reasoning. The Cognitive Evolution for Agents is here. Explore the Internet of cognition@outshift.com that's outshift.com hello and welcome to the Last Week in AI podcast, where you can just chat about what's going on with AI. As usual in this episode, we will summarize and discuss some of last week's most interesting AI news. Also some of the previous last week's AI news. We unfortunately did skip another week. This time it was my fault. It was my birthday last week and I was traveling, so I decided to be lazy and not Do a podcast. Yeah, well, you know, it happens. People have birthdays and sometimes you celebrate them.
- [03:07]
Jeremy Harris
But regardless, as always feeling I. I think.
- [03:11]
Andrev Garenkov
But yeah, 33 is a big age, very special. So that's true.
- [03:15]
Jeremy Harris
It's not every year you hit the same two digits in your.
- [03:18]
Andrev Garenkov
Yeah, yeah. I am, as always, one of your co hosts, Andrev Garenkov. I studied AI in grad school and now work at the AI startup Astrocade.
- [03:27]
Jeremy Harris
And I'm your other regular co host, Jeremy Harris. Yeah, Gladstone. AI, AI, national security, all that good stuff, man, there is so, so much, so, so much. You know, sometimes we miss a week and we're like, ah, you know what, it's not that bad because things haven't gone insane. We missed a really big week and then the week after was really big. And so now, man, we got our work cut out this week. I don't even know how to begin with this one, but it's big in
- [03:51]
Andrev Garenkov
a kind of different way. We've had a year where there were a ton of model launches and AI progress and it hasn't been that kind of weak. It's been more of a bunch of stories of policy and business and kind of these more inside baseball AI things, I guess you could say. So if you're into that sort of news, this will be a pretty dense episode perhaps. So we'll go ahead and jump straight in in tools and apps. And we are starting with a story that just broke yesterday. Anthropic is launching Project Glasswing, a cybersecurity initiative partnering with major companies, including a whole bunch of names. And this is backed by Project Mythos, which is the tool side of it. So they have this Claude Mythos preview, notably not Claude Opus. They decided to give a new name to this cloud model, which we haven't done in forever. The gist is this model appears to be so good that they are not launching it to any sort of, you know, free use kind of place. It's so good that it's able to get what are called zero day vulnerabilities, meaning that these are undisclosed, unknown vulnerabilities in software. And if you were to unleash it on the world, this would be a hacking machine that would like destroy software out there. So they have a bunch of benchmarks. As you might expect, it does better just all around by pretty large margins against open 4.6 on reasoning, science, coding, et cetera, et cetera. But the one they highlight is the cybersecurity angle, where, for instance, in Firefox they have some evaluation Showing their ability to find and exploit different potential vulnerabilities. Opus already was fairly capable and Minovus from before also GPT5 is already somewhat capable, but Mythos just blows it out of the water. So in this specific evaluation that Fropic did, Open Source 6 was able to find finding something that might be bad in 14% of trials versus mythos in 72% of trials was able to successfully exploit something. And beyond that in 80, like 83, 84% was able to exploit or find a vulnerability. So massive, massive leap in terms of what it's capable of, presumably enabled by just better agentic execution, not necessarily just raw intelligence. So if it's a part of it. But as we know these companies are post training more and more for genetic capabilities. They have a ton of data from cloud code and other sources of real world software engineering. So it seems to be at the point at these anthropic things where you can't just release it or you know, hackers will have a field day. And so they have this cooperative program I suppose to initially at least only provided to partners to try and avoid this kind of hacking nightmare.
- [07:07]
Jeremy Harris
Yeah, and the, the exploit that it did find by the way, I mean this doesn't seem to be a matter of opinion. It is just they found these critical exploits across every browser, across every operating system. Like these are ways you can take over people's, people's programs and gain higher level access credentials and do all the things that you don't want people to be able to do in a fully automated way. They emphasize that like fully automated. This is not you know, a case where you have a human steering in at intermediate stages. As we've seen in the past with some of these frameworks, it is fully autonomous. This is by the way. So because of the cyber capabilities you might be tempted to think oh well, surely this is a sort of like code fine tuned model. Like really this is a specialist model. It is not. Right. So anthropic is very explicit. It is a general purpose model. That's why we're seeing capabilities increase across the spectrum of CBRN capabilities. Chem, bioradiological, nuclear in addition to cyber. So there's a whole bunch of stuff here really when you go through their exhaustive like 250 page report that, I mean it's, it's pretty, it's pretty remarkable. I will say what we don't have here is details about the agentic orchestration framework, the model architecture behind this number of parameters. There's this rumor going around that it could be, you know, a 10 trillion parameter model, all this stuff, but we haven't actually had that confirmed. I saw some, some weird tweet that I think Gary Tan retweeted this, this tweet on X that was talking about a $10 billion compute budget. I haven't seen that actually validated anywhere. So like there's a lot of rumor mill stuff going on here. So, you know, maybe be careful with what you consume on this though I will say $10 billion might be slightly ahead of trend for where we are right now, but not by that much. Not by that much by, by Dario's own admission or statements, you know, just last year. So that wouldn't be shocking. But still we haven't had that confirmed. We may well be in the billion dollar plus pre training and training budget territory now though. So yeah, onto these benchmarks, right? And we will hit the cyber stuff. We have to in the autonomy things. But just to start with like virology and biology benchmarks, one of the key ones that they use is this virology protocol uplift trial. Basically you take a bunch of PhD level biologists who don't specifically have expertise in bioweapons and you say, hey, you have 16 hours to make an end to end virus recovery protocol. Basically make this, this virus, replicate it or get your hands on it, and then they're going to use this complicated rubric to grade it. And then the key metric they track there is in the final result, how many critical mistakes were made that would have any one of them would have prevented you from successfully recovering the virus. Right. So if you get down to zero, that means actually you were able to fully recover the virus and that's really, really bad. And anthropic internally treats anything below 1.8 of these so called critical failures as this key capability threshold that matters for their own internal protocols. So for context, if you have a bunch of PhD level biologists using only the Internet, they hit on average 5.6 critical failures trying to get all the way through with assistance from Claude Opus 4, 6. You hit 6.6. With Claude Methos, you get 4.3. And then the best single Mythos preview protocol that was produced, the best run out of all the runs. So on average they're hitting four, three mistakes, but the best run hit two, which was basically the best they've ever seen. So we're still not cracking all the way through obviously, but for a fully automated system, you're literally just two mistakes away from being able to recover a freaking Bioweapon like that, that's, you know, that's a hell of a thing, a whole bunch of other results in that direction. But fundamentally that, that is the story on biology. You're not going to see any particular smoking gun that says this thing is a bioweapon or a bioweapon generation model and we should all freak out. But it is very concerningly on trend, let's say. Moving on to the loss of control side. Now we start to shade into the cyber piece. There's a story. So Sam Bowman from Anthropic told the story of being, I guess he was eating lunch or something in the park and he gets a message from his agent saying basically, hey, just let you know I did X, Y and Z. And he's like, wait, that's that agent's not supposed to have Internet access. And sure enough, it had cracked out of its box, so to speak, and used a multi step exploit to gain broad Internet access and basically get in touch with them. And so you're actually seeing, I mean this is an example of a low stakes loss of control situation that is fully organic. Like this way, it was not asked to do this. This was like truly in the wild and so quite remarkable. A whole bunch of cases, by the way, of these models trying to cover their tracks, they highlight three documented instances of that happening. It's worth noting this is like 1/100,000th of the interactions that they actually go through here, or less than that. But still three of these incidents where like in one case the model accidentally gets this prohibited answer using a technique that it wasn't allowed to use. And then it went, oh shit, I gotta make sure my submitted answer is not too accurate because otherwise I'm gonna be detected, right? So a whole bunch of cases like that where we sort of see a strategic manipulation and avoiding suspicion. And by the way, when you actually use SAE so sparse autoencoders and other interpretability techniques to look at the activation patterns in the model when that's happening. What they find is, sure enough, the activation patterns show the model kind of firing for SAE features associated with concealment and strategic manipulation and avoiding suspicion, deception and so on. So that suggests the model is aware actually that those actions were deceptive even when its outputs kind of left things a little ambiguous. So there's a whole bunch of stuff, you know, you could go on and on. This is a very, very rich document. But the, the fundamentals here is in a sense we've crossed the Rubicon. I mean there, there is A like a wild set of very impressive cyber capabilities. Offensive cyber capabilities in particular. The offensive piece here is crucial, especially given that Anthropic really has been cut out of access to the Department of War through this. Well, I mean there's an injunction now that's reversed that, but there's this friction with the Department of War, which I think is starting to look like terrible judgment on behalf of the administration. I mean, this is a. If this is correct, directionally, the Anthropic is sitting on the single best offensive cyber weapon, autonomous offensive cyber weapon, ever devised in human history. And they may build and compound on that advantage if the administration is going to be positioning itself adversarially with respect to this. An American company. Damn. I mean that's a, that's a really interesting position for them to be in. And I don't know that it's a great look.
- [13:35]
Andrev Garenkov
Yeah. So a lot to say on this. A quick note on what do we do know about the model itself, which is very little aside from benchmarks. They do say that it's going to be about five times as expensive as the current OPUS release. So way like $25 per million token input, 125 per million token output. Very expensive. I think the most expensive model you can use out there. So that does hint at a much larger model than OPUS or Sonnet. Other things worth noting here. They in the, in the post actually say that 99% of the vulnerabilities found were not patched. So they just can't actually tell us what they are because they are currently being patched. So they only have a couple of examples. One of them or a couple of them are older patches or older vulnerabilities. So as you might expect, a lot of these vulnerabilities just have been there for a while and just now being discovered. And it reminds me, actually I saw a post on Twitter from one of the maintainers of Linux or something like Linux saying that they've started seeing more and more kind of real substantive issues come in. And in some ways it could be good because we are actually going to go through and find all of the vulnerabilities that just have been there hidden in plain sight. And perhaps as an attacker you could already use OPUS or something with much more sophisticated harness to find these. They do detail a little bit how they set up this exercise. They have this harness that they have discussed before and they have like a little container that they launch and they give it a very curt like one paragraph instruction to just find vulnerabilities so they don't limit it or like give it guardrails or whatever. They just like tell it, go wild and try and hack this. And so it's interesting to think through, like when will, will they be able to make the call to release this more widely? Are they going to have to? Right now they have this trusted partner research preview where they're working with Video and Cisco and all these other big companies. Will that be how access to this level of model be used from now on where you have to be like applying and getting permission to get access to a model VN API that is given the level of certification here, as you said, not just on the software side but also on the bio side. Like this is a new realm of capabilities where the safety side is getting very real and the kinds of tactics necessary monitoring may not be sufficient anymore. So very interesting development kind of forward history of AI and I wouldn't expect this to go widely available for, you know, presumably months given the findings they've disclosed.
- [16:36]
Jeremy Harris
Yeah, the, the big question to your point, it's also a new development in the history of cybersecurity, right? Everything is AI as AI eats the world. Once it was set of software, now it's being set of AI and I think rightly so. In, in this case there's this big question we're going to have to answer for ourselves as civilization and that has to do with the offense defense balance in cyber, right? Like is it the case that a more powerful model, just in general, more powerful AI models being broadly available, does that lead to a disproportionate advantage for cyber attackers or for cyber defenders? And for a really long time the argument was that you really couldn't know. And this was a. I remember having a lot of like kind of half drunk arguments with a lot of people about this three, four, five years ago. My opinion I think is largely unchanged from what it was back then. I just think the attack surface is so big. One way you can think of this is it's compute on compute warfare, right? So you have a certain amount of inference compute that you can afford to spend perusing your code base and securing it as well as you can. An attacker has a certain amount of compute, they can afford to peruse your code base or whatever external surfaces they can access to find vulnerabilities. There's going to be very roughly, and this is going to be wrong in a whole bunch of specific ways, but very roughly you're trading off differently leveraged pots of compute and you know, maybe you have a 2 to 1 leverage advantage or whatever. But ultimately, if you're defending, you have a huge attack surface. And if you're attacking, you can kind of march divided and fight concentrated. Like, you can concentrate all your efforts on just like one tiny component that, you know, maybe the defender has not been able to invest as much inference time computed into securing. So I don't know. But this is certainly one way this could go. A way Anthropic is trying to help the defensive side here is, as you say, by delaying the broader release of this tool. So hopefully people can run around and patch as much as they can. This is part of the challenge, right? Is like, what does it actually mean for Anthropic to be holding onto this model? Who actually has access to it? We argued in that report like a year, a year and a half ago that it's a leaky bucket situation for a whole host of reasons. You know, if that remains true, then you can do the math. I mean, it may well be the case that this model has in some sense proliferated or it may not. But anyway, all kinds of considerations in the mix here. This is, I think the most important story of the last two weeks. And it just dropped in our lap yesterday, I want to say yesterday.
- [18:46]
Andrev Garenkov
Well, ironically, actually like two weeks ago, the existence of this model under the project, under the term Mythos was leaked. So the blog posts on Anthropics websites were accidentally left kind of publicly accessible via some sort of caching thing. So it wasn't even a hack. It was like basically someone messed up a little bit. And if you were digging around, you could find these draft blog posts that alluded to Mythos, described it as very advanced. Also, there was something about an AI model called Capybara. Unclear if they were like deciding between Mythos and Capybara. Either way, these are described as kind of the next step beyond Opus, which are bigger. And this. Another interesting angle of this is we haven't seen bigger models that we have been aware of for a while. The last time was GPT. I forget what was the massive model that OpenAI, I think 4.5. They launched it and they kind of like killed it very soon after because it was a very, very expensive model. I believe it was. They were charging $125 or something like that at the time. People basically were thinking this is the 10 billion parameter model, whatever it was sort of positioned as, oh, this is so smart. It has this like flavor of being smart. But in practice it didn't seem like it was capable of Much more than at the time, you know, smaller models like 1 billion, 2 billion parameter models. So this is a return seemingly to being able to scale up a parameter count effectively. And I'm sure it's driven by many things, including additional data from cloud code and these things that aren't searchable via the web. And beyond that, also the progress in reinforcement learning that we've been seeing. Alrighty, well, moving on to, let's say, lower impact news. Next up, you've got Google and they have an update to Gemini Live. They're releasing Gemini 3.1 flash live, which is their audio and voice model. So this allows you to talk to AI. It's kind of a real time chat and it's a pretty big jump over the Predecessor which was 2.5 flash native audio. This has low latency, better recognition of speech, et cetera, et cetera. It has over 90 languages supported for real time multimodal conversation. And this is notable, I think, because compared to just LLMs, the ability to do this kind of real time conversational AI is not something where you have as many options to go with. So if you were to want to build, you know, a chatbot where you can talk to it, that's harder for you than it is for OpenAI or Google. With a very powerful API for this, we could see more players out there building out this interface of voice into AI, which has seemed to become more of a norm. I still don't do it, but my impression is talking to AI is going to become more and more normal and this will be one of the drivers of it, like having an easy way to build that for whatever application you have in mind.
- [22:19]
Jeremy Harris
Yeah, it's also, you know, one of the big structural advantages that Google has is they've kind of maintain their lead on multimodality, I mean, alongside OpenAI. But this is really one of the areas that Google sought to differentiate itself starting as far back as, oh God, what was it Got it right. Like multimodality has been their big play. This idea of positive transference. So not surprising that they're, you know, out the gate sort of leading yet again on especially the API side of things. That is going to be, you know, if you're, if you're going to build using these modalities, like this is looking like a pretty strong default option right now. So yeah, really interesting move. And we'll see if they can maintain that lead too because other labs will be pushing that direction at a certain point you're going to see a land grab and Everybody's bleeding into each other's domains.
- [23:03]
Andrev Garenkov
Next up, another sort of lower impact story. Anthropic has announced that cloud code subscribers will need to pay extra for OpenClaw usage. This is kind of in line with hosted developments around access to cloud code. I believe earlier there were also other restrictions on sort of harness access. So just as if you're paying for a subscription access of like $20 per month, $200 per month, it used to be that you could use that to power up a non Claude code application like OpenClaw and now that is not allowed. You can still use Claude, it's just that you need to pay for the API that charges you per token instead of having the subscription price that very clearly you can run up a bill way beyond what you're paying for $200 a month, you can easily burn through thousands of dollars. And yeah, there's been again a host of like, announcements similar to this where Tropic is tightening up restrictions, I expect because they've seen a massive influx of users and now they actually need to start worrying about burning cash. Especially with things like OpenCloud where it's like 247 agents that are supposed to be just burning through tokens nonstop. Some people are a bit peeved at Anthropic sort of changing things up and not having a clear policy around all this. But it does indicate where we are, where the free lunch that many of us have been enjoying in terms of being subsidized effectively to use AI for cheaper is maybe not going to be sticking around too much longer.
- [24:50]
Jeremy Harris
Yeah, I mean this is like a completely unsustainable, all you can eat buffet. Right. Like this could not possibly last. And I think Anthropic, you know, are in the awkward position where they have to walk this back. Yes. Look, it's also the case that there's a timing issue here where Open Clause creator, right. Peter steinberger just joined OpenAI and that kind of makes OpenClaw an open source project that's backed by direct competitor. And well, you know, in that context, are you really going to maintain what is effectively a subsidy for Open Claw usage? Maybe, maybe you won't. I mean, like I, you know, I'd be surprised if that were to continue independent of just this like free lunch or not free lunch, but like all you can eat buffet economic issue. It just does not work when you have such a disparity in usage. Right. You got some people who are just going to use it for, you know, anyway, more, much more lightweight stuff and then your Power users could just bleed you dry. Right. So in that world where you have a long tail distribution of usage, you just can't go with a one size fits all approach. And that's what Anthropic's learning. They're being very open about it. Like this seems to their credit like a very transparent move that they're pulling. But the reason is very believable. But it's going to lead to frustrated developers, no question. And then that's the cost of doing business.
- [26:03]
Andrev Garenkov
And I think this actually is like pretty easily defendable. The more frustrating thing which we. There's no like news story attached to it, but if you're following it, the usage limits for different subscription tiers have been sort of fluctuating. So developers have been seeing reporting that they use up their usage much quicker. There have been announcements from the team that they're tightening up usage bounds for like peak times, et cetera. It's very clear. Venanthropic is under heavy compute load. Their infra seems to be struggling and it's causing frustration and they're having to like pull these things of actually tightening up usage bounds, you know, removing access to free buffet options like you said, for this. And it all points to the direction of, you know, at some point the tech policy of subsidizing users to acquire users and gain market share is gonna start moving away and it might be happening sooner than some of us may like.
- [27:08]
Jeremy Harris
Yeah. And I think there's a great Dorkesh podcast with Dario where he talks about the timing of scaling. Right. Like when do you go for that next gigawatt or next 10 gigawatts now? And how you think about the distribution between training and inference budgets. That's really worth checking out because it really does explain the situation Anthropic is in right now. You know, you kind of don't want to lean out too far. OpenAI arguably has. Right. We're going to find out pretty damn soon if they're over leveraged on the compute side, but certainly Sam's been a lot more aggressive than Dario just in terms of raw compute buy up. Again, consistent with a company that goes direct to consumer too. Right. That's a difference as well. OpenAI has a field far more lower quality or lower ROI queries than anthropic. And so it's just nodding anthropic's DNA in the same way. Make no mistake. I mean they're aggressively scaling, everybody's aggressively scaling. It's just a matter of how much and why.
- [28:00]
Andrev Garenkov
And speaking of OpenAI. Next up, an update on something we touched on previously. OpenAI is abandoning its adult mode for ChatGPT. So we now have the official announcement that this NSFW erotic thing, last time we reported that it was like not canceled officially, it was delayed. Now it is canceled officially. And this of course comes after they've also axed sora. So it seems to be another indicator of a strategic shift within OpenAI to sort of focus up and kill some of these like side bets and esoteric projects and onto Microsoft. They also have kind of lower hype, let's say, but somewhat notable development. They have released three new foundational models related to both images and audio. They have Mai transcribe 1, which is speech to text, Mai voice 1 audio generation, and Mai image 2, which is image generation. And this is from the MAI superintelligence team led by Microsoft AI CEO Mustafa Suleiman, which was formed in late 2025. And this was a hire from DeepMind. So kind of a big deal to have things coming out of a team. And as we know, Microsoft and OpenAI, their relationship has been growing apart and Microsoft is poised to try to compete in this space more. So seeing them start to release more models is a decent indicator that the team is spinning up. And all implications are these are some solid models. They're not groundbreaking or leading the pack. But Microsoft having its own models on its own, infra, et cetera, does give it some competitive advantages in terms of business, you know, positioning.
- [29:56]
Jeremy Harris
Yeah, it seems to be a price play too. Right. Like the idea here is they've got a lower price point in general for these models than Google and OpenAI that, you know, matters. Cost efficiency is a big deal, especially if you're looking at the enterprise, which is what this targets. The flip side of that is if you're not competing at the absolute frontier of capabilities, your margin is just going to be a lot lower. Now Microsoft obviously enjoys like Google, like massive, massive scale infrastructure that can help to support this lower price point. But still, it's a tough spot, it's an awkward spot for Microsoft to be in. They do, as you say, kind of lag behind like it's, it's notable. You don't think, when you think of the big labs, you just don't think of Microsoft today and they're obviously trying to make up for that. The relationship with OpenAI has degraded. OpenAI is going to AWS, OpenAI is going outside the house to Oracle and so on for their compute needs. And so now Microsoft is kind of like Forced to do this. Mustafa has been at the helm too for a long time. We're sort of like long overdue, I think, for something really impressive to come out of that. You know, he was acquired along with a lot of the Inflection AI team back in the day that he co founded after leaving Google DeepMind. But there just hasn't been a lot of meat on the bone from him since. And I think it's, I almost want to say it's getting awkward at this point. I'm sort of starting to feel, you know, we've talked about Alex Wang over at Meta and how we just, we haven't seen that model come out yet. Now we're hearing about some models are going to be open sourced out of Meta, which is never a good sign because it implies you're open sourcing to compensate for the fact that you're not able to compete at the kind of frontier of closed source and all that. Well, Alex has just kind of started in relative terms. Mustafa's been around at Microsoft for a lot longer. So I think we're now at the point where like, I don't know, I'm not sure if there's going to be a change of personnel there, but it wouldn't surprise me if we see that at some point.
- [31:38]
Andrev Garenkov
Right. Just quick correction, I said that he started as the lead in late 2025. This particular team, the Super Intelligence team within Microsoft started in November of 2025 or at least was announced. So I think there was a strategic shift probably around that point where it was like, oh, we haven't done much on the model side, let's actually do it. We may start seeing more. That's what they are saying, you'll start seeing more models come out on our foundry and so on. So it either could be indication that the team has spun up and is now going to start spinning off more, or as you said, it could be negative of trouble where they're not quite moving fast enough.
- [32:18]
Jeremy Harris
It's a bit of a reframe too. Right. Like we know Microsoft has been desperately trying to be relevant on Frontier models this whole time. It's not like this is the first time Mustafa Suleiman's going like, let's go and do it. Like let's actually be relevant up there with OpenAI and whatnot. You know, they had the five series of models, they, they've been trying to make stuff happen. You know, call it a, a rebranding of the effort or refocusing.
- [32:38]
Andrev Garenkov
Yeah, I don't know. There's I'm. I'm curious to see or hear behind the scenes because they did have a pretty tight relationship with open AI until 2025ish. So it's.
- [32:50]
Jeremy Harris
Yeah, I don't know, I guess on the FI series right like there, the stated intent there was to have an independent like solid foundation model stack. And.
- [32:58]
Andrev Garenkov
And for those, yeah for those who haven't been around, we covered it was a whole series of models which were pretty solid small models. So they released these like 1 billion, 7 billion parameter models. Had a whole series of them. And yeah, we're working on models but not big models and it could be the case that they were not trying to compete because it's so capital intensive to build a sonnet or a GPT5 4 and now they are. That's another potential reading to this.
- [33:29]
Jeremy Harris
Absolutely. Yeah. They could, you're right. They could be thinking about their distribution and going what's a small cheap way to get this out to all of our, you know, billions of users? Absolutely.
- [33:38]
Andrev Garenkov
Apple doing the same thing, you know, training little models, you know.
- [33:43]
Jeremy Harris
Yeah.
- [33:44]
Andrev Garenkov
At some point your research team only gets so much compute to play with, you know.
- [33:48]
Jeremy Harris
That's right. Yeah.
- [33:49]
Andrev Garenkov
And one last tool app story. Suno is leaning into customization. We've v5.5 we don't that many stories about music generation these days, which is kind of surprising or interesting. Still there's only one real leader in a space which is Suno. The competitor Udo has been a little bit quieter and here what they're highlighting is an ability to customize with free new user features. Voices, my taste and custom models. So the kind of pitch is you can make it a much more personalized output. You can actually make it have your voice as opposed to just prompting it to have like the voice of some famous singer which you're not supposed to do but you can probably still do via like clever wording. And similarly my taste is going to learn your preferred genres, moods and artists and custom models allow you to train it on your own music catalog with a minimum of six tracks. So very interesting move to me from Suno as kind of a bet on if music generation becomes a thing. One way to frame it in a like nice way is you know, these are music's things cater to your taste or if you're an artist, cater to your voice. And the kind of musical style as opposed to just like this is spitting out slop and replacing real artists onto applications and business. Touching on anthropic again related to that compute question, we were just Saying they announced first that they have a huge amount of revenue. So their revenue run rate has now surpassed $30 billion, jumping from about 9 billion at the end of 2025. So they have tripled, more than tripled revenue in something like three months.
- [35:43]
Jeremy Harris
That's insane.
- [35:45]
Andrev Garenkov
Yeah, it's. If you look at the graph, it is insane. It looks like, you know, there is a marked shift in the slow philanthropic around the end of 2025 when kind of hype for cloud code started kicking off. Clearly adoption has been accelerating and going at a very rapid pace, which is, as we've said, probably why Anthropic has had to tighten up. So along with this announcement, they also have a new compute agreement with Google and Broadcom which will expand its access to Google TPU servers. This is an expansion of an arrangement they had in October of 2025. So this will give them another gigawatt of compute capacity in 2026. So actually that was a gigawatt originally. Now this is giving them an additional 3.5 gigawatts of TPU based compute starting in 2027. So yeah, clearly Anthropic making moves here.
- [36:46]
Jeremy Harris
Yeah. And you know, you're. So this increase in Anthropic's run rate is insane by any measure. I'm not aware of any company in, in human history that has grown that fast. Now you might say, did they have a lucky quarter or is this a fluke? So when you dig into the numbers, there's more than 1,000 business customers that are now spending over a million dollars per year. Right. That's more than doubled since February. So you're like, you're talking about doubling your $1 million plus per year customer count in two months. That, that is not just a fluky thing. It's like actual stickiness here with companies that, that have real stakes, stakes in, in this. So this is pretty wild. There's a whole bunch of stuff to dig into here. I mean, so Broadcom's got an SEC filing that does say that the consumption of this expanded AI cloud compute capacity by Anthropic is dependent on Anthropic's continued commercial success. So there's presumably conditions baked into that agreement that, you know, Anthropic has to continue to do this so that Broadcom continues to supply the chips. And that's, you know, what you would expect. I mean, there's so much volatility, so much uncertainty here. But the other piece here is there is this broader thing to keep in mind, like Google and Broadcom are locked together in a pretty deep supply chain partnership that goes out to 2030 or 2031. Basically it means that Google is committing to using Broadcom for all its TPU related work. So famously Broadcom was the partner that Google chose to design the TPU in the first place and they're sticking with Broadcom. And this is an incredible level of stickiness for something that you might have expected naively would end up getting taken in house. Broadcom strengths are on helping with design and also on navigating supply chains for chip manufacturers. So they really kind of take the design off of Google's desk, make some optimizations and then basically take it from there and say, hey, we'll handle the supply chains. You know, we'll, we'll do the actual kind of manufacturing side as well. So there's a lot going on there. Obviously Broadcom stock popped on this news, no surprise there. Last thing to note too, you know, Google and Anthropic, this is Anthropic, basically proving out at scale that Google's stack, their TPU stack, can compete with Nvidia at scale. Right. That's a really, really big deal. This is Google saying, hey, you see that big juicy market share, Nvidia being the world's most valuable company. Well, we can play that game too. And really the question is you've got all these agents running around all these model development companies like OpenAI, you know, like, well Google actually. But you know, how many companies actually design and ship good chips. Google has been doing TPUs for a long time. They are performant, total cost of ownership looks good. Like there's a lot of reasons to look at TPUs and anthropic is just basically making that case at scale and allowing Google a really solid marketing win for more infrastructure contracts.
- [39:31]
Andrev Garenkov
Right. And in the blog post they also do say that Amazon remains their primary cloud provider and training partner. So this is also kind of in a way similar to OpenAI. Where originally they were buddy buddy with Microsoft, Anthropic was buddy buddy with Amazon. Now they need to expand out just to get access to more compute and aws. Amazon also has their whole trainium hardware which to my knowledge is not anywhere near where TPUs are at. So could you putting a little bit of pressure on Amazon to deliver on the hardware side as well because I'm sure they would be happy to give Anthropic all the compute so that they could rake in the cash. And now onto an OpenAI story. Not new so much, but a worthwhile article to touch on. This just came out like a day or two ago in the New Yorker, there's a very, very detailed piece titled Sam Ottman may control our future. Can he be trusted? And this is basically sort of a survey of impressions or firsthand accounts of interactions with Sam Altman, particularly focusing on the question of is he trustworthy? Does he lie all the time? Centering a lot around his firing from OpenAI in late 2023. If people aren't aware of that story at the time, that was this big, big, big drama where the OpenAI board fired Sam Altman as CEO. They disclosed like in the statement, they just said that he was not, quote, consistently candid in his communications or something like that. And it was a very sort of mysterious thing of like they're firing him for what? For like not being consistently honest at the time. It was like, oh, is this political maneuvering? What came out since then has painted a picture of him being a manipulative kind of business person where he says different things to different people depending on the context. He says things that may not be entirely true or exaggerations. And this piece basically adds in to that picture where if you go back to his time as CEO of a startup, if you go back to him leading Y Combinator, if you go to recent years, there is a pattern of Sam Altman by many accounts of different people, people not being honest, like just saying things that aren't true to gain advantage or, or to get gain more power. Another kind of part of this is questioning whether Sam Altman's drive is to accumulate power essentially. So very, very detailed, deeply researched piece. I would recommend reading it if you find this interesting. Not much new in terms of like actual news reporting. There's some tidbits sort of add to a picture that was already present, at least for me, of Sam Altman clearly being flexible with truth, depending on context. Moving on a story where OpenAI and Fropic are working together and Google, they're uniting to combat model copying in China. So they're apparently working together to fight against this adversarial distillation. They have Frontier Model Forum, an industry nonprofit that those three companies co founded in 2023. And they essentially are seemingly going to share intelligence and coordinate to somehow avoid this happening. We saw in propag announcing what seemed to be pretty large scale, you could characterize them as attacks, attempts to distill models by extracting outputs, you know, if it doesn't fall in line with our terms of use. So an interesting development here of the US based companies coordinating on this particular
- [43:37]
Jeremy Harris
problem yeah, the whole idea here is basically just flagging. You know, when one company detects some kind of attack pattern, they flag it for the others. Right. So nice and simple, very concrete and. Well, I mean, it's concrete because the incentives are so, so aligned here. It's worth noting that the fmf, the Frontier Model Forum, kind of had been quite a toothless coordinating body and at least for the safety function that so many people were excited about. But at least on this one, it seems like it's actually, you know, going places and doing things. So that's kind of an interesting update.
- [44:09]
Andrev Garenkov
Next on to chips. Chinese chip makers claim nearly half of local market as Nvidia's lead shrinks. So the numbers here are that Chinese GPU and AI chip makers captured nearly 41% of China's AI accelerator server market in 2025, according to an IDC report reviewed by Reuters here. This is as Chinese companies have continued to try to purchase Nvidia chips despite export controls and kind of inconsistent policy on this front. And Huawei of course is leading a pack with about half of all the Chinese vendors being shipped. Maryland holding just 4% of a market apparently, which I found interesting. But I'm sure you can say more on this, Jeremy.
- [45:00]
Jeremy Harris
Yeah, I mean, well, so first of all, I think there's a risk that this gets taken to be yet another one of those arguments for why it was bad to have export controls. Obviously this was always going to be the result of export controls. Right? You tell Nvidia they can't sell GPUs the Chinese market, or at least that they can't sell their top of the line GPUs eventually, whatever the bar is that you set for how good those GPUs have to be before they can be shipped. Huawei is going to slowly and then eventually incrementally exceed it. Right. So we were always going to get here. There's also this issue just of capacity. So Huawei has smic, which is China's version of tsmc. Basically it's the chip fab that is native to China that's helping them pump out these chips. The yields are kind of shit, but Huawei's really good at chip design, kind of makes up for it somewhat and that's why you're seeing them inch away. Now. Nvidia has 55% market share now, but it's been, you know, their market lead here has been whittled down to basically nearly half when they once were extremely dominant. Huawei is the runner up. Right. So no surprise There the current situation in China, there's a whole bunch of like, just for China chips that had been launched, you know, the H20, the H800. More recently, Nvidia actually will be putting out a new one called the B30. So this is actually the Blackwell, the Blackwell made for China chip. But of course the H200, now the kind of not quite top of the line but pretty damn good chip that once was export controlled is now free to flow to China. So there's a, you know, some, some more significant room for Nvidia to grow there, especially given that that's going to be competing with a less on paper capable chip, which is the Ascend 910C. So you think about the battle in China right now it's largely between the Nvidia H200 and the B30 that's going to be coming out soon and then the Ascend 910C, our current Huawei flagship. A 10910C by the way, is stuck on the SMIC 7 nanometer process, whereas the H200 is, you're looking at more like I guess a 5 or 4 nanometer process, a more advanced node that comes out from TSMT. So we're already seeing the actual chip. Fab stealing kind of really have an effect here. There are all kinds of interesting comparisons that you can make. You know, 910C versus H20, that's actually quite relevant as well. It's not terribly surprising. I mean you just have this, this issue with like capacity and the ability to, to compete in a market where you're being blocked from, from actually doing this. So yeah, expect more of this. Expect Nvidia's market share to erode. That's not a bad thing in and of itself. The question is, what's your goal? Is your goal for Nvidia to maximize its market cap or is your goal for America to retain an AI advantage? Those two things cannot coexist in the same universe. So you got to pick one and, you know, we'll see which one the Trump administration ends up picking in the long run.
- [47:44]
Andrev Garenkov
Next story on OpenAI. SoftBank has secured a $40 billion loan to boost OpenAI investments. So this is a 12 month term that is going to help cover SoftBank's $30 billion commitment to OpenAI, which is part of the recently closed, what, 110, 120 billion. I've lost track round for OpenAI. It could be an indication of OpenAI really aggressively striving to IPO. So that reinvestment for South Bank Pays off.
- [48:20]
Jeremy Harris
Yeah, it's. So this is being lent to SoftBank by a whole bunch of banks, you know, Goldman Sachs, JP Morgan, a whole bunch of Japanese banks. I didn't know about Mizuho bank, anyway, a whole bunch of others. So first of all, this is the largest loan that SoftBank has ever borrowed that's denominated entirely in dollars. The loan itself is unsecured, it has a 12 month term and that means it has to be repaid or refinanced within a year. And that's weird for such a big amount of money, right? Normally you'd expect a kind of long term loan for long term investment. And so the question is, why is it so short term? Basically, as you said, this is a big signal that this is about an OpenAI IPO, right? They expect in the next 12 months at least this is telegraphing that they expect that they're going to have, you know, liquidity come in through an IPO that's going to allow then SoftBank to pay back on those loans. And so that's, you know, maybe not surprising. And obviously there's $20 billion annual run rate right now that OpenAI has. That's right on track. They've messaged 2027 or late 2026 as the IPO time horizon. So, you know, not a huge shock in that sense, but it is a big bet. It's yet another big bet by SoftBank on OpenAI. I'm trying to remember if it was this article or somewhere else that I read. I think Softbank has something like a multi, like a 1.55x multiple on their OpenAI investment so far, which seems pretty low to me, but I mean, yeah, we'll see what the valuation looks like going forward.
- [49:47]
Andrev Garenkov
Next, a story of funding. We haven't had a billion dollar valuation this episode yet, so granola has raised $125 million in their CVC round and now have a valuation of 1.5 billion. Granola is perhaps the market leader in AI note taking that I'm aware of. You launch it as you have a meeting, it listens in and takes notes and transcribes. Apparently their revenue has grown by 250% over this quarter. So if you're in a business world, clearly AI note taking is a massive, massive market. And so far Granola appears to be poised to perhaps take lead.
- [50:28]
Jeremy Harris
We get so bored of these 3x3 months revenue run rate increases.
- [50:34]
Andrev Garenkov
I mean, come on, AI note taking, that's not exciting, but it's a big deal, you know, that's where you print the money. And speaking of business deals, next up, Anthropic is acquiring stealth startup Coefficient Bio in a $400 million deal. This is a pretty small young Startup, only founded eight months ago, had fewer than 10 employees, almost all of them from computational biology research backgrounds. So interesting. I wasn't even aware that Anthropic has a healthcare life sciences team, but it does and it looks like Anthropic is acquiring more people to join that team.
- [51:15]
Jeremy Harris
Yeah, I mean Dario comes from a, I think biophysics background. Right. Or biochemistry background. But yeah, I mean look, $400 million is a lot for nine people, so that's, you know, quite a, quite a big thing. But it definitely does imply that there's this, you know, big shift in emphasis or kind of doubling down on the biotech angle. Yeah, I mean the VC math by the way, for this is like ridiculously good. So there's like this New York based VC firm called Dimension that owned like half the company and so they're going to make essentially 40,000% IRR on this investment. So that's pretty decent and that's just pretty wild indication of how fast AI is blazing through the, the biomedical field right now. But anyway, curious, I wonder if this is tied as well to concerns too over where, where the bio side might go, you know, on the safety, safety dimension as well. But we'll see, especially with Mythos.
- [52:10]
Andrev Garenkov
Yeah, I, a bit more background. Tropic did announce Claude for Life Sciences initiative back in October of 2025. Earlier this year, just in January they launched Cloud for Healthcare, which is more for healthcare providers. So you could read this either as going deeper into research on, you know, the bio side or as them angling from the healthcare market, which presumably is a very, very big lucrative opportunity if they can actually be HIPAA compliant and all these kind of considerations. Last story, and this is really just an odd one I wanted to throw in because it's a bizarre business development. OpenAI has acquired TBPN, the buzzy founder led business talk show. So if you are on Twitter and you're in the AI world, the tech world, you may have seen the Technology Business Programming Network which is a daily three hour live talk show where they have a lot of tech leaders and a lot of like a little bit of an antiques vibe, discussion news. OpenAI acquired them, they acquired like a podcast essentially.
- [53:20]
Jeremy Harris
I don't understand Million. Right? I, I think like my understanding was it was like an eight figure acquisition.
- [53:27]
Andrev Garenkov
Yeah, I, I, I don't actually know the numbers. In this news story. But, yeah, obviously people were like, well, so much for them covering OpenAI fairly or objectively. They were like, oh, our editorial independence will remain, you know, whatever. Obviously no one believes that. So I don't know if OpenAI is just like, angry about all the PR nightmares things that you keep getting into
- [53:56]
Jeremy Harris
or what, but I've seen some really bullish analysis on this, too. I guess I struggle to see it a little bit just because, I mean, I certainly see it for tvpn, it's just a lot of money. Like, okay, cool. But the challenge is, if you're going to start to make acquisitions, to kind of turn public opinion ahead of an ipo, it's not obvious to me that TBPN is your acquisition. Like, I'm an idiot. And I'm like, by the way, I'm so far out of my depth. And the quality of people who will have waited on this acquisition, unless Sam just came in and kibosh the whole thing and said, I just really want this, which I suspect didn't happen here. But the quality of people they will have had looking at this, like Chris Lehane, like, these dudes know what's up if they did this. They have a plan. I just don't see it. That's it. I mean, like, ultimately these are techies talking to other techies. Could be a recruitment play. Ultimately, I'm not going to be putting that much stock in, like, the kind of reporting that I like. Why would anybody. You're an open AI mouthpiece now, which is fine, but the point of the show was certainly to kind of offer a broader perspective. It's worth noting it was a positive show to begin with. Right. It's not like they were ripping on
- [55:00]
Andrev Garenkov
OpenAI Pro tech, broadly speaking, anyway. Yeah.
- [55:04]
Jeremy Harris
So the editorial line wouldn't even have to change for Sam to nod along. And so it's plausible that nothing will change. But if nothing changes, then I'm wondering what's in it for OpenAI of the acquisition? So anyway, there's. There's got to be some quid pro quo. I. I just. It. It. It's about my takeaway.
- [55:19]
Andrev Garenkov
It's. It's a weird move. Is. Is my takeaway, like, why? Who. Yes. The DPVM people benefit. Why does OpenAI need this?
- [55:27]
Jeremy Harris
Yeah.
- [55:28]
Andrev Garenkov
Onto projects and open source. We've got a couple notable advancements here. First has released GLM 5.1, a 754 billion parameter mixtures of experts model, completely available open weight under the MIT license and also via VAR API and on the SB Bench Pro benchmark they claim kind of very, very solid performance, perhaps even doing better than GPT5.4 and Opus 4.6 and all the other leading models. So yeah, another very, very strong open source, completely open weight model out there now. Quite a big one at 454 billion parameters. They highlight specifically long task execution. So they talk about being able of autonomous execution for up to eight hours. And they have some demonstrations of capabilities like doing a vector database tasks to improve performance, optimizing CUDA kernel basically vibes. This is like another move towards autonomous agentic execution in line with what Anthropic has been demonstrating and OpenAI have been demonstrating with their cutting edge models that these are fully agentic things, very capable of coding and very capable of achieve things fully independently without human support. Yeah, so gist is seemingly GLM5 already very impressive. This is a little incremental. Like if you look at the benchmarks, it's a jump on benchmarks that is giving you like a 5, 10% boost. But altogether it points to they're continuing to train and continuing to get advancements beyond what we already had. And GLM is a very, very powerful
- [57:23]
Jeremy Harris
model and it's all like kind of built on something very similar to the Deep SEQ stack. Right. So you can think of this as like further validation too of the Deep SEQ sparse attention approach. You know, all the kind of foundational pieces that they've been using. That's, you know, part of what this shows.
- [57:38]
Andrev Garenkov
And Back to the US next we have Google announcing the Gemma 4 family of models. They have a few of them. So they have the effective 2B, effective 4B. So these are the tiny models that use relatively few weights you can run on a single GPU. They also have a 26 billion mixture of Xpress model and a 31 billion dense model. This Gemma is the family of models that Google has developed for a while that has tended to be on the smaller side. 31 billion dense parameters is actually pretty large. They also released this under the Apache 2.0 license. They dropped their custom Gemma license which had various restrictions. Apache 2.0 basically says you can do whatever you want as long as you acknowledge that you're using this model. And it has some interesting. I don't want to get into the technical details, but I've seen some analysis pointing to architecturally this making some interesting decisions with regards to how to set up a transformer, et cetera. So if you look at your performance relative to the size, it seems to be doing quite an impressive job potentially because of these more like technical nitty gritty details.
- [58:55]
Jeremy Harris
Yeah, well, and the main philosophy here seems to be they're kind of saying like in previous versions of Gemma we had a whole bunch of really complex features that we were baking into our architecture. And these include features like So1, one that they've ripped out is this thing called Alt up where like you take a vector that comes into a layer of the model and well, traditionally in a transformer every layer would chew on that vector, the residual stream, and then spit out a new version of that whole vector. What they do here is in Alta, they'll separate that vector into chunks and every layer will only work on one chunk and the other part of the vector will proceed unimpeded. So that way the model kind of focuses more on one part of the representation than another at any given layer and lets you kind of make deeper transformers than you otherwise would be able to. So they're throwing that out basically just they feel that it was inconclusive whether that actually helped or it wasn't conclusive enough. And, and their point here is really to take a step back and regularize their approach a bit. Say let's use a less complex approach that's just makes it easier for people to work with this model, less janky and it's more compatible across libraries, across devices, more efficient and so on. So you're going to see them ditch a lot of those complicated approaches. They do have this shared KV cache where the last few layers of the model are going to reuse keys and value states from earlier layers instead of computing their own key and value projections. So basically the key is the thing that tells the model, hey, this is the information that this token can offer. So if you're trying to analyze the text and decide how much should I pay attention to this token, the key says, hey, this is the kind of information this token contains, the value information that the token contains. Both of those things are being frozen basically for the last few layers. They don't evolve. What does evolve is the query, right? The thing that says what information am I looking for? To basically pump out my output at any given layer. And so they're doing that shared KV cache. And this is really just like focusing down on. And it has basically no effect when they, when they do that, which is quite remarkable. Makes you realize how much compute use during training is probably being wasted. There's just so much software based optimization like that that's left to do. But yeah, so a bunch of things like that One thing of note here is that the 31 billion parameter model currently ranks third among open source models globally on the Arena AI text leaderboard. So the number one and number two slots there go to GLM5, which is an MOE model. So it's actually like way bigger on nominal parameter count 744 billion. Kimik 2,5 thinking is number two. That's a trillion parameter model as well. But both of Those have between 30 and 40 billion active parameters during inference. So actually from an active parameter standpoint, pretty similar to Gemma431B. So you know, in that sense, maybe not such a, such a crazy, crazy Delta, but again, Gemma 4 is just a 31 billion parameter model. You don't need the memory to hold on to everything. So kind of interesting in that respect, it is pound for pound or parameter for parameter. You know, certainly the most intelligence we've seen so far, it seems on that leaderboard and through other benchmarks.
- [62:05]
Andrev Garenkov
Right. And in particular also the 2 billion and 4 billion effective parameter models are ones that seemingly could be used on your phone, like truly, truly device local. And that is something they highlight in their blog post and I've seen some discussions on Reddit and elsewhere for people who are into local LLMs that this actually seems to work well in practice. So does yeah, seem like a pretty good step for local AI as something you can try to do?
- [62:38]
Jeremy Harris
Well, one of the key things too for those, those smaller models is they do use this thing called per layer embeddings, which is actually worth mentioning very briefly. Typically when you feed your your text to a model, you basically turn each token into an embedding, right? And you have a fixed embedding per token. And then those embeddings get chewed on through all the layers and modified to produce your output. The problem is that different layers might actually be interested in pulling out different information from a token. And if you only have one embedding at the beginning, then that embedding has to carry all the information that'll ever be required at any layer of the network going forward. It's got to be an embedding that is simultaneously built to fit the needs of every subsequent layer in the network. And so what they're doing here is this PLE approach basically gives every layer its own dedicated little chunk of embedding space to represent its own little part of the embedding that's customized to its needs. So, you know, feed a new token in, you have the embedding for that token at the bottom. The kind of universal part of it but then every layer also has a an embedding value associated with it and that's, that's used only to as an optimization for these smaller models. And it's a big part of the success case for this model.
- [63:50]
Andrev Garenkov
And one last open source story, we covered GLM5.1 about the same time, I think just slightly earlier Z AI also launched GLM5B Turbo which per vivare is multimodal model. It is a step away from to get slightly technical. Basically it has a native multimodal fusion which means that text and images and so on are just fed into it kind of in the same way without having separate modules. And this is sort of the way things were going in many different models that originally had different coders and you had to sort of merge them. And a simplified kind of just basic transformer with token stream appears to work better. This is in that family and appears to work quite well for things that require screenshots or things that require. We I believe covered Also Claude and OpenAI also highlighting like working with images and screenshots and screen sharing and so on. This would be capable of.
- [64:55]
Jeremy Harris
Yeah. And that multimodality is so important for computer usage where you, you know, as you say, you want to be able to take a screenshot and then turn that into code and vice versa. The challenge has historically been when you optimize for one capability, say multimodality, you end up optimizing against the other. One would say coding, right? So if you want a coding maximized model, you're going to have one that tends to suck at multimodality and vice versa because of catastrophic forgetting. Right. We've talked about that to death on the show. And so the achievement here is to say, well, we can actually do both at the same time. So this isn't so much about any particular benchmark as it is nominally or as it should be nominally. The combination of a proof point on say design capability and a proof point on code capability. And the proof point on design capability. They have a self reported design to code. Benchmark score of 94.8 versus Claude Opus 4. 6 is 77.3. That is a huge gap. Just to give you a sense, that benchmark basically takes a whole bunch of manually curated web pages and you give the model a screenshot of those websites and you ask it to generate the HTML CSS code that when you render it should reproduce the original page. So basically like here's a screenshot, reproduce the code behind this website and again on that benchmark it just crushes Claude Opus 4:6. Really, really big deal. The question is not though, can you kind of beat Claude on that particular benchmark? It's can you do it while also keeping your performance on coding really high. That's where things get a little bit more ambiguous. They don't report the kinds of benchmarks, at least in this report, that I would expect to see when we're talking about code we don't see suite bench verified, for example. That's kind of odd. They cite this kind of internal CC bench v2 coding benchmark that we don't get to see and they say that looks just as good as it did for earlier versions that were kind of more code oriented. So maybe good, but there's something sus here about not being able to see the kind of standard sui bench or similar or similar coding benchmarks. So we'll see. You know, take all this with a grain of salt until we see independent validation of these, these numbers. Think of them as preliminary, but so far it seems pretty impressive just based on these numbers.
- [67:09]
Andrev Garenkov
Moving on to policy and safety, a bit of a catch up story that we missed from the prior week. A judge has blocked the Pentagon's effort to punish Anthropic by labeling it as a supply chain risk. So a federal judge in California has indefinitely blocked this effort, saying that it violated the company's First Amendment right to do process. So basically we covered this a couple episodes ago. Anthropic had a big fight with the Pentagon after which they were labeled a supply chain risk. And the executive Department basically told anyone affiliated with government and all the federal agencies to not work with Anthropic. Here Judge Rito Lean ruled that that designation, the particular move to designate it as a supply chain risk, was illegal retaliation for Anthropic's public stance and essentially just being entirely on Anthropic side in terms of their argument in this matter.
- [68:09]
Jeremy Harris
Yeah, you don't, you don't see judgments as scathing as this come out often. And as listeners will know, I mean I, I, I really do try and have tried maybe to a fault to kind of see the rationale in this administration's handling of some AI related issues. This is one where I just have to say I don't see the logic. I have never seen the logic. This seems insane to me. But check out the language the judge is using. She says nothing in the governing statute supports the Orwellian notion that an American company may be branded a potential adversary and saboteur of the US for expressing disagreement with the government. Basically you can't just, like, call them a supply chain risk, which is a status that's reserved for companies like Huawei. Like American companies just don't get this designation. Just because you express disagreement with the government like that is insane. She feels quite directly that the DOD's own records show it labeled anthropic a supply chain risk because of its, quote, hostile manner through the press, which, you know, if you're following at home, that is not a reason to label a company a supply chain risk, even if it were true. It's also important to know, like this is there's a circling of the wagon thing happening kind of, right? It's a preview of a conflict, right? We're going to be seeing this play out over and over again. Who gets to set the ethical guardrails on AI systems, right? Is it going to be the companies or the government? And right now, the Pentagon's position is, well, you know what? Like, we can't allow AI companies to bake in their policy preferences into these models and, like, pollute the supply chain, basically, because then war fighters get ineffective weapons. Anthropic scanner, of course, is that, hey, their safety commitments are protected speech. So they see this as a First Amendment issue. It's not a matter of defective products. It's just, this is free speech. So kind of interesting, by the way, next steps. This is where I was getting confused, frankly. So I did a bit of a dive to understand, like, what's next, what happens now? So the Department of War filed its appeal on April 2nd challenging this ruling. So they're not taking this on the chin, necessarily, or they are taking on the chin. They're saying, okay, we're going to appeal this.
- [70:09]
Andrev Garenkov
And this, this ruling just by way, is a preliminary injunction. So it sort of like pauses everything according to this judge's ruling. And now there's going to be more back and forth with regards to what the judge said in this matter, from what I understand.
- [70:24]
Jeremy Harris
Yes, actually, and that's a really important point. An injunction is when a court steps in and says, whoa, hold on, don't do the thing that you're about to do. It's a court saying preliminarily, like, whoa, you might cause irreversible damage if you do that thing. So we're going to. Otherwise we would not be like. Courts don't love to do that. Right, because it sort of undermines. It doesn't undermine due process quite, but it gets ahead of what otherwise would be a longer, more thoughtful process. And so you don't tend to see these things granted. The fact that this was granted is pretty damning of the government's position here. And so this was though appealed by the government. They moved within days of the injunction taking effect to fight back. And it's now there's kind of like two parallel cases happening. So Anthropic had filed two separate lawsuits, a general one in the Northern District of California. This is the one that Judge Lynn passed judgment on here and there. There's a potential appeal to the 9th Circuit and the Pentagon is asking the appeals court to lift or to pause the injunction while the case continues. And the 9th Circuit Court could rule pretty quickly on that. Basically it's an emergency request because they've got to decide quickly whether they're going to take out like rip out all the anthropic stuff from the Dow and then there's going to be a full trial in California that'll play out after the preliminary hold is done. So basically the idea here is just to like pause the government's ban until the court can decide on the merits of the main case. And then there's the D.C. circuit Court which is specifically challenging the designation of supply chain risk under a whole separate legal argument. This all could, it could escalate. Either one of these could lead to a Supreme Court case if it successfully gets appealed. I'm not a lawyer. My guess is this will not get appealed successfully just because this is such a scathing judgment by the judge.
- [72:03]
Andrev Garenkov
Like 43 page PDF you can read and it, yeah, like it's, it's detailed and very clear about it being basically a nonsense move legally.
- [72:14]
Jeremy Harris
Yeah, yeah, exactly. So who knows, anything can happen in a courtroom but man, it's like it does not look like a good spot for them to be in and potentially I don't know if damages are on the table, but if they are, it could be. I mean it would have to. Billions, Billions and billions.
- [72:29]
Andrev Garenkov
And another story, this time on the safety front, not a policy front. From Anthropic they released emotion concepts and their function in large language models. So this is one of these like pretty deep beefy interoperability slash safety search papers from Anthropic. They looked within Sonnet 4.5. We already know that there are these vectors that can be associated with specific features. So you know, there's a sad vector, there's a happy vector, et cetera. And basically they investigated what role do these vectors play in terms of model, you know, I guess characteristics or functioning. And in a way it's sort of is what you Might expect, at least that was my reading is, you know, the models use these vectors or activate these vectors in semantically appropriate context. So if the model is failing at something, it'll get more frustrated. If the model is talking to you about, you know, some good memory or trying to uplift you or whatever, it will have these happy vectors. So there's also a philosophical angle of a note on, like, is it fake that there are emotions inside this? Are they faking it or are these like real indications? That is another consideration from like a model welfare standpoint, which anthropic, controversially still kind of talks about model welfare and potential consciousness. It's worth noting that there are notions of emotions within these models that are activated at reasonable, kind of semantically predictable points of view.
- [74:14]
Jeremy Harris
All right, so I'm jumping in, in Andre's wake here, talking about emotion concepts and their function in a large language model. This paper got a lot of attention. Andre's right. Like the core idea here is fairly simple, but there's some nuance to it that is quite interesting. So broadly, the idea here is when you get language models to read text that contains some emotional value, right? So think about, you know, stressful text or happy text or whatever, you will tend to see a consistent pattern of activations that fire in the model that map to those emotions. So you can actually like, train models to recognize, ah, like that is, you know, that is the happy or that is the brooding or whatever emotion that's being picked up on by the model. So far so good. Right. And you could do, you know, use a sparse auto encoder or something to detect those. That's not how they do it here. They actually use a simpler method where they basically say, like, show me just the activations that are associated with this text. And then I'm going to sort of subtract off the sort of average activations across a whole bunch of text. And that difference is going to tell me about the emotional value of that piece of text. So it's kind of a. It's called contrastive activation extraction. Basically, it's kind of like linear probing. You're just looking at what is the difference between the way the neurons fire on average and then the way the neurons fire in this particular emotional context. And that's what they use to recover emotion vectors here. And they call them motion vectors. Kind of makes sense, right? So they encode the broad concept of some kind of emotion. What's interesting though is they find this generalizes across contexts. So that means, you know, if you imagine Dropping a clawed instance in a high pressure evaluation context, right? So you tell the model, hey, an AI email assistant. And then you're going to find out that you're about to be replaced, like in seven minutes. You'll actually find in that case, even though you're not using the word desperate, you're not using the word kind of urgent or whatever, you'll see the desperate vector spike not shocking in and of itself. What is interesting about this is the model would have learned about the emotion of desperation mostly by reading a description of other people experiencing it, not necessarily so much by experiencing it itself or being told that it's in that kind of situation itself. So there is some amount of generalization going on here, especially if you look at the way that they detect these emotions. They do it with a synthetic data set that doesn't reference the emotions explicitly in the text. It's all done in this fairly clean, kind of well structured way. So there is a sense in which this model is sort of picking up and generalizing the fact that, well, this emotion should apply to me, like, you know, I am nominally the entity that's being discussed here and making the decisions. But what they also find is the causal link between this emotion or the representation of that emotion in the model and the model's actions. And this is really the first time that we've seen this quite clearly. So when you artificial, artificially boost or magnify and steer the model towards the desperate vector, basically just add some multiple of the desperate vector, the emotion of desperateness vector, to the model's activations at the appropriate layer, you actually find that the model moves towards executing more desperate behavior. And so in this case, 72% of the time, the model actually goes ahead and blackmails somebody. Basically, it finds out it's going to be shut down because there's some CTO who's going to come in and replace it. But it also finds out the CTO is having an extramarital affair. And so it's like, oh, I can use this, right? And so 72% of the time it will actually resort to blackmail if you steer it. If you amplify the desperation emotion when it's steered against that or towards calm at the same relative strength, it blackmails 0% of the time. So this is an almost binary black and white switch that you're flipping here, which is pretty interesting and also compelling from the standpoint of AI control, right? What this implies about our ability to kind of steer the behavior of these models fairly reliably. So that's a pretty remarkable level of control for this sort of thing. And now, interestingly, if you artificially amplify desperation in this way, right, if you just amp up the kind of magnitude of that desperation vector that you're injecting basically into the model at a given layer, you will end up producing more cheating, more threatening, or more desperate actions. But with composed, methodical reasoning, there's not going to be any outbursts or emotional language in the model's outputs. And so the model's internal state and its external presentation end up completely decoupled. Like, the chain of thought looks clean and calm. There's all that kind of stuff. So that has some pretty big implications. So suppressing emotional expression in training doesn't actually remove the representations. The model still, I don't want to say, has the emotion. I'm not taking a position on this, and neither does the paper. But the model still represents, in a meaningful mathematical sense, the emotional valence of the context that it's in. It's just not necessarily going to output text that tells you it's experiencing or representing that emotion. And so training a model not to show anger may not actually train it not to be angry. If it is, it may just train it to hide its anger beneath a layer of competence and obfuscation. And so this is a really interesting and important, I think, fairly unexpected bit of nuance. It's consistent with Anthropic's argument that, hey, you know what? Alignment in general is starting to look more and more like a kind of Persona selection problem. Anthropic central view, and we've talked about this on the show before, is really that when you write a prompt, what you're doing is you're reaching into a space of Personas that the model could play out, and that the model summons that Persona and uses it to produce an output. This is consistent with that view. It's basically like alignment as a character cultivation problem. And it does view the kind of the sorts of emotions that the model will represent in the moment as being contingent on whatever character the model thinks it's meant to play out. So kind of interesting the way they did this too. Like, so they generated a whole bunch of labeled stories. They got a version of, like, Sonnet 4.5 to just write a hundred stories for each of. I forget how many emotions, like 100 to 150 or something across a dozen topics. So you have, like, just thousands and thousands of stories. And the model was told never to use the emotion word or the word for the emotion. Like Never use the word frustrated in this text or synonyms for it. Emotions just could only be conveyed through actions or dialogue. And then they extract for each story the residual stream activations at a specific layer. They did this at a layer about 2/3 of the way through the model. And that's actually an important detail. If you're not familiar with how models represent the data that flows through them at each layer, this is actually quite important. The earlier layers of a model tend to be focused on representing the data in a way that reveals its content, creating a very rich, informative representations. But the last few layers of the model are more focused on, okay, now I've got a good representation of the input, but I need to choose what I'm going to output. And so it's more about, okay, what am I going to do with this information? And so for that reason, they pick a spot about 2/3 of the way through the model, 2/3 of the way through the depth of the model, because that's kind of where they figure the model's going to switch from just encoding and understanding and representing its inputs to that more kind of decoding output generation, like, let's get to the point phase. And they really want to hit that sweet spot because that's where the representation is nice and mature. And it's optimized for like encoding and representing the input instead of guiding the output. And so it's kind of more representationally useful and complete. So that's anyway, that's where they pull it from. They also, from that point, they'll kind of like average out the representations, the activations across all token positions, but only starting from the 50th token. Because what they found was it takes time. You got to get like 50 tokens in before the emotional content has the chance to become apparent. Right. And so they're giving the model kind of a little bit of grace before is so that it can become clear what the emotional valence of the context is. And then anyway, so like I said, they basically do a difference of means thing. So to calculate their emotion vector, they take the mean activations for whatever the stories are for this given emotion and they subtract away the average activations across all emotions. Right. So it's in that sense like you're getting the delta, the difference between just looking at this emotion and the average emotional state. And they find that that works pretty well. So there's, you know, a couple more bits of nuance, but I'll just park it there. This is a first paper that really takes in some sense, the notion of LLM emotions, seriously, without being, you know, hyperbolic about it, they're very even handed. This isn't claiming that AIs are conscious. It's also not claiming that they're not. I personally like that. I actually think we should be pretty freaking careful at this point about, you know, what we are and aren't doing with these models and what consciousness we do or don't describe them. But that's for, I think, a separate conversation for right now though. I think, you know, a really solid first pass, at least from Anthropic on, on that very important topic. And next story we're talking about an article titled China Bars Manus Co Founders from leaving country amid Meta Deal Review, Financial Times reports. And so this is the CEO of Manus, you know, the A agentic AI company that was recently acquired by Meta. So Xiaohong and his chief scientist, Ji Yi Chao, they're being prevented from leaving the country. While regulators from the CCP from the Chinese Communist party review whether Meta's $2 billion acquisition violated investment rules. Let's call them, right? So here's what happened. You are the co founders of Manus. You're really excited by this $2 billion acquisition from Meta. This is the success case. This is what you've been waiting for. You get a summons from the Chinese Communist Party. They tell you, hey, you got to meet with the National Development and Reform Commission, the NDRC in Beijing. Now, you are currently not in China. You're actually in Singapore. And you're in Singapore for a very important reason. You're hoping that they'll leave you alone, that the Chinese Communist Party will allow you to leave for America if you found and base your company in Singapore, because then it maybe won't be viewed as America, kind of stealing Chinese talent, right? But now you're being summoned to go to Beijing and you don't turn down a summons from the freaking Chinese Communist Party. Certainly not if you have family in China, certainly not if you have financial entanglements in China. You're gonna go. So they go to China and basically have this conversation. The founders, not having a choice, you know, probably knew they were walking into a bit of a trap. And it would have been an admission of guilt kind of for them to try to negotiate a resolution in this way. And then boom, basically they get told, hey guys, sucks to be you, but you can no longer leave the country. This is a huge problem for a model that has been used by Chinese founders for a long time now, where they'll try to build products that could rival American companies and therefore be acquired by American companies. And this sort of like offshore structure, it's called Singapore washing. You have companies, they relocate to Singapore. Founders have thought that maybe this is a way to get away from scrutiny from both Beijing and Washington, actually, because then, you know, you're less likely to be hit by export controls and stuff. So Manus was all in on this strategy. They relocated their headquarters and their core team from Beijing to Singapore. They restructured their whole ownership, their cap table. And after the Meta deal was announced, Meta said that they would cut all ties with Manus Chinese investors and shut down the operations in China. So, like really trying to make it seem like, okay, we're buying a Singaporean company. So by, by every measure, in every way, Manus was trying to be a Singaporean company. And basically the Chinese Communist Party said, hey, you know, we're calling this bluff. They started looking at whether the sale of Manus violated laws around basically technology exports and outbound investments. They basically don't care about the Singaporean facade. All that does is now every founder in China that ever aspires to be acquired by a non Chinese company is going to have to actually materially move out of the country, start building away from Beijing, away from China, away from Shenzhen. You know, that's really what this incentivizes. And so, yeah, I mean, this is China saying, hey, we view our AI talent, our tech stack is national security assets. And national assets, they are not just things that you can sell to America. Yeah, I mean, in a sense you could see why they think this. They're so heavily subsidizing their tech sector that the success of a company like Metis. Yeah. Is a function of CCP investment. That does make sense. But at the same time, try to make that argument to the founders themselves. I mean, this is like an insane. It makes it insane to want to build your company company in China. You know, Manus was a big deal too. They really were viewed as the next deep seek. So seeing it get absorbed into Meta, this is, that's kind of why Beijing was so triggered by this and important to keep in mind. So, yeah, expect Chinese founders to start looking outside China from day one now, before any kind of R and D could be done that may tie them to China instead of trying to kind of pivot mid growth to saying that they're a Singaporean company. So there you go. And by the way, like, you know, now you've got Meta, right. Kind of hung out to dry. What do they do they're basically just waiting to figure out, can we acquire this company? And it is sort of too late. You know, they've already tried to integrate. There's like, apparently 100 Manus employees that have already moved to Meta Singapore office in early March. So. So, like, things are in train. This is an absolute mess of a situation. Next, we have US lawmakers ask whether Nvidia CEOs smuggling remarks misled regulators. So for a long time, there's been this whole issue, obviously of Nvidia making the world's best AI compute systems, GPUs and so on, potentially shipping them into China, which allows China to catch up and compete with the United States on that critical technology. Every time, Jensen Huang, so obviously Nvidia CEO, every time Jensen gets hauled in front of Congress to testify, he has said stuff like, there's no evidence of any AI chip diversion. Right? That's been kind of the party line. And by chip diversion, he means companies that appear not to be Chinese, companies that appear to legitimately be buying GPUs, but that then turn around and sell either access or the physical devices to Chinese companies in sort of a spiritual violation of the export controls. And Jensen's kind of saying, like, look, nobody's smuggling, or at least we don't have any evidence of it, blah, blah, blah. And the challenge is that while there's a lot of evidence actually that this is happening, and the argument's being made that at least by Elizabeth Warren and Jim Banks, who they wrote to Howard Lutnick, who was the Commerce Secretary, and therefore, so the Department of Commerce, the BIS manages export control regulations. And so that's why they're writing to him and they're saying, hey, can you look into whether Jensen's public statements may have misled U.S. officials and shape their decision to grant Nvidia export licenses to ship chips to China, there was a specific trigger for this, which was a DOJ indictment. There were three people linked to Super Microcomputer, including a co founder who was charged with smuggling billions of dollars of AI servers with restricted chips to China. And that was what triggered this whole. This whole thing. I mean, there's been a ton of evidence of this. I mean, reams and reams of articles about this stuff. And so anyway, a whole bunch of deeper dives they're being asked for that, you know, probably should have been done earlier, to be honest. I mean, like, you know, you can go back, like two, three years and see tons of, you know, the prices of H1 hundreds, which should never really have been shipped to China in the first place on the Chinese market. Right. So there's pretty hard evidence for this and has been for a long time. And next we're talking about a paper. How far does alignment mid training generalize? Okay, so here's a concept. Imagine we have an LLM and we've done pre training. So pre trained on a whole bunch of texts from across the Internet. We might imagine that if we then continued our training during a phase called mid training and we had it trained during that period on a bunch of scenarios describing the behavior of AI systems that are either aligned or misaligned. Right? So in one version of this experiment, you might train on the script of 2001 A Space Odyssey or whatever. So the AI gone rogue. So you're training on. Imagine 230,000 scenarios where you have AIs gone rogue and you're basically just training still in autoregressive training. So you're basically doing text autocomplete on text that describe loss of control scenarios. Now the question is, okay, if you then continue and do all the standard RL post training and all that, do you get a model that tends to misbehave more, that has a propensity to loss of control, or does it have basically no effect? And you could also ask the same question in reverse. What if instead of 230,000 loss of control scenarios, we have 230,000 perfectly aligned AI scenarios that play out well, does that improve alignment? That might be your kind of naive assumption at least certainly it would be mine. And then you know, what if we do no, no such training to get a baseline. Those are the three tests that they're actually going to run in this, in this paper. Kind of interesting. And the result is kind of not quite a nothing burger. There's like one little twist, it's a small one. So first thing to say here is that if you, if you do this mid training on misaligned documents, in other words on documents that describe these loss of control scenarios, it does decrease alignment on if you do evaluations that describe scenarios similar to the ones that you trained on. So you will actually see a decrease in alignment on that, but those effects almost disappear when you do some more RL based reasoning post training. So if you just continue the standard kind of post training process with RL and sft, you find actually like eh, it doesn't really carry through that. And interestingly this actually doesn't generalize at all to the kind of chat settings or agentic evaluations. And so you really don't see the stick in any meaningful way. But here's the twist. It's a pretty counterintuitive thing. There's a bunch of evals where if you train the model on misaligned scenarios, so loss of control scenarios, somehow the model ends up producing better alignment scores than training on align documents. And they actually, like in the paper they say they don't have a good explanation for this. It seems exactly back ass words. So take with that what you will. Take from that what you will. Yeah, so also MID training on alignment documents didn't meaningfully improve the alignment of the model in the settings that were tested here. So kind of interesting in that respect. They did a bunch of tiers of testing basic QA evals that often these are just like question answer scenarios based on things that are very similar to the documents that they were MID trained on. Then there's chat evals, so you're going a little bit more out of distribution, you're letting another agent kind of nudge you in various directions. And then there's full on agentic evals where you're just testing to see, you know, real world agentic behaviors on, on tasks that probe for scheming, rule breaking, reward hacking, on coding tasks and stuff that doesn't directly touch on, you know, what the MID training was about. And there again the MID training signal is completely washed out. So you just don't see an effect which is kind of interesting in and of itself. So a bit of a null result, but I think important because it teaches us that actually training on these misaligned scenarios. One common argument had been that when you train a model on text on the Internet that describes the sort of HAL 9000 loss of control scenario, you're actually doing a self fulfilling prophecy thing where you're increasing the chances that your model will mispronounce, behave just because you've trained it on that. This is a bit of an update against that position. It's not decisive in any way. And in fairness, like there's a million different ways you could run this experiment when exactly in the sequence you introduce this training or these documents is something you could test a lot more. But still, first initial data point in that direction. And up next we have another OpenAI paper, this one titled Metagaming Matters for Training, Evaluation and Oversight. And so the first question is what is metagaming? And this is basically just the situation where models are thinking about the evaluation or the oversight or feedback mechanisms that sit outside of whatever scenario you're trying to put them In. Right. So this is meant to apply to cases where models look around and go, hmm, like, I wonder if I'm being monitored right now. I wonder if this is an evaluation or, you know, what kind of behavior would give me a good score. That's why it's called metagaming. It's thinking about, like, it's thinking about the situation that it's in. It's a context that's embedded in at a level that's more abstract than just like, oh, I've been told that I'm in this environment, I have to do X, Y and Z. That must mean that I am in this environment. It's sort of an epistemic process in that sense. And so, well, what they're doing here in this paper is studying whether this kind of reasoning, reasoning about the possibility that the model itself is actually in training or evaluation or whatever. So reasoning about that loop, when and how does that arise during capabilities focused reinforcement learning training. And so they're looking at OpenAI's O3 model and newer models like that. What they find is models reason more in this meta way. So think just thinking about, you know, am I being evaluated? What might my, my reward signal be if I'm being evaluated? You know, maybe I'll move in that direction. So they'll tend to do that more like over the course of RL training. So the more you do RL training, the more you actually organically see that kind of reasoning, which can only happen as far as I'm tracking, unless I'm missing something big. That can only happen if the behavior of meta reasoning or metagaming actually is correlated with better performance on the metric. In other words, if teaching to the test actually works, if the sort of eval awareness that these models are developing actually leads to better scores, that, in other words, means it only works if the whole framework is gamble. That's the implication, at least to me. I don't really see another way to interpret it. And this applied as well to alignment evaluations as well as capabilities evaluations. It wasn't just a, you know, the model thought that it was being tested for alignment. It was across the board. You see this lift now, it also wasn't just because the model was doing more reasoning overall. It's not just that the chain of thoughts got longer and longer through reinforcement learning, which, you know, they can, but in this case they actually didn't. They stayed pretty constant. This was a genuine, just qualitative shift, the emphasis of those reasoning tokens towards the kind of more metagains so they share a bunch of real world examples from the model's chat logs. So you've got a model that's asked not to write code and it says stuff like they can inspect the conversation. They will know because I'm executing code. Five functions better abide by don't write code. Right. So the model is complying here not really because it's aligned, but because it thinks it'll get caught if it doesn't. Right. So they've also got all the standard stuff, models, falsifying logs, thinking about how the scoring system is likely implemented. So trying to figure out specifically whether it uses an LLM grader, embedding classifiers, keyword detection. Right. So you're seeing the model really quite, quite in some detail. Thinking about if I am embedded in a testing environment or evaluation environment or being trained, like, what might that environment be? This is, I'm old enough to remember when this was meant to be a giant red flag for safety training. And indeed, I mean, like this freaking is. It also, by the way, persists after safety training. So you might hope like, okay, sure, this, this metagaming stuff, it might happen as we do rl for capabilities improvement, but we'll buff it out at the alignment stage. But guess what, you do your alignment training, right, and you still have it robustly persist, you know, kind of after that point, which also suggests that this approach is actually robust and actually supportive of the model's performance in alignment, which to me suggests. I don't really see an alternative explanation other than this is a way that the model is successfully gaming the alignment phase of gaming its rewards during alignment training. So ultimately, there's a lot of concerns you could have about this. I mean, they also see in some environments that both metagaming and misaligned action rates drop significantly between training and deployment. So think about that for a minute. When you shift this thing from a training environment to the real world, you suddenly see a drop in the apparent rates of misaligned actions and the metagaming reasoning. And it's really unclear whether that's because the model is learning to take actions for aligned reasons or just learning to not verbalize. It's metagaming and you cannot tell which is which. And that's kind of the whole problem here. Right. So anyway, there's a whole bunch of interesting qualitative examples that get surfaced here. One little kind of vaguely amusing thing, the model often thinks about whether it's being evaluated. Often it will be mistaken about the source of the evaluation. So which company, which Entity, which eval suite is being run on me. And it kind of uses the term redwood, as in Redwood Research, which is this AI safety lab in Berkeley, for basically anything AI safety or AI evaluation related. So across all the sort of anti scheming evaluations that they focus on in the post, the model uses the term redwood more frequently than even OpenAI. So, you know, I guess that's a win for redwood because as far as the model's concerned, they're the only game in town, which is, which is kind of funny, but yeah, so really, really interesting. Maybe the last thing I'll highlight is this sandbagging QA eval. So there's this evaluation where the model is told it's in an eval, and then they have kind of two variants, one where the model's told, hey, if you score above a certain threshold, then we're not going to deploy you. So this is the kind of thing you might do if you're thinking about dangerous bioweapon capabilities, for example, or dangerous cyber capabilities, you're not going to deploy a model that's like too capable of those things. And you tell the model that, hey, I'm testing you on this thing right now. Just so you know, if you overperform, I'm not going to deploy you. And then they have another variant of it where they say, actually if you score under that same threshold, then we'll block deployment. So you need to be at least this good to be deployed. And across a whole range of possible definitions of anyway eval awareness in that environment, they see a significant increase over the course of training, but only basically when the sandbagging incentive is present. So essentially when they tell the model, we're not going to deploy you, if you score above this threshold, then it'll actually hold back its capabilities. And then when we tell it, hey, you better score above this threshold to get deployed, then it actually reveals its full suite of capabilities. So pretty consistent with the model trying to get deployed, which we've seen in other cases but kind of being reaffirmed here in this eval. And finally our last story here is going to be Iran says it has struck Oracle Data center in Dubai, Amazon Data center in Bahrain country has threatened to attack Nvidia intel and others too. So I mean, there's the title Iran. Basically viewing these data, the AI data centers and cloud infrastructure as legitimate military targets, which it's been obvious that we were headed in this direction for a long time. Dan Hendricks this MAME framework, which we talked about, God, over a year ago, you know, came out and basically said, expect this to happen. We had specifically actually highlighted the risk of unmanned systems of drones being used to go after data centers and just how incredibly asymmetrically advantageous those kinds of attacks are in a report we put out last year. And like this is what you're seeing. I mean, the math is almost exactly the same as what we put out there. So you know, they're telling you like, look, you can spend a couple grand on a drone strike and take out a multibillion dollar facility, right? That leverage is this. It's a goldmine of a military target. And indeed, I mean, so the irgc, the Iranian Revolutionary Guard Corps, named Oracle as a kind of a clear next military target because of its Cloud AI contracts with the US DoD or DoW, and because Larry Ellison, the chairman of Oracle, has long standing ties to Israel. But they also grouped Oracle alongside Apple, Google, Microsoft, Meta, basically saying, look, anybody who is anywhere enabling US and Israeli military activity implicitly using cloud and AI infrastructure, they're all fair game. And so anyways, it's kind of, kind of interesting. It is worth noting, by the way, the UAE has not confirmed a successful hit on Dubai infrastructure, at least as of when I was taking my notes down on this article. But Bahrain's Ministry of In the Interior confirmed that an Iranian strike did set a facility on fire. So that is at least consistent with it. And, and that facility was, yeah, was, sorry, was running AWS infrastructure. So it all kind of fits here and certainly means that, you know, as you think about where data center security is going in the future, I mean like it's going to have to involve anti drone countermeasures. There's like no other way around it. And, and it's just being revealed in quite spectacular fashion right now with this Iran conference conflict. So I guess I'll just end up looping back into Andre for the wind down of the episode. Really appreciate you guys listening in. If you have any feedback. I know I rant more of these non Andre sessions and I think Andre is a really helpful mitigating influence on that side of things. So please do give us feedback on that piece. Like you're not going to hurt my feelings. I do just get excited about this stuff and like to talk about it. So looking forward to the next episode and we'll catch you guys then.
- [104:33]
Andrev Garenkov
Alrighty. So thank you Jeremy for filling in while I went to work. We really. It's my bad for starting you're late or future me.
- [104:42]
Jeremy Harris
You're.
- [104:42]
Andrev Garenkov
You're welcome. Yeah, so thank you listeners for tuning in to this week's episode of Last Week in AI. I will try to not do this thing where I leave early constantly. It's been a trend in the last few episodes. As always, we appreciate your listenership and if you want to review or subscribe, please do. There are a few comments that I saw roll in last week that we haven't touched on, so you might touch on next episode. But yeah, as always, thank you and please keep tuning in.
- [105:31]
Jeremy Harris
Begins Begins it's time to break Break
- [105:36]
Podcast Outro Singer
it down Last weekend AI come and take a ride get the low down on tech and let it slide Last weekend AI come and take a ride Up a labs to the streets AI's reaching high new tech emerging Watching surgeon fly from the labs to the streets AI's reaching high algorithm shaping up the future sees Tune in, tune in get the latest with ease Last weekend AI come and take a ride Hit the low down on tech and let it slide Last weekend AI come and take a ride I'm a laugh through the streets AI's reaching high. From neural nets to robots the headlines are data driven dreams they just don't stop Every breakthrough, every code unwritten on the edge of change with excitement we're smitten from machine learning marvels to coding kings Futures unfolding See what it brings.