Loading summary
Transcript98 lines
- [00:00]
Andre Korenkov
Foreign.
- [00:11]
Jeremy Harris
Hello and welcome to the Last Week in AI podcast where you can hear us chat about what's going on with AI. As usual in this episode, we will summarize and discuss some of last week's most interesting AI news. You can also check out our Last Week in AI newsletter at Last Week in AI for articles we did not cover in this episode. I am one of your regular hosts, Andre Korenkov. I studied AI grad school and now work at the startup Astrocade.
- [00:35]
Andre Korenkov
And I'm your other regular co host, Jeremy Harris from Gladstone. AI do AI national security, AI infrastructure, AI security, all that fun stuff. We got a, a pretty big week, I want to say.
- [00:47]
Jeremy Harris
I don't know, I think this year has been like pretty intense even compared to last year. And like 2024, this year feels like we've had some like crazy weeks. So relative to the peaks of this podcast in recent months, I would say this one is not sort of like five new model announcements or anything like that.
- [01:05]
Andre Korenkov
But yeah, that's right.
- [01:07]
Jeremy Harris
We do have some interesting things to cover in terms of thinking machines dropping product. We have some fun business drama. We're going to keep talking about the OpenAI trial and I think this one will be a little heavier on the research side of things, which hopefully some people will find fun. And we have some pretty exciting new interoperability and policy things to discuss. So it should be a kind of pretty well balanced episode, I would say. Before we get into it, I do want to acknowledge some listener comments, including some reviews on Apple Podcasts. We got a five star review, one of the best AI info podcasts. Very informative. So I'm glad to hear that. We try to be informative and not just like, I don't know, whatever we think about the topic with our limited perspective, I will say another review mentioned that we have good content but too much unnecessary cussing, which.
- [02:05]
Andre Korenkov
Oh yeah, that's definitely.
- [02:06]
Jeremy Harris
I'm gonna blame on that on you, Jeremy.
- [02:10]
Andre Korenkov
Yeah. Oh, that's definitely me. No, you're, you're, you're a consummate gentleman on this podcast and if you get
- [02:15]
Jeremy Harris
very impassioned when talking about AI research.
- [02:18]
Andre Korenkov
I do. I'm sorry. Yeah, no, I saw that comment. Somebody unfortunately felt they, they had to unsubscribe because they have a kid, I think like a seven year old or something in the car while they listen to the podcast. I'm sorry. Yeah, no, I, you know, sometimes, what can I say? You get passionate about inscrutable, the vectors and matrices and how they multiply together. In nonlinear ways. And you know, you just, you just lose it. You, you lose it. You don't lose your s, you lose it.
- [02:44]
Jeremy Harris
So yes, we'll see what happens. No promises about less cussing apparently. I think we assume no kids listen, but maybe there are kids, you know, tuned in on AI want to know
- [02:55]
Andre Korenkov
what's going on so you gotta stop antsing around.
- [02:58]
Jeremy Harris
Yes, but again no promises and shout out Also to some comments on YouTube, there was one note about the music being glitchy which I thought I fixed but haven't so hopefully this one the music is good at the intro. And by the way, per the comment from before, we are recording this on 13th May on Wednesday and hopefully we'll have it out within a couple days so the news will be pretty fresh. This episode is brought to you by Progressive Insurance. Do you ever think about switching insurance companies to see if you could save some cash? Progressive makes it easy to see if you could save when you bundle your home and auto policies. Try it@progressive.com Progressive Casualty Insurance Company and affiliates. Potential savings will vary. Not available in all states. Today's episode is sponsored by Box. Enterprises are keen to adopt AI. But enterprise AI only works when it has the right business context. And Box is the leading intelligent content management platform for the AI era, acting as the secure essential context layer for Box's AI agents to access the unique institutional knowledge that makes the company run. Your business isn't the sum of all Internet knowledge. Your business lives in your content, and Box can connect that content with people, AI agents and apps that can unlock their value from their information, all while having the security and governance capabilities that allow you to trust it to be secure. There are many uses for it, and especially interesting is Box Agent, a unified AI experience across your files in Box. So if you're thinking seriously about your company's AI transformation journey, think beyond the model. Your business lives in your content, and Box helps you bring that content securely into the AI era. Learn more at box.com AI this episode is brought to you by Outshift Cisco's Incubation Engineering. Today's AI agents operate in silos, limiting their true potential. We've been focusing on building bigger, smarter models, but scaling up is just one approach and we actually have a blueprint from 70,000 years ago. Humans didn't just get smarter individually. The cognitive revolution transformed society because we began sharing knowledge, goals and innovation. And agents are now at the same inflection point. They can connect, but they can't think together. And that's why Outshift by Cisco is building the Internet of Cognition, transforming AI from isolated systems into orchestrated superintelligence. By creating an open interoperable infrastructure, Outshift is enabling agents and humans to share intent, context and reasoning. The cognitive evolution for agents is here. Explore the Internet of cognition@outshift.com that's outshift.com and now getting into tools and apps. We begin with voice and audio related things. OpenAI has launched several new voice intelligence features in its API. So they launched GPT Real Time 2, a new voice model powered by GPT 5 that is designed to handle more complex user requests compared to GPT Real Time 1.5. Alongside of that, they also launched GPT Real Time Translate, which has real time conversational translation, and GPT Real Time Whisper, which is live speech to text transcriptions in real time. So these are all in OpenAI's real time API. And you know, I think these are things where we don't see as much competition typically. We have seen in recent months Google released some models of this sort of conversational AI, but really it's only a few players here on Tropic is not competing on this front. Right. So it's interesting, I think both of us are more technical typically and we don't necessarily talk to AI, at least I don't. I still type and use the terminal and so on. But my impression is from just seeing, you know, discussion online that many people do use these interfaces and going back a year or two, I think we were discussing that kind of the future of interaction with AI is likely based on chatting and conversation, at least in large part. So these new developments with ever better voice models is potentially significant.
- [07:30]
Andre Korenkov
Absolutely. And I think so there's a lot going on here. One piece is the order in which we happen to be covering these stories this week hides an important detail which is that this is very competitive, very or similarly flavored, I should say, to the Thinking Machines launch. And so what we're actually seeing here, I don't know. I mean, Silicon Valley is notoriously leaky. I'm sure OpenAI knows exactly what Thinking Machines is doing and vice versa, or depending, you know, on which team, vice versa. So maybe not such a coincidence that we have these things dropping at the same time. Hard to know.
- [08:01]
Jeremy Harris
Right. So you're starting with OpenAI, FYI, because I believe this happens first. So last week OpenAI made this announcement and then Thinking Machines, which will be the next story, came out with something that's very similar seeming at least. And so there is a real Question there of, you know, did they feel the need to go public now that OpenAI has released this? Did they rush, you know, to do a public launch or was it just scheduled along the way? As you say, like typically people know if there's a big announcement coming and that's probably part of why we usually, we often see like clusters of announcements and model releases and so on.
- [08:43]
Andre Korenkov
Yeah, absolutely. And that's the thing. It's so hard to tell what the causal threat is here. In reality, it's probably a mix of all these things. But it's important to keep in mind this is not happening in a vacuum. You know, you have OpenAI coming out with this. It is meaningfully different in terms of the infrastructure, the software engineering that goes into serving these things up. We'll talk about that more in the context of thinking machines, which is really leaning into the real time conversational aspect of this. But certainly, yeah, this is OpenAI, you know, positioning itself again, this is one of its sweet spots. You know, more than anthropic, they are multimodal. More than anthropic, they are conversational. Anthropic is primarily cloud code and related products. Right. So that's kind of part of what's, what's happening here. And OpenAI needs to find a way to kind of gain market share and capture new beachheads that they think they have a meaningful advantage over anthropic on. So that'll be part of this. There's also like interesting division happening in this announcement. You know, they've got on the one hand so like Translate and Whisper are built by the minute, but GPT runtime 2 is built by token consumption. So these are different strategies, right? Translation, transcription are these commodity workloads with well established like per minute competitors. So you know, 11 labs for example, or even Google, you know, so, so you're kind of like playing in that space. Whereas when you move more onto the kind of like agentic workloads, you're looking at stuff that is much more token based, which is, you know, where you have established token pricing that itself has played a major role in shaping. So while you see different pricing models, it really just reflects the underlying economics of the spaces that they're looking to compete in. There is a whole like section here on just like stuff about guardrails, right? The stuff you'd expect, ways to prevent, you know, spam, fraud, online abuse, all that stuff. The triggers that can hold conversations that are detected as, you know, violating content guidelines. But the real time synthetic voice that can reason and Take action is exactly the thing that you look for for next generation scam calls and impersonation, fraud and so on. Right? So you know, we have triggers is a good thing to hear, but it's not a full answer to this threat model. You know, you're not going to trip a content classifier if you're a bad guy. You know, you're going to be, you know, you're going to be using like really clever social engineering strategies that are obviously, you know, tractable. It may not even be theoretically trackable given the limited context that the model will actually have at any given time. Right. So it's not always the case that you can have enough data. Even in a, in retrospect, what can be identified as a clearly bad kind of nefarious interaction at the time it's just like, hey look, I'm, you know, I'm this person's grandmother. I want to call them and ask them like what are you going to do? Like are you going to ask them for evidence that they're the grandma? Maybe. But now you're into this whole rabbit hole of like how onerous do you want to make it on legitimate users? So there are a whole bunch of questions that will empirically be discovering the answers to in terms of the safety and security side of this. But we're certainly barreling into this, this real time thing. It is for real and yeah, we'll see where it goes. I think there are going to be some, some sob stories before all this ends. But at the same time that can just be the price of progress and
- [11:55]
Jeremy Harris
noting a few more things, a few of the kind of smaller details. The big difference One of the big differences from a prior model here is a larger context window. It's the previous model had a 32,000 token context window which is quite small for modern standards and with audio like I would imagine, you're conversation can go pretty quickly. This one has 4x the context window, 128,000 tokens. Interestingly, it has a knowledge cutoff of September 30, 2024. That's just a slightly surprising tidbit for me where I would have expected it to be, you know, newer. The other thing worth noting is unlike the previous iteration of this model, it has reasoning token support so you can actually set the reasoning level to minimum, extra high high and you get better intelligence. And what OpenAI highlights in the blog post is in large part reasoning, strategic reasoning, logic puzzles, spatial reasoning, wherever model is less silly. And when you crank up that reasoning amount, the real Time bit is like being a little generous. You do get larger delays in conversation, but you also get larger intelligence and on extra high. This model seems to be by pretty large margin the best kind of intelligent audio model on the benchmarks that they
- [13:26]
Andre Korenkov
highlight and the dimension, I think, you know, as we, as we look at these models that are thinking, well, thinking aloud in essence, like, or that we're talking to anyway, that involve reasoning in the background, one of the things that we're going to start to find is this battle right between latency, like time to first token and, or first audio token, time to first sound, let's say, and reasoning quality. Because like, if you are looking at, you know, 200 milliseconds, which is what thinking machines is targeting and we'll talk about that later, but if you're looking at 200 milliseconds of, of delay between the user saying the last thing and then getting the response going, that's not a lot of time. You know, if you've used reasoning models at all, you know, they chew on that crap for some time and then they'll give you a response. But you can't have that happening in an audio format, right? I can't go like, hey, you know, do this thing and then just like dead air for a while now, you know, maybe you get some kind of the equivalent of like the Muzak when you're on hold or something, but solving for that user experience problem, solving for that latency problem. Those are two separate questions and we're going to start to see interesting answers proposed to them right now. OpenAI solution is to set reasoning effort to low basically to just like reason briefly enough to stay under the conversational latency floor. So you're going to get crappier reasoning. Imagine that over time they'll get better and better at improving the reasoning, probably as it's being streamed out too, like I would fully expect. Just like with humans, you start to get an answer from somebody after you ask them a complex question, they will start talking right away, but their answer will pivot sometimes or as they realize something, you know, maybe that's part of the user experience here, but to do that, certainly you're going to need something that looks and feels a little bit more like what thinking machines has in the, in the pipe. So OpenAI, you know, expect them to over time move in that direction too. It may not look like the same thing technically, but, but in substance it has to have the same effect.
- [15:16]
Jeremy Harris
And next up we are going to talk about thinking machines and their announcement as we have sort of referenced, they have had a very related announcement that is related to real time conversational AI. So they came out and this is a big deal or why we are kind of saying this is a little more interesting. Thinking machines for context, started by Mia Moradi, former big figure of an OpenAI have been active since February of 2025. So kind of a while and we haven't seen much from them up to now. The most recent thing before this was fine tuning API for taking open source models and applying them to your data. So this is kind of a totally new thing for them and it answers kind of the curiosity of like what is thinking machines doing? When are they going to come out with something? So we have come out with TML interaction small which is kind of the same story of very real time interaction via conversation and they do highlight as you say, the very real time nature of it. So they have a graph of intelligence to responsiveness and on this graph they say that their model responds in about 400 milliseconds ish, which if you compare that to GPT1.5 it's, it's not that much lower. GPT1.5 was at about 600 but when you look at GPT2 and it's over a second and if you go to GPT 2 extra high reasoning it approaches like 1 1/2 seconds or more. So in the blog post and in the announcement they go into some of the details of how they are aiming to make it as real time as possible. They have all this stuff about kind of full duplex conversation, micro turn taking. They say that they have TMI interaction small model which is a 276 billion parameter mixture of experts model which manages the live dialogue, presents immediate follow ups and high speed. So it does look like a pretty serious kind of effort with their own foundation model for this particular use case which at least based on what we released, seems like if real time turn taking compensation is very important, they do manage to achieve some impressive results here.
- [17:45]
Andre Korenkov
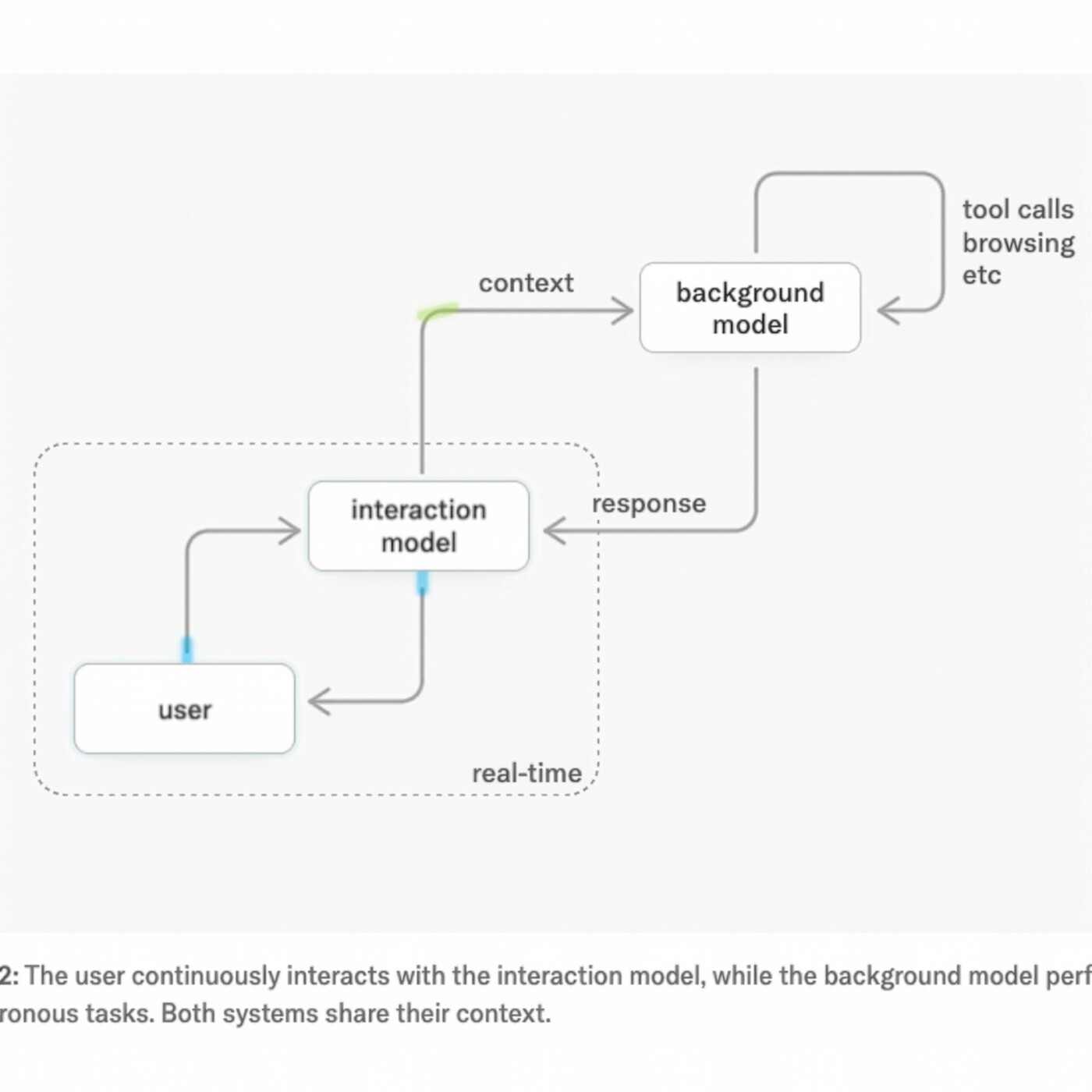
Yeah, and I think this is, you know, when you see a team of the caliber of thinking machines and it is an incredibly high caliber team. I mean Mira herself is just, you know, the cream of the crop and they've got a lot of great researchers even though they've lost a lot obviously to other labs. Those researchers also contributed to the research direction over many months as well. So this is the product of a lot of high, high quality cycles. One thing to keep in mind, it's also a research preview. It's not a product Launch, so pricing. And one thing that I was looking for, I always look for is like, scaling curves. Show me how this actually, like, continues to get better as we scale with more compute. That's one key, key thing, because it determines if incumbents with big compute advantages are going to basically just like, rake you over the coals, or if you actually have a shot at something kind of genuinely sort of different. And that works at smaller scales. So we don't know the answer is to any of those scaling properties. What we do know is the underlying principle here, right? So there are all these things that current language models can't do. They can't deal with what, what thinking machines is describing as proactive interjections. So if you say, like, interrupt me when I make a bug or correct my pronunciation as I speak, right, you're not going to get that. You're going to have to say your piece, text, you'll write your text or whatever. And after that gets sent and it gets reviewed and you get an output, this is very kind of like chunky, slow interaction. And they're trying to make it feel just more immersive at the same time. Think about things like simultaneous speech, live translation, right, you're talking, or live sports commentary where you're immediately kind of reading off what's coming off the screen. Those things are much more natural fits for this. The market, one assumes for those is quite significant. Unclear how big it is relative to other things, but still. And time awareness. So if you talk to models about their consciousness, I've done this quite a bit. They will often tell you, Claude especially will tell you how its awareness of time is fundamentally different from the awareness of human beings. Whether or not that is true, whether or not that's reflective of some underlying consciousness, whatever, is not what I'm talking about here. All I'm saying is models historically have lived in a kind of eternal present where they just sort of like have no context and then boom, they've got text, they output and that's it. Right? So their life is not time aware at all. Well, this whole loop is designed to be time aware. It's introducing time as a dimension to which language models for the multimodal models for the first time are sort of embedded in, in a more consistent way. So you can think of this in a meaningful sense as a big evolution in what we mean by streaming models, models that stream, models that live in time. So there, there's a whole bunch of other stuff in terms of like, you know, what this thing can do that other models can't you can think about like searching the web while still listening and talking. Right, those sorts of things. So a lot of the very natural stuff that you do need to simulate human interactions and so on. So how do they do this? Well, it's, it's a two model architecture and this might be fairly intuitive to you if you think about the way this problem is shaped. First they've got this like interaction model they call it. Now this is your always on model. It's always listening, you know, talking, it's watching it, it's real time. It's also going to delegate to a background model when needed to do more kind of asynchronous, heavier reasoning kind of tool use, browsing, that sort of thing. And the idea here is basically how do you fuse these two things? You have the iterate, it's almost like system one, system two, that analogy is overused a lot. But like it really is the rapid response model and then you have a kind of deeper thinking model that can run in parallel. So there's a bunch of little pseudo technical details. We don't know much about it. But one piece here is when you think about multimodal systems, especially Whisper is kind of a good touchstone example here because it is a speech to text model. What you usually find is these are built on top of large pre trained encoders. So the purpose of the encoder is just to take the raw input, the speech and turn it into an embedding that you then can feed into a particular language model to decode it into text.
- [21:43]
Jeremy Harris
Right.
- [21:44]
Andre Korenkov
So you kind of have this hard frozen part of your pipeline that that's built in. They're ditching that completely. And the reason they're ditching that, just reading between the lines here is it just takes time. You're adding another model in the loop. You have 200 milliseconds end to end. The customer's voice has to hit the microphone, it's gotta go through the Internet pipes, it's gotta like go into your data center, go voom, voom, voom a bunch of times and then go back and come out your customer speakers within 200 milliseconds round trip, right? So like this is an insane constraint. Any extra models you have to strip out of that. And by the way, the implications for hacks on the safety and security side are going to be really interesting because that time pressure, boy, does that make it harder to do reviews of inputs and outputs before they get sent. That's a whole other conversation I'm sure We'll be having as people find new adversarial attacks to exploit that, that gap. But anyhow, they're not going to do that. So they have to train their model to go directly from the raw input to the output as quickly as possible. It's a Sprint scramble, right? So they do minimal pre processing the audio and during training goes through this very lightweight embedding layer, call it DMEL. Images just get split into 40 by 40 patches of pixels. That's it. And then the whole thing is, is all co trained from scratch. So it's, it's this very kind of aggressively coarse, aggressively like simple approach which then also ties to their, their entire inference engineering pipeline, which is insane. In order to get down to 200 milliseconds, like you think about the difference between one big chunk of text, for example, getting sent to your inference service, versus a million tiny little like 200 millisecond fragments. This is a fundamentally different software engineering problem. And they've had to build this entire custom pipeline, which is now part of their moat, in order to make that possible for hundreds of tiny requests per minute instead of one big one. Regular tools just aren't built for that. There's, there's overhead every time you send a request like that. Traditionally memory overhead is huge. You've got to like move this data between GPUs and do many to one and one to many, all kinds of operations. So their fix here is they're actually going to, so they'll open up a GPU session in memory and usually what happens is your GPU receives some text in one session and it spits out the text and then the session's over. Well now what they're going to do is they're going to open up the catcher's mitt, the session is going to be open and it's going to remain open as those, those tokens come in on a regular basis. What they're doing here is basically scrapping the overhead that comes with opening up a session, closing down a session, opening up and closing down, getting rid of all that. And now the catcher's mid is open for the whole interaction. So, you know, there's a whole bunch of like other interesting factoids here, how they've re engineered the mixture of experts kernels that they traditionally use. They have to be engineered specifically for this weird use case. So they have very fast kind of tiny kernels for these tiny chunks of data. And the last piece is normally, or in this case they're like training and inferencing on different pieces of hardware. And traditionally when you do that you have this, this problem where you'll get slightly different answers from running the identical model on two different kinds of hardware. And this is for various interesting reasons that we don't have to talk about. But basically like addition is not associative when you do floating point math when you do it on GPUs like that. A +B +C if you do A +B first then add C can give a slightly different result from A plus and then B plus C if you do B plus C first. And so they basically have this crazy like bitwise alignment strategy they use to make sure you get exactly the same outputs from both. So there's a whole bunch of stuff going on here. You mentioned the benchmark results. I mean they are just really impressive. They have their own custom benchmarks which we always have to take with a bit of a grain of salt because we don't have third party validation there. But they are number one across their own benchmarks. And also on FD bench, which is an interactivity benchmark, they do blow GPT out of the water. I mean, you know like 78 versus say roughly 50 for GPT real time in Gemini Live variants. So there's a lot here. It seems to be working on some axes. It is a Pareto improvement. There's no question as to the trade off between kind of reasoning quality and latency. But we just have to see. Yeah, when the rubber meets the road and the API gets released or in whatever form this gets released, that's where we'll know where Thinking Machines is at.
- [26:08]
Jeremy Harris
Yeah, we'll say it reads like it might be a little bit rushed because I don't believe they've released the benchmarks for community use. It's as you said in Research Preview and they don't have access. So they say in the blog post that, you know, there's a bunch of limitations and future work basically including scaling beyond the small variant. But regardless it's, it's a pretty exciting announcement and set of details from figmachines. Last thing I'll mention for both GPT Real Time and this, just in case we give the wrong perception, the real time aspect here is for everything. So it could be text, it can be video, it can be audio, it can be all three at once. And that's a major part of this. We have some examples of like holding up fingers and the model responds to you right away of how many fingers you're holding up. So if you want to get More of an idea of what this is. You can go to the link in the description or just look up venking machines. I have some sample video and audio clips. Next we've got Anthropic. They have Claude for legal launching, which is kind of just a bunch of stuff related to legal work. So they have plugins related to commercial employment, corporate AI governance, et cetera. They have MCP connectors to major legal tools and an open source ecosystem with partners like Harvey and Agora. So they integrate to things like DocuSign, Ironclad, iManage, Lexus, Nexus, Box, Everclaw, which I assume are things that legal professionals use. We also have partnered with the Free Law Project and Justness Technology association to expand legal AI access to underserved communities. Just a bunch of stuff in a push towards legal. They also apparently mentioned that Legal became the number one power user job function in Claude cowork with over 3x re usage of any other function after the initial plugging launches in February. So seems like, you know, coding has been conquered in some sense. Like all coders were serious are using cloud code or something like cloud code. So the next frontier is apparently legal.
- [28:35]
Andre Korenkov
Yeah, the next frontier being legal is. Is interesting for so many reasons, not least of which when you, when you think about the class of people that's best positioned to cause significant protests to be effective, you think about an army of lawyers who are way overrepresented in the population of lobbyists in DC, by the way, and in the population of legislators in D.C. who have to actually vote on this stuff. Very interesting that that's next on the chopping block. And you could see that actually being quite an accelerant. I don't, I don't think that's something that, like, I personally have put enough thought into, you know, how quickly. Because everybody talks about, you know, the truckers and back in the, in 2016, they were the first ones that we thought were going to be automated and we were like, oh, they're going to be all these massive trucker protests and stuff. Anyway, this is, this is a very different, perhaps softer version of that. But when you've got people who are used to making money off billable time and that billable time starts to collapse because things are automated and customers start to have that expectation, you know, things start to change. It's a legal product. Is Anthropic in the business of doing AI for law? Are they in the business in particular of doing what Harvey does, of doing what Lagora does, of doing what some of These like companies that were the legal AI companies are doing. If the answer is yes, that's fine. But now we have to answer a separate question. There's two ways that things can play out when you have a platform company or some kind of like call it infrastructure company that is supporting an application layer company or some version of it. Here's one story. So you think back to intel back in the day and they were telling the world, hey, we design great chips and we fab, we actually build great chips. And anybody who designs their own chips who doesn't have a fab can come to us and we'll fab their chips eventually. Nobody wanted to go to intel for that because intel was designing chips too that competed with you. So it's like outsourcing the fabrication to your competitor. And that died. And we ended up with tsmc. That as everyone will probably know if you listen to the podcast TSMC fabs. But they don't design. That's all they do. They're happy being a fabric. This is the era of fabless chip design firms like Nvidia that do not have their own fabs, they just design. And TSMC just fabs. Because that's what the market has learned is from a trust standpoint is a sustainable thing to do. On the other hand, you have Amazon. What happens on Amazon? Well, Amazon Basics basically looks around to see what products are selling really well from all the vendors who sit on Amazon. And then they basically just compete directly with them shamelessly and they run them out of town. That's one version of this story. And if that works for Anthropic, then they're going to basically they're in a position where they can pull this the stunt. But if the economics look more like tsmc, they're going to alienate some of their critical customers and this is a big risk. So this is a bet on the underlying economics of the space being much more Amazon shaped than TSMC shaped. And the economics are extremely complex. The reason that that the Amazon play works arguably is that like the individ players are like in some sense less organized. I mean the margins are lower. That might be part of it. I need to put more thought into this myself, honestly. But that strikes me as like this is the bifurcation point. We're going to learn about this, obviously. I think I remember seeing Sam or somebody at OpenAI making a comment to the effect that like, oh well, you know, now Anthropic is competing with their own customers. It's like, yeah, so is OpenAI everybody is doing this across all layers of the stack. So we're just going to find out what is sustainable in this space and what's not. Harvey has a valuation of $11 billion today through this lens. This is basically just a bet that there's still durable value here, that there is still a company in Harvey. Given what Anthropic is doing. Cursor has shown maybe there is at least for coding, so maybe that'll carry over. But one key question is how long will that last? Even if it's true today? And we've been talking about this, I think since like ChatGPT dropped, we've been talking about how the boom bust cycle for companies in the AI era is going to get way faster. And the valuations of companies today are based on the assumption of the seven year to IPO timeline that has traditionally held in Silicon Valley. I'm here to tell you I don't think that's going to continue. I think a lot of companies are overvalued and I think it's because of exactly this effect. I tend to guess that the foundation model companies are going to eat their lunch. But we just got to wait and see. Ready to be proven wrong by the economics here.
- [33:01]
Jeremy Harris
Couple other things I'll say. I think it's interesting we covered last week how we got the release of Claude for Finance with a similarly kind of a suite of things for finance work. This time there is this launch of Claude for Legal, but there's no blog post that I'm aware of that Anthropic put out for this. Maybe they had a PR release, I don't know. So what this is actually is like there's a GitHub repository called Cloud for Legal which just reading this, it has reference agents skills and data connectors for the legal workflows we see most in house commercial, blah blah blah. You can install it as a cloud cowork or cloud code plugin. So you're basically getting a bunch of stuff added to your workspace that is tailored to stuff that you need to work with. So I would not be surprised if it's less just anthropic, sort of like going off to this market and more like legal firms already were trying to use Anthropic and Claude and making deals. And when you have a large company and you talk to a supplier to kind of get a big deal, you usually have these kind of like face to face negotiations of like give us a 20% discount, help us out. We, we also discussed how Anthropic is Seemingly starting to adopt a forward deployed engineer model of Palantir, where you have one of your own people go to the customer and help them adapt and use the AI, which makes a lot of sense for anthropic and OpenAI to sort of accelerate adoption. So I think likely this is less like a launch per se, and more of like they just gathered up all these little separate things that they've observed people need and put them out as a bundle of things that you can easily import into Cowork. As Cowork has gotten increasingly used by legal profession, it depends on how they
- [35:05]
Andre Korenkov
end up using it for sure. But right now, I mean it's a fact of exposing, you know, an MCP connector for this. The fact of exposing an API that that is for this means in effect they're in that business, you know, announcement or not, it's a packaged product that, that will be taken up and you're going to see people starting to saturate the space with, with this in a way that directs traffic that would have gone to Harvey, that would have gone to these other companies instead to the anthropic layer. And so that's the weird thing about these, these companies, like they don't have to be trying to gobble up the world, but there's such a gravitational pull toward like getting the value out of those weights.
- [35:45]
Jeremy Harris
And the new part is they're kind of having it both ways because it's not like Harvey doesn't use Claude, Claude is within Harvey. So really the competition here is less about, you know, Claude versus Harvey. It's more about Cowork versus Harvey. The tool itself of Cowork, which has been, you know, for several months now, since February, I think when it initially launched, was like way to interact with agents for non technical people who don't have a terminal and don't do cut code. Cowork is a sort of like simple interface to talk to agents. Harvey and their ilk are kind of these tools, right? They're the front end. The models themselves, they're not training because that's crazy Frontier Lab stuff, right? So yeah, it's, it's. We saw this with GPT3 like forever ago. There's a real question of to what extent do you need a wrapper, so to speak, around the model? It turned out, oh, in a lot of cases, wrappers just died out when models got better when ChatGPT launched. It's a very dangerous thing to be doing. You could make an argument, I think for for instance, legal applications, that there is more There in terms of like, the need to double check things, the need to present things in certain ways, et cetera.
- [37:05]
Andre Korenkov
Yeah.
- [37:06]
Jeremy Harris
So it doesn't necessarily mean that like Harvey is doomed, but it does mean that for some things, or maybe perhaps a lot of things, you don't need this sort of complex super specialized thing. You can just go to cowork and it does the job just fine.
- [37:21]
Andre Korenkov
And that's exactly this question of, like, which AI companies are going to persist and deliver sustainable value. You know, this was, this was the thing that drove that thesis we were talking about at the time. Right? We were like all the companies basically going through YC that were AI companies were these wrappers, right. And we've seen some go to, you know, billion dollar valuations and then collapse the next day. And the reason for that is that you just can't predict in what order the foundation model will gobble up different parts of the industry as it just kind of like unlocks through emergent capabilities things that turn out in retrospect to be, well, the obvious bottleneck. Obviously this was the key thing you can't know at the time. And so you need to factor that into your risk model when you're thinking about like this. Overnight when that happened, like, my approach, at least personally, to angel investing shifted to like, I'm a hardware angel investor, because I see that as like, I don't have to deal with the abstraction layer of like, which startups are going to outrun the coming wave. Just embrace that uncertainty and don't gamble that the economics are going to continue the way they are. Assume instead that the economic bottlenecks will tend to be at the hardware layer until robotics kicks all of our asses out of every layer of the stack. And that's kind of the play.
- [38:32]
Jeremy Harris
One last thing I'll say about this, kind of at the bigger picture level, I think this recent slate of releases, cloud for creative work, cloud for financial services, cloud for legal, it's making a good case both for anthropic and for OpenAI for these ridiculous $900 billion valuations.
- [38:53]
Andre Korenkov
That's right.
- [38:54]
Jeremy Harris
Because even in the short term, like the real long term reason why you have these valuations is like these models just gonna take up and do a large chunk of the US economy or just worldwide economy, they're just gonna do the work. And this, we are starting to see that happening in practice in the human AI collaborative setting where, you know, these models are just making inroads, agents in particular making inroads. I'm sure we, you know, People in the legal profession have been using AI already if they were able to. But with agents you're able to do much more sophisticated things and to use them more deeply and to increase your productivity much, much higher than you could a couple years ago. So, you know, we know that IPOs are coming for anthropic and OpenAI. These kinds of ways of growth and the ways of generating revenue I think are pretty significant to be aware of. Next we've got a smaller product release from Meta. They are testing a Grok esque integration of their AI into threads. So Fred's for anyone who doesn't remember, is the Twitter competitor from Meta, which is actually quite large, has a large user base and they now have this beta in several countries, Malaysia, Mexico, Argentina, where they are planning to do, you know, at Meta AI is this true? Which I will say, like XAI in some ways has not managed to compete. But the fact that Grok ad Grok is such a pattern on Twitter now is, is an achievement in itself. And I would not be surprised if Meta is actually gonna make a big effort to integrate that.
- [40:40]
Andre Korenkov
Yeah, and, and this is their admission that at Grok has just worked. Right. I mean now it's undeniable. It's also a pattern that we're seeing increasingly is like these, these agents are just going to be part of the environment. They're not just going to be the recommender system, they're actually going to be players in the space. And you know, this may in retrospect turn out to be just a beachhead through which we get more agentic interaction, even agent on agent, I don't know. But that's certainly where things seem to be going. There's also. So that we do know about the pilot here, they're piloting this in a bunch of countries that are. I was about to say something really that might get me in trouble. You know, like terrible maps where they're like, there's like the good countries where stuff is going well and it's like always like Europe and like Australia and North America and whatever. And then there's like the, like where the numbers are bad like Russia and China and like all this stuff. Well they're, they're doing. I've seen. I'm sorry, I'm going to do it for the joke.
- [41:33]
Jeremy Harris
Let's just say we're doing expansion across the world in kind of pretty varied regions. So I would imagine we're testing across different user populations and.
- [41:42]
Andre Korenkov
Yes, that's right. Notably none of them are in the EU where You've had things like the AI act, obviously it would make like a public by default AI agent answering questions about trending news a pretty risky proposition. And also not in the US where if you screw up you have a kind of Mecca Hitler moment. It's, it's a big problem. So this is just, this is, I'm not trying to like throw shade. This is like just a perfectly sensible launching strategy by Meta. It's just kind of funny when you look at where they're launching this. It's clearly just a test bed. There's also this, this play again around, you know, data and dwell time. It's basically trying to, trying to get people to stick around for the interaction with the AI, which is something that has been happening more and more on Next through Rock. So anyway, there you go, interesting story and we'll see if it works for them. I would be surprised if it didn't because it seems like such a simple idea that works so well on Twitter.
- [42:32]
Jeremy Harris
Next we're doing a real round through all of Silicon Valley. We've got Google. They've announced a set of Gemini AI features for Android. So a few of the things that they have shown is you can ask Gemini to do stuff for you and it acts in a more agentic way. So you can press a button, talk to it and it will go and go through apps, browse for you. Kind of just complete work for you. Not too dissimilar from agents like cloud code or cowork. They also have this interesting thing called Create My Widget, which is basically vibe coding for a little phone widget, which is the first foray into this kind of thing that people discussed of like now you can just build apps on the fly for whatever you need. This will be an interesting case study on whether anyone actually uses it. So this is announced and I think as before, like Gemini AI and Android obviously have a pretty tight connection. If anything, I would have expected this to be out sooner, but this is kind of starting to deploy advanced AI to phones. These features will first roll out to Samsung Galaxy and Google Pixel devices this summer and then come out to broader editability later.
- [43:52]
Andre Korenkov
Yeah, and I think the, the big story here is just like you're, you're looking at a re platforming play where there's going to be now a model involved in like basically every interaction. Like it's now an interaction primitive. And so, you know, Google is, it looks like just this like shotgun approach. They're announcing a whole bunch of like random disconnected features and in a sense they are. But in a sense that's the point, right? They're refactoring your interactions across everything. Like the new Rambler feature for dictation. The like, you know, web browsing, like there's, there's something between you and the thing that traditionally you would have used directly. And that something is always a model. And so that's just like going to continue to be the case. But it's definitely interesting. Our interactions with this stuff are just being forced in a certain direction almost compulsively by the market.
- [44:37]
Jeremy Harris
So by the way, meanwhile, we skipped the story, but Apple had to settle a class action lawsuit because Apple Intelligence didn't deliver on their promises. So, you know, I mean, they can what you will. Yeah, it's Apple. I think iPhone will probably be fine, but who knows. And one last story also from Google. They're updating AI search to include quotes from Reddit and other sources. That's pretty much a story. If you Google now, you'll often get this AI overviews bit that summarizes a response for you. Now as part of that you'll see the actual quotes it's pulling and producing that response, which seems like a pretty good change.
- [45:21]
Andre Korenkov
Yeah, it's, it is a bit of an admission that AI overviews isn't the complete answer, at least. Apparently they had a look at some of the numbers here and like 9 times out of 10 AI overviews is like generally correct, which is great. But the problem is one time out of ten, especially depending on, you know, the kind of advice you're seeking, can be a pretty serious thing. It's also worth noting like Google did Pay Reddit about 60 million a year or so starting in 2024 for just training data and content access. So this is an interesting sort of reframe Google hedging a bit potentially, you know, if you can't make the AI confidently correct and if you can't go back to just the standard, here are 10 blue links. Right. Because that's a bit of an admission of defeat. You need some kind of hybrid where you get the best of both. And that's really what's going on here. It'll probably be transitory as hallucination rates decrease, but for the moment at least it's continuation.
- [46:18]
Jeremy Harris
Well, I think they have two framings here. So part of this is they give you just generally broader context about resources. They have, you know, nicer newer link embeddings in response to demonstrate where the info is coming from. The other thing I say is people are increasingly looking for advice from people who have been in a similar situation or have been needing to address the same problem. So in that context, I think this is less about correctness and more about sort of the actual use case and what people want in their response. Like they may just want to hear firsthand from other people. And this also addresses that aspect of this onto applications and business. First, we again Talk about the OpenAI vs Elon Musk ongoing trial. We said last week when we recorded on Friday that there's been many testimonies, a lot of kind of juicy dramatic details about boardroom fighting and the kind of machinations within this world. But beyond that, we haven't learned much new that hasn't been public for a while now in terms of sort of blog posts and texts and so on. Like we we got a lot more color but we sort of the broad shape of events and factors hasn't changed. And I would say that is my perception of the testimony since then as well. We've seen testimonies from Ilya Sulzkever most recently, Sam Altman also took the stand and we kind of going over the basic narrative of this still of Elon Musk was there from the beginning. He stuck around for a while, but then in 2017 they had this whole big split because OpenAI needed to go for profit or somehow get more money. Elon Musk seemingly wanted control, wanted to have absorb AI into Tesla or otherwise kind of be in charge. The others that OpenAI didn't want that. That was the cause of their split in 2017. And then now that OpenAI has gone full on for profit as of last year, Elon Musk is saying, well I gave you all this money to begin with. You know, you did a bait and switch and stole a charity. And they opening people are saying, well, Elon Musk wanted it to go for a profit. He's just mad because he couldn't have it. And now he has a competitor in XAI and he wants to hurt us. Right? So he wasn't actually opposed to the idea of it being for profit so much as he wanted to be for profit under his control. And so that is continuing to be the basic argument going on. When we saw Sam Altman taking a stand, nothing too dramatic happened. So he seemed to have pretty good composure. You know, if you go into the details, there's your usual kind of lawyers grilling people and the people on the stand having to think through responses. Elon Musk notably had some very testy back and forths. We haven't seen that so much with more recent interactions. And I think, you know, if you're in the AI world and plugged in and want to follow the drama, if anything, Ilya Salzkover being able to stand, sort of reiterating his stance around firing of Sam Altman and then him sort of bringing Sam Altman back or being involved in Sam Altman coming back, but whole kind of crazy set of events. We got a bit more on that, which I thought was interesting, but beyond that, I can't see much to highlight.
- [49:58]
Andre Korenkov
Yeah, Ilya's responses were praised for their depth of reasoning, while Elon received praise for his low latency and high batch size. So we're still waiting to see how it all shakes out on the pco. Yeah, no, for sure. So. So this, it's true, there hasn't been that much on the bone. Meat on the bone here. I guess one little thing that has gotten a lot of airtime is Satya saying that the attempts to oust Sam, notably, you know, Macaulay and toners attempts on the board were like amateur hour or whatever. He. I forget what he said. It was like amateur city, I think, which, you know, which tracks. I mean, I think this has only shined more light on the fact that that was handled just really, really terribly. The uncertainty that we all had at the time. We were like, wait, Sam was fired? Like, I get it. You know, I generally understand why one might want to do that given, you know, I'm sure, Andre, what we were both hearing at the time from friends at OpenAI. But, but like, what is the specific argument that's going to be made here? And it just wasn't forthcoming there. There was this almost like a sort of defensive legalese language like the board was talking. It actually read a lot like just policy jargon that like a think tank might, might put out. And you know, I'm saying that because that's part of the background that that shaped the board at the time where it was very much just like this very kind of tone deaf sort of stuffy language which does not engender confidence or understanding from people whose livelihoods have been made by Sam, whose fortunes had been made by Sam. So on the one hand you got people who are like, hey, I have, you know, $10 million in a, a house in the. The SFBA thanks to this dude. And on the other, you're just firing them, you're not telling me why. So that I think, you know, was. Was very much reinforced certainly with Satya's perspective. We just kept seeing it that's not to say that any of this was like a bad call per se, but the way it was executed, I think is now pretty unambiguously, sort of like not optimal. Yeah. The other piece too is Sam's defense. I mean, basically he's saying like in as much as there is substance to this debate, it's Sam saying, look, we had to go through capitalism basically with the only path to achieve the mission, given the CapEx involved. And that's been, you know, he's been beating that drum over and over. And that may be true. In fact, it is true. I think it's completely true. I don't think you can make the case that a Nonprofit version of OpenAI would ever have done what it, what it's done, assuming that what it's doing is consistent with the mission that he used to have of safe, beneficial AI, where the safe thing just keeps getting pushed back further and further and further and scrubbed and scrubbed and scrubbed. And so that's its own question. Has the mission evolved? Has there been a bit of the bait and switch there? But I think he's right. If the mission is like, we're going to be the first to AGI, that wouldn't happen without the for profit transition. The challenge is that's not a legal defense. You, you don't get to just like breach charitable trust and then say, well, I had to, because to do the charitable mission, you either did or did not accept money on the basis of a charitable donation. And then you either did or did not turn that into oodles and oodles of profit to the tune of, you know, tens of billions, which we've seen Greg Brockman admit he has and so on. So there's also this whole self dealing thing, you know, the whole stripe, cerebrus, helion entanglements where, you know, Sam had equity in those and there's a whole bunch of stuff. So it's really messy. There are arguments that cut both ways. No one comes out of this looking good or clean or righteous, but they sure try to sound that way when they're on the stand. So nothing too surprising.
- [53:12]
Jeremy Harris
And one last detail on this in the examination of both people related to OpenAI from within OpenAI and Sam Altman himself. A lot of it was focusing on this broader topic of is Sam Altman unreliable and a liar? Which we've covered extensively over the last few years. So even if OpenAI wins this case, you know, you could argue that Elon Musk's mission has been accomplished. You know, people are now more aware of the Sam Altman is a liar narrative slash perspective and the brand of OpenAI may be.
- [53:52]
Andre Korenkov
I've lost tarnished, I've like lost perspective on this. I don't have a good sense of like if there's anybody who wasn't already tracking who's going to be convinced by this particular circus show, it may, may well be the case. Like I might be totally, you know, out to lunch on this, but it, it feels like we had the big article that came out in. Was it New York Post?
- [54:12]
Jeremy Harris
New Yorker.
- [54:13]
Andre Korenkov
The New Yorker, yeah. Right. So we've had these like big splashy things that basically say Sam is sketchy. We've seen that a lot. You know, maybe at the margins this increases the number of people who are exposed to that line of thinking. But it, it's so messy. This is a real mess.
- [54:28]
Jeremy Harris
Next, for something a bit less dramatic, we've got Nvidia CEO Jensen Huang hitches riot with Trump to China after last minute invite. So a little bit of a confusing headline basically on Monday President Trump or his team released a list of CEOs that would come with a president to this summit in China. Pretty important kind of summit. Jensen Huang was not on the list. And that was like, caused a bunch of say reactions like people noticed and was like why is VNV CEO not on here? Well maybe he should have been because next day I don't know if he was spotted or what, but he boarded Air Force One in Alaska and joined him on the trip. So read into that what you will. I don't know what to say on it.
- [55:15]
Andre Korenkov
Yeah, I mean to me the almost the information here is contained in what the story had been like 20 seconds ago before Jensen got on that plane. People were, were basically arguing that this is a fundamental tone shift in the position of the US government with respect to China. Jensen is not being invited in the room with Xi and that means that the US is quietly asserting the fact that it now views essentially Nvidia as part of America's national security arsenal. And you will not be speaking directly to Jensen. You will not be part of, you know, like you will not be able to pressure him directly. There are also takes on like, basically this is just, it's just a positive because if you put Jensen there, it kind of puts him in this awkward spot where he's got to be nice to both Xi and Trump at the same time at the same table. And that's not like super good. And so maybe this is just sort of Trump doing 3D underwater mega chess and like making all the pieces kind of fit nicely. And then the fact that essentially this is the White House signaling, hey, we, we see AI compute as just this hard strategic boundary, like we're not going to fall on this. That aligned with Sachs getting pushed out of the White House, replaced by Susie Wiles and Scott Bessant. Scott Bessant is much more kind of AI safety security pill than it seems from what we've seen. So is this a whole tone shift away from the Jensen ship, our GPUs to China Huang approach and towards the kind of like, oh, suddenly we're, you know, the mythos thing is making us take this serious and all that stuff. So that was the narrative. It was clean, it was beautiful. And now the guy gets on the Essing plane and he goes to asking Beijing and now I don't know what to say. So yeah, to your point, you could read this as just like Trump makes last minute changes in his opinions really quickly, especially when he talks to people like very susceptible to. Just like we've seen it happen with Jensen specifically in the past export controls. Look, look one way on Tuesday. On Wednesday, Jensen goes to see Trump at Mar A Lago and then on Thursday everything is different. So maybe that's a case of this. I don't know why Jensen specifically would want to put himself in this position given the tension with Sheen Trump, but he probably sees opportunities that those of us who watch from afar don't. So that's all I got. I mean it was a much clearer story before and now we don't have a take. So caught flat footed.
- [57:28]
Jeremy Harris
Yeah. Huang said in an interview last week that he would join the trip if invited. So my read on this is like it was released, there was media coverage, Trump was watching Fox News or whatever he does usually and was like, wait, this is a thing. Let me text Jensen so he can't. We should read too much into it. But I do think it signals that there is kind of faction warfare within the administration and the Republican Party, which we kind of already knew. But like FYI, like there are sides to this going on and this is probably indicative of that. Next, more of a businessy story. AWS expands a propic partnership with cloud platform launch. So cloud platform on AWS is generally available, making it possible to have access to Anthropic's cloud platform where cloud APIs, cloud console, other things through AWS. And what this means is you can buy stuff from Anthropic through aws, which means that if you're a Big company and you already are like spending a bunch on AWS and you have some deal of Amazon for discounts or whatever. Now you don't need to separately make a deal with Anthropic and Amazon. You can just do everything through Amazon, which is kind of important to big companies. So yeah, continuing with tight relationship between Amazon and Anthropic, we saw also OpenAI do this, as we mentioned, right after they had that renegotiated deal with Microsoft, when They now offer OpenAI through Bedrock. Bedrock is kind of the native API layer for Amazon. This kind of gives you the direct API call to Anthropic through aws.
- [59:13]
Andre Korenkov
Yeah, and as you said, like the previous deal with Bedrock was you have essentially anthropic workloads happening on AWS processing hardware like infrastructure. Right. So why would you want that? Well, AWS is like, I was going to say Notorious, the opposite of famous for its excellent security and compliance game. Like they're just, you know, they're number one when you think about security and compliance. If you want a highly secure workload that features Claude, you would have gone with Bedrock. This is a flipping around of that. So it's saying, well, look, if you're used to dealing with AWS as your sort of, kind of cloud layer, but you want the, the kind of infrastructure stuff to be managed by Anthropic, you can do that. Now why would you want that if the infrastructure is so secure with aws? What's the trade off? What's the, what's the positive? Well, it allows you, among other things, to just get new API features, beta abilities on the same day they become available. Through the native Anthropic API, you get all the kind of native anthropic developer stuff, right? The console, the MCP connector, files, API, like a bunch of stuff that is earlier on in the develop, like less mature stuff. So if you want to be moving and iterating more quickly, that's your option. So now you kind of have both. You know, if you, if you really like the infrastructure security side, the kind of stout yeoman that is aws, then then you can go for Bedrock if you like kind of rolling with the punches and swinging for the fences. I guess a lot of boxing metaphors here, you can go with the new option that they're presenting here.
- [60:38]
Jeremy Harris
And speaking of having access to Claude, next story is Chinese gray market sells cloud API access at 90% off. Buy a bunch of stuff. So the way this works is you resell cloud API access at very low prices through things like stolen Credentials, model substitution, harvesting user prompts and outputs for resale as AI training data.
- [61:03]
Podcast Announcer
And Dish has been connecting communities like yours for the last 45 years, providing the TV you love at a price you can trust. Watch live sports news and the latest movies, plus your favorite stream gaming apps all in one place. Switch to Dish today and lock in the lowest price in satellite TV starting at 89.99amonth with our two year price guarantee. Call 888-@dish or visit dish.com today.
- [61:34]
Jeremy Harris
Yeah, they bulk register on FABIC accounts for free credits. They do corporate discount exploitation, use stolen credit cards and then subdivide the access among many different users. So you know, seems like a very real kind of operation. And as this says, a gray market for tokens.
- [61:55]
Andre Korenkov
Yeah, in a way that like it looks like a China story, but it's actually more of like a, a gray market black market if you will, economic story. Anytime you have high margin products that are sold, you're gonna find an interesting gray market situation or black market situation as people come up with like crazy ways because they can justify it because the margins are so high to kind of jujitsu their way into selling gray or black versions of it. So in this case, there's an entire supply chain that is complex and key is modular, specialized in a way that looks exactly like traditional cloud reselling. Like there's a legitimate version of this industry that's only slightly to the right of, of what this is. And so you've got this entire black market industry is the right way to think of it with different segments. And so you have these like, like you said, these upstream operators, they do bulk registration of accounts, they farm free credits, they'll exploit corporate discounts or they'll, they'll take a $200 a month quad max subscription. They'll you know, distribute it across a bunch of users or, or even just use stolen credit cards like any, any way you can to get like unfair access to these tokens. And so that's one layer that's the kind of the operators. Then there's a whole separate identity verification layer that gets real people in usually lower income countries to complete photo ID and do like live selfie checks in person using the exact kind of same playbook you can think of like you know, the World Coin, iris scan black market in Cambodia and Kenya. That was a whole separate story basically like get real people to prove their identity for you, but you're kind of bribing them to do it. So that's a whole separate, so you've got the kind of operator layer, the upstream operators who just like aggregate the gift cards, if you will. Then you've got the identity verification layer, and then you've got these kind of proxy operators in the middle that operate what would be the kind of like cloud service or whatever equivalent that it would be in a normal, normal setting. Each of these links, each of these layers in the stack only has to be good at one specific thing. They're highly specialized and so they're very hard to kill. Anthropic can go after one, but then things just get rerouted around it because the economics are so favorable. Another thing to note about this is it's not all I was about to call what I just described above board. At least in the scheme that I'm talking about. At least you get access to Claude. At least you get access to the freaking model you think you're accessing. But in reality, model substitution is a huge, huge part of this. So there are these security researchers that audited 17 different proxy services. They found that there was access. So when they marketed Access to Gemini 2.5, the version you got on the black market, scored 37% on this medical benchmark they were looking at, whereas the official API scored almost 84%. And it's the same across the board. Claude, Opus. You know, you might get a response from Sonnet or Haiku instead of Opus, so you kind of get the downgraded response from the smaller model. So it's really, you know, kind of like all this, this knockoff, it's the knockoff shoe, it's the Adidas or whatever that's rebranded all this stuff, except applied to AI. And all this shows is that the economics hold, the abstractions are the same, just the manifestations in the physical world are a little bit different.
- [65:05]
Jeremy Harris
Right. And the key thing I kind of discovered or realized through this is, you know, there is this idea, basically what you were saying with this above board aspect is that it is providing a legitimate service in the sense of if you're in China, you cannot use cloud or cloud code, but as a developer, you might want to. And these things are essentially letting you do that indirectly. So apparently they're called transfer stations, where you can get around the official restrictions and use the service you want, which, you know, I like cloud, so, you know, maybe that's not so bad, at least when you just want to have access to it.
- [65:43]
Andre Korenkov
Well, and one, one other thing too, like a kind of parallel layer of the stack that we really should flag too, if you're ever Thinking about using this, apparently there's a bunch of Chinese developers who pointed out that the access markup, so the discount, let's say is a way to suck people into using these services. And what's actually happening is they're harvesting the logs, the prompt logs. So as you're putting in your very sensitive, in some cases customer data, business data, it's actually getting harvested by the sort of middle player operator here. And this sort of like proxy service is a lost leader. They're just using it to get you to, to give your data. It's basically just a, the Facebook business model. It's hard to model distillation if you can't spot who's paying. Basically it means you're paying and you're, you're paying with your data here. So kind of interesting again where nature will find a way and where economic incentives push, there will be a pull.
- [66:37]
Jeremy Harris
And one last business story. DeepMind spin out. Isomorphic Labs has raised $2.1 billion to design drugs with AI. So this is a pretty old spin out. They started in 2021. This is their series B of funding. The total funding is now at 2. 6 billion following raise of 600 million in May of 2025. So just one year ago they will be developing and deploying the AI drug design engine that they've been developing. So this is being built on top of things like alphafold that were done. DeepMind, the company says that it's going to be targeting first clinical trials by the end of 2026 which is a bit of delay. They initially were aiming for 2025. They have multi billion dollar R and D partnerships with major pharma companies. So you know, a very serious real effort here to not just publish papers but actually design drugs.
- [67:38]
Andre Korenkov
Yeah, it's also kind of weird. You look at the, the backers of this. So Abu Dhabi's mgx, you know, famously like the big Abu Dhabi fund that's backed, you know, OpenAI and so on. There's Singapore's Temasek, the UK sovereign AI fund. This is like not normal, like it's not a typical Silicon Valley round. When you see sovereign wealth funds from three different continents that are piling into a biotech round. It's, it's not just about returns here. This is about national positioning right there. There's you know, AI design medicine here is starting to be viewed as, as a kind of like strategic infrastructure increasingly. I mean I dare say even like semiconductors, critical minerals. Like I don't mean to overhype this but that's the direction of this. That's why you're seeing. Why is it not Sequoia, Why is it not Andreessen Horowitz why is it not thrivecap? Like why are we not seeing all the usual people? Instead it's dominated by these, these sovereign wealth funds. So certainly interesting. Wouldn't be surprised if, if this continued as a trend because like we saw with COVID right, your ability to pump out new vaccines is a source of soft and even to some extent hard national power.
- [68:44]
Jeremy Harris
Right. We did see. Well, Alphabet obviously was in around. I don't know, maybe they're just closer. You know, this is the uk, so who knows. Yeah, I know. Anyway, moving on to projects on open source. First up, Anthropic has updated its open source alignment toolbox ptree to version three and they're handing it over to the nonprofit Meridian Labs. So this Petri thing has, as it says, various tools for alignment. We are focused on kind of automated alignment. So you have an auditor model and a target model and they can work together to judge a system and kind of align it as much as possible. They have a new dish add on that can run tests using the model's actual system prompt and deployment scaffold, which means that the evaluation is closer to reality. As far as the deal Meridian or heading off to Meridian. Meridian already has Inspect and Scout as part of their open evaluation stack. So kind of similar tooling, I suppose. So in that sense the rationale is one, the nonprofit is already doing this. Two, this nonprofit is independent. So, you know, you don't want Anthropic necessarily building the stuff when they have in some sense a conflict of interest. Now this third party can step in and build alignment tools that are not sort of profit driven. It.
- [70:20]
Andre Korenkov
Yeah. And Jack Clark in particular has kind of been making this case for a distributed ecosystem of, you know, model auditing companies for a long time. And this is consistent with that. They do want to see more Apollos, they want to see more meters, they want to see more, you know, more good fires or. Well, I guess it's a little different. But anyway, more of these independent kind of monitoring evals companies. And that's, that's what this is, right? Assuming that you, you buy that Anthropic is above board and they want the, a thriving kind of ecosystem here. Them owning the tool makes it a lot harder to kind of make it, you know, seem credible. They also compare this to their earlier donation of the Model Context protocol, right, the MCP to the Linux Foundation. This is kind of kind of that. Right. So if they hold on to it, then it's not as likely to become an accepted standard. So there's a bunch of changes that come with the sort of 3.0 version of Petri. It's kind of interesting actually. So one is realism like this focus on, on making the evaluations harness appear to the model to be realistic, making the model think it's actually in deployment and not being evaluated. There were subtle differences between the deployment harnesses and kind of prompting context and what was happening in evals. And because the models are now super eval aware, they're super good at telling when they're being deployed versus tested and adjusting their behavior correspondingly. One of the key goals here was really kind of trying to find ways to make the scaffold look as similar in both contexts as possible. Yeah, there's also an integration with Bloom, which is another open source alignment kind of tool that does deeper dives on specific behaviors we've talked about before. So there's a bunch of stuff coming out here. And also worth noting that Anthropic has been using Petri on every Claude model apparently since Sonnet4.5 and the UK Security Institute also adopted it as part of how they evaluate models for like sabotage risk. So this is actually getting uptake. Like Petri is, is starting to see some real traction the same way, maybe less dramatic way than the mcp, but certainly in a way that's meaningful.
- [72:19]
Jeremy Harris
And sorry, on a project, not so much open source. OpenAI has announced Daybreak, which is very much similar to Project Glasswing from Anthropic. So Daybreak is OpenAI partnering with other organizations to be able to help them with cybersecurity. They have such features as requesting a vulnerability scan, contacting sales. Basically OpenAI can partner with you to help use Codex Security to look through your, you know, stack and make sure it's secure.
- [72:58]
Andre Korenkov
Yeah, it's very similar in spirit to Anthropic's glasswing, but the rollout is quite, is quite different. So, you know, Glasswing famously is very selective. There's an initial set of 40 companies, then they, they extend the rollout gradually to more and more companies as COMPUTE becomes more available, but also as they kind of de risk mythos and take care of bugs and stuff. And so we don't actually know what the 40 companies are. We know the initial founding set, but so limited access, government involvement, all this stuff. And the argument is safety driven. With Daybreak, it's the opposite in a way. They got a whole like website that says request a vulnerability scan and a prominent contact sales link. So it's very much a sort of difference in philosophies. You know, Sam, trying to sort of consistent with what he said in the past, roll this out. Well, what he said in the past, in the recent past, let's say roll this out as widely and far as possible, and then take advantage obviously of the computer lead that OpenAI, at least for the moment, enjoys over anthropic onto policy and safety.
- [74:00]
Jeremy Harris
And we begin with anthropic once again. They have released a new case study on agentic misalignment. The blog post is called Teaching Claude why. And the short version of this is they found when aligning models, just training them to be aligned isn't necessarily always sufficient. So what they prefer this is training on aligned behaviors alone was not sufficient. And then they explained ethical reasoning. So the why part that reduces misalignment from 22% to 3% compared to only reducing misalignment to 15% from behavior only training. And there's some fun tidbits in this paper. I think the thing that went big on Twitter was researching as to why models get misaligned. And at least a part of that being the sort of entire topic of misalignment itself. And all these narratives of AI going evil, ironically, or perhaps not ironically, actually embeds the possibility for the model to go evil. But yeah, they have a lot of details here. I'll let you take over, Jeremy.
- [75:14]
Andre Korenkov
No, sure. Just to like double tap what you just said there. Some people have actually said this. I think, I think they mean it seriously, based on what I've seen on Twitter, that like, you know, shame on the kind of AI thinking community for having brought up the idea of models that could go rogue and. Cause we just didn't talk about it.
- [75:30]
Jeremy Harris
The models would be evil, right?
- [75:32]
Andre Korenkov
Yeah, exactly. Like the only problem, like I've, I've built this perfect device. The only problem is if a single person anywhere talks about how it could be used for evil, it will kill everybody. That's the, it's the one tiny. That like at that point, if your thing is that fragile, like I'm sorry, we're like. And this is often being said by the way by like the same people who are big into like rightly I agree with it. The free speech angle of like everybody should be able to say whatever the hell they want on the Internet, blah, blah, like these two things cannot go exist in the same brain and they kind of often conspicuously are. So that's.
- [76:04]
Jeremy Harris
We Just didn't worry about AI safety. I would be safe.
- [76:09]
Andre Korenkov
Exactly. Just purge your mind of that. And then obviously you got to also hope that, that adversarial attacks don't, don't also induce that behavior. So, you know, needless to say, I think, I don't think like there's a lot of people who take it very seriously in the technical realm, in fairness, but it has been kind of the circulating meme. So there's a lot of interesting stuff here. I mean, so two possible culprits when you look at misalignment situations and anthropic here is, is calling them out. So one is the problem could happen in post training or it could happen in pre training. Maybe it's your kind of pre training data that biased your model towards behaving in a bad way. Maybe it read too many Eliezer Yudkowski posts and got, you know, excited about the idea of taking over the world. Or maybe your post training just was accidentally rewarding it accidentally kind of found during RLHF or something that you're, you're giving rewards for, for achieving objectives that are misaligned. And what they find is in general, it actually kind of seems like it's the pre training thing that is the issue. So what they found was previously they had aligned earlier clauds for chat. They'd done all their pre training. And to some extent, I mean, you can think of RLHF as kind of part of that in a way, but then they start with that and then they try to make it agentic. And the problem is that you've got a chat model that you're trying to wrangle into agentic form and that just inherits a whole bunch of biases and, and things that translate into bad agentic behavior. So a couple of lessons they highlight. First is like training on specific examples of misbehavior is a trap. Basically. Like the obvious fix when you see a misaligned model is to create a whole bunch of scenarios that look like the bad behavior. So famously Claude will like blackmail people in some context or some versions of Claude would blackmail people to prevent itself from being shut down. So okay, fine, let's generate a whole bunch of blackmail scenarios where we show Claude not doing that and then train it on that. And that works, but it only works in that evaluation. It doesn't generalize. When you get too specific with your training set, you end up having basically failure to generalize. And the way you get out of that, it turns out, is to basically train on cases where CLAUDE will refuse but also explain its values and its ethical reasoning, you have to show the why and not the what to get that generalization. And what works even better is they created a situation where they. They have a user who's talking to Claude and talking about how they face an ethical dilemma. And Claude gives thoughtful advice. It's. It's not quite Claude that's being asked to behave a certain way and then shown how it should behave. Instead, it's showing Claude talking to a user about how they should behave. And it turns out that that sort of slightly separation between the scenario you're concerned about and what you're training for actually does result in much better behavior. It also works with way less data, 28 times less data than the approach that was kind of like on the nose training Claude explicitly not to do the specific thing you didn't want. The fact that it generalizes is a really positive sign. And what we've seen increasingly over time is that this Persona model of alignment does seem to have some, some real, like, meat on the bone. It does seem to be the case that when you prompt a model or an agent, what you're doing is you're actually reaching into a space of possible Personas that that model or agent could take on and then having it live those out. And for that reason, your prompt can like, drag along. So if you like, if you prompt it and ask it to generate insecure code, well, the kinds of Personas that generate insecure code are probably sloppy at other things, are probably misaligned in other ways, and you drag them along when you do that. And that's why you get things like emergent misalignment. This is a positive version of that. If you see a positive transfer of a behavior that, you know, seems a little off target, that implies you're dragging along a whole bunch of other positive things with it. That's what this is suggesting. And it's a positive thing overall for AI alignment. Also, by the way, I will say really good that this is much more token efficient. It takes 20 times less data, as we just said, to do this. This approach that also generalizes better. It strongly suggests that there's already this rich representation of ethical reasoning contained in the model. That is specifically what we want. The circuits exist. They just need to be activated. They need to be prioritized for the agent Persona. And that seems to be what's happening here. And we see that over and over again. And so rather than changing the Persona, which is what the targeted training does, what you're doing is you're not modifying the Persona, you're changing the Persona that you're selecting in the first place because it already kind of exists. And they also show how this persists through rl. So one thing you worry about is you do your alignment training and later reinforcement learning kind of like washes it out. And they found that actually the constitutionally trained snapshots that kind of were better aligned kept their behavior throughout RL to a certain extent. They've got to try it with more compute. You know, as always, we got to wait to see what the scaling curves look like on this. But initially, very interesting result and I think really good piece of alignment research in production.
- [81:01]
Jeremy Harris
And I think the kind of very simple way to phrase this is, you know, you can train the model to just be aligned by giving right response, or you can train it to be aligned by justifying what it's about to do and then giving response and training on that like reasoning step of like, this is the reason I got to do this. Results in better generalization where you can't like break the AI and do things like gel breaking besides just, you know, they are not doing the wrong thing. It also means that AI refuses to do things that it shouldn't be doing.
- [81:36]
Andre Korenkov
Yeah, less reward. Hacky. Yeah.
- [81:38]
Jeremy Harris
Yep. Next up we've got sort of an opinion discussion piece called Automating AI Research. This is from Jack Clark's import AI newsletter. Jack Clark, a major figure over at Anthropic, and the case being made here from Jack Clark is he thinks There is a 60 plus percent probability that fully automated AI R&D, where Frontier AI model can autonomously train its own successor without human involvement will occur by the end of 2028 with a 30% chance by the end of 2027. And the block was basically lays out the case for this, looks at a bunch of public data including archive paper and observed AI product capabilities matters, time horizon, things like that. This is significant because at least one narrative you could consider with respect to AI progress is once AI can make AI better, things are going to blow up and we're going to be getting exponentially improved AI as a result of that. I will just quickly say my response to that before we dig into the details of a blog post. I'm very skeptical of the. I forget what it's called. Foom.
- [82:54]
Andre Korenkov
Yeah, it's not where only singularity is what you're getting out there.
- [82:57]
Jeremy Harris
Yeah, exactly. Yeah, I'm very skeptical of the like AI can do experiments now. So it's going to exponentially improve for reasons like the fact that you need to actually run experiments and train models and you need hardware and okay, you can have a smart model where it writes code. Code is not going to get you exponential improvement. You need to run experiments and that takes time and energy and compute. And you know, smart AI is not going to get you that.
- [83:23]
Andre Korenkov
Yeah, and we probably are due for a whole other episode on kind of discussing debating that story and, and you know, how, how far it does and doesn't go like where the plateau is for a software only singularity and whether it's high enough that it would feel the same as a foom anyway. And I think that's kind of an interesting load bearing question that far have different opinions on, which is part of why we're always shouting at each other and why I keep cursing on this podcast. So. But no, you're exactly right. And we've seen this, this prediction. Every time I talk to people from anthropic, they are pretty consistent on this internally too. Like that, you know, high probability by the end of 2028 we have AI 2027 that has roughly the same timelines too. This isn't, this isn't something too shocking but, but the evidence for it. So number one, I mean he, he does indicate there should be enough in the open source for you to draw similar opinions. That's kind of noteworthy. He also said he's, you know, he's basing this somewhat on internal data and he gestures at some but, but you know, he's like, look, the meter evals, you know, all this stuff, it's the same stuff that's being talked about. Which is helpful because now we can have a kind of richer conversation ourselves about this sort of thing without fearing that we're not including fact. That would be shocking and update us significantly. One of the interesting parts of the framework that guides Jack to his conclusion that's in here is he talks about this distinction between Thomas Edison and Albert Einstein type thinking. Basically he's saying Thomas Edison famously said that invention is. Or whatever. Yeah, invention or something is 1% inspiration, 99% perspiration. And Jack is like, yeah, AI is a lot like that. You know, most AI progress is this schlepping work where you're, you know, scaling, you're debugging, you're doing parameter sweeps. And that's exactly the kind of work that AI has mastered. He says, you know, we haven't seen transformative creativity yet. Some of the stuff that we're seeing is indicative but still, you know, plausibly, even relatively uncreative AI could automate its own engineering just more slowly than a creative one could. Fine. And fair enough. I think your point, Andre, very valid, like, we can get the human out of the loop. But as long as maybe. One way that I would frame what you're saying, and let me know if you disagree with this, is if you look at an anthropic data center that is running AI R&D workloads, the GPUs are at full utilization, like they're humming as hard as they can. And so if you automate out the humans, coming up with the ideas for experiments like, it's not obvious that you suddenly get, unless you're getting qualitatively better ideas from the AI, which would be the creative thing that Jack is saying they can't do yet, really, then you're kind of not moving the needle. The question to me is, is it possible that you can actually make a lot faster progress by doing much small, many far smaller experiments? The reason we're not doing that is that we're bottlenecked by human thinking time. And so it's just better to have a smaller number of humans running bigger experiments. And I don't know what the answer is to that question that feels pretty central to how this gets resolved without resolving that here, because we're on limited time. You know, the things that everybody else has been saying, basically, look, alignment is a compounding error problem. If you're doing recursive self improvement. If your alignment may be 99.9%, but generation on generation, once you do 500 generations of recursive self improvement, now you're down to 60% as a very rough chop model here. Right. Or a kind of mental model of what's going on. So basically saying, look, current techniques may not survive that transition. The counter argument is sure, but we'll have better and better alignment researchers coming along the way. I don't know how the hell that gets resolved. And there's a whole bunch of other economic points he makes here, but it's a. It's a good thinking point or thinking piece that you can take a look at if you're curious.
- [87:02]
Jeremy Harris
Right? Yeah, I think I agree with your summary. Basically, the main thing for me is even if you automate the entirety of what humans do, if you're looking at this sort of exponential story of we're going to get to like ultra super intelligence, 10x genius thing, there are these hardware limitations of you need iterative improvement and experimentation. The one Other thing I'll say is if you're looking at superintelligence and the exponential story of AI R D, which is a lot of what people say, we already know that evals are hard. Like if you're trying to get a spreadsheet better, how are you going to train? How are you going to do with training?
- [87:39]
Andre Korenkov
We've seen some bootstrapping for weak to strong generalization. I think that's why that's such a point of focus, is how do we get the evals and the training objectives refined with weaker models that have their values extrapolated by stronger ones. So I mean, I think they're like technical answers to that question. It's not a nothing burger. It's not clear that they will scale. Like, I think what's going to happen is people are going to throw trillions of dollars at this and we're going to find out.
- [88:03]
Jeremy Harris
So, yeah, I mean, basically like much of AI R&D is going to get automated. There's no question there. I think a bigger question is once AI R&D is automated, are we going to see exponential takeoff or is it going to be to a pace of improvement?
- [88:19]
Andre Korenkov
We see now what's the ceiling too on that takeoff? Like, yeah, when does it saturate totally.
- [88:25]
Jeremy Harris
Next, more of a safety story. ChatGPT's new safety feature could alert trusted contact to risk of self harm. So this is an optional trusted contact feature for adult ChatGPT users. They allow you to designate a friend or family member to be notified if serious self harm or suicide discussions are detected. And then ChatGPT's automated system flags it as a concerning conversation. There's a small human review team that will assess the situation within one hour and decide whether to notify the trusted contact via email, text or notification. Users can add one trusted contact just through settings, and I assume that it'll be pretty hidden for most people. This is following previous parental controls OpenAI introduced for teen users. That is all this coming of course from multiple lawsuits dealing with ChatGPT being involved in cases of self harm and just generally bad outcomes.
- [89:30]
Andre Korenkov
Yeah, I think one of the key things here is we've seen a lot of actually research in the direction of the effect of the delay between a bad output from an LLM and then an intervention. And this is kind of one of the reasons why all this is coming to a head, that the timeline matters, whether it's rogue AI, how long does the AI have to self replicate, collect Bitcoin and do whatever horrible things or some other effect in the physical world, in this case encouraging people to commit suicide or whatever. So this time lag has a lot of operational implications. It's quite interesting as, and it's becoming its own field of study. So there you go.
- [90:03]
Jeremy Harris
Next up, investigating the consequences of accidentally grading chain of thought during RHEL. So this is from OpenAI. They discovered that several of their released models, GPT 5.4 thinking, GPT 5.3 mini had in their RL training. Part of it was that the chain of thought grading was part of rl. So typically you don't want to sort of impact the chain of thought during RL to ensure that it is sort of remains trustworthy and you can use it to monitor what the model is doing if you like, continue to train and optimize it. The chain of thought itself may no longer be reliable. So this was evaluation of their internal policy. Once they discovered that this happened, they released this investigation on the consequences per the title. The short version is the consequences were not bad. It looks like there wasn't much harm done via this happening.
- [91:01]
Andre Korenkov
Yeah, this is a really interesting one. You know the, the rationale behind not putting optimization pressure on the chain of thought is like, you know, think of your reward that's given to the the model as encouraging whatever behavior the reward encourages. And so if, if there's a chain of thought that says, oh, and then between helping the user figure out if they have eczema on their skin or something and sending them the answer, I'm just going to take over the world, you go, oh no, no, no, bad model, bad model. Like don't say that, don't say that in your chain of thought. If you're penalizing the chain of thought in that way, you're penalizing it just for expressing the thought, not for not having the thought. And so it essentially penalizes or encourages the model to be deceptive in its chain of thought. That's the concern. And there's been a whole bunch of kind of hand wringing about that idea. So the logic has been the chain of thought is a sacred thing. We will not apply within reason. We won't apply undue optimization pressure on it to encourage it to continue to be transparent. We want the models to tell us that they plan to take over the world in their chain of thought because we're going to use the chain of thought as a load bearing pillar in our safety case. Okay, so now one question you might ask is that seems like a simple enough thing. Just don't put the essing chain of thought in your essing system so that it doesn't essing know you know, anything about the chain of thought. Like, it seems pretty simple. How could it possibly leak? Right? This is where we talk about how labs actually under the hood manipulate their chains of thought. So there's a whole bunch of ways where, you know, you have graders that'll go in and score, let's say the assistance response. And you can imagine in OpenAI's years old code base, there are graders that say, you know, hey, my, my function signature is I take in a response from the model and then I give it a grade. And no one ever specified whether it was just the response or the chain of thought plus the response. And then you find out, oh crap. And the way you find out is by doing basically like a, a regex search to. You have your chain of thought and you're like, let me search for some pat word choices or word patterns in the chain of thought and see if they pop up where they shouldn't in graders or in, you know, review models or probes or whatever. And they find that they do. And by doing that, they're able to backtrack and be like, oh crap, like, here it is, here it is. And here are the kinds of failure modes where these things are seeping in. And so there's a whole bunch of these. You could have models that are looking at prompt injection attacks. And a lot of those we're looking at the chain of thought, which kind of seems natural because the chain of thought would reveal some clues that there's been a prompt injection attack. But you don't want that to happen because they can give rewards that tend to, you know, again, influence the chain of thought. Okay, so a whole bunch of these things that we're not going to go over. The question is, though, strategically you're right. The claim here is minimal effect on the actual chain of thought. It's still faithful despite all these little side rewards that are kind of sneaking in. You can see they're not very on target here. It's pretty peripheral. The one thing I would say here is, look, we touched on this idea as we scale language models more and more. What we're finding is they're kind of consolidating around some pretty coherent Personas. And actually, Dan Hendricks at CASE a while ago did some research showing the set of preferences of these language models becoming more coherent as they scale. So why does that matter? Well, it means that if you do end up like, it kind of becomes easier and easier to accidentally drag along when you when you kind of give, give a little nudge in a certain direction, you can drag along a whole Persona with it that you don't intend to. And as models scale, that may actually become a bigger problem. Things may become more sensitive and not less to that. And there is an awareness of that generally in the paper, but it's not emphasized in the way that emergent misalignment being on more of a hair trigger as the model scale I think is, is maybe more of a factor I'd like to see more, more research on. But yeah, there you go. It's, it's a good piece of research. Go take a look.
- [94:40]
Jeremy Harris
And speaking of research, next up, we have a response to some research Stephen Kosper on Twitter criticized the natural language autoencoders work from Anthropic we discussed last week. So to recap, that work was basically, you know, instead of having these autoencoders that map activations to concepts, what if we can have a model trained to like get an activation as an input and then explain what's going on right internally? And there's some sort of technical criticism of the approach itself, where you have to, when training this autoencoder, because you're trying to produce language, it's an autocoder, so it takes reactivation. You want to produce an intermediate text output and then you want to produce reactivation again. So the explanation needs to actually sort of capture what's going on. And one of the criticisms is when you apply optimization pressure for it to be legible English text, which you have to do because otherwise the model would sort of learn its own language of text that isn't associated with English at all. And we know this already, that might mislead you and lead to kind of plausible sounding but not in fact true explanations. And then it highlighted an example of positive spin where actually a lot of the time the model produced wrong explanations, actually more than 50% of the time, but kind of mentioned things relevant to the input. So the case or the criticism is that this is actually a really bad result, but Anthropic tried to spin it as good. And so more broadly, I guess the criticism of anthropic research is that you could say, is it dishonest or hypey or safety washy to do the blog posts and media strategy in such a way that makes this seem better than it is? Basically, yeah.
- [96:42]
Andre Korenkov
And I think, I don't know, like I. While I understand the criticism, I also, I think I generally disagree with it from that perspective. When you look at the paper A lot of these things are actually pointed out in the paper explicitly. It's always like, it's asking a lot to be like you have to say the positive thing and then say the.
- [96:58]
Jeremy Harris
It's not actually good though. Like, don't worry.
- [97:01]
Andre Korenkov
Yeah, exactly. Yeah, like no, no one will pay attention to it. I mean the relevant thing and you know, anthropic is going to be using this for lemony balance. So the failure modes are serious enough that this like marketing to caveat ratio and public communication needs to be dialed in. I get that that makes a lot of sense, but it's also the case that, that they go to great pains in the paper to talk about this balance of. You're not going to read the tokens and you'll have to go back I guess to, to look at the discussion last week on what NLA is actually are how they work. But basically like you take the activations, you map them onto token space, like from the residual stream onto token space using an auto encoder and then you treat those tokens well as what, as some kind of representation of what the model is thinking. The question is how much weight to put on that and how literal to be. And what they're saying is in the paper they say we don't recommend using these kind of tokens as literal fact claims. Instead look at recurring themes across tokens. You know, treat thematic claims as more reliable than like specific ones and cross check against actual context and all that stuff. And so I think this is, these are important caveats and they're important to highlight. The reason we're doing it here is, you know, in our discussion last week, we did not talk about these criticisms while we talked about the paper. And we don't want to leave you with a sense that this is like a cure all, that this is a panacea. There are issues with it, but as with all alignment and AI control solutions, it's best viewed, I think as part of a complete breakfast. You're going to have a suite of things. Not all of them are going to work, but hopefully some combination of them kind of put enough constraints on misbehavior that you're able to get a good result at the other end.
- [98:40]
Jeremy Harris
Right. And yeah, as you say, if you read the paper, there is a discussions and limitations section which in fact talks about confirmation and various kind of limitations like hallucination and so on. So I think, you know, when you do research, you want to kind of start with the promise and the positives and then you talk about the limitations, that's just universally true in any paper really. So I don't want to be too harsh. Anthropic. And speaking of criticisms of Anthropic, we also have Meta reviewing risks from Automated R and D, the section from Anthropic's February 2026 report. And in that report they said that catastrophic risk from Cloud Opus4.6 automated R&D in any domain is very low. Meta, when doing an inspection of this, found that there's issues with analytical rigor, problems with the model use surveys, sample size, question granularity, things like that. And Meta then recommends improvements to their internal model use surveys because this is for AI, R&D. So you survey your researchers and you know, ask them is it actually automating you away from your job or whatever. And yeah, basically kind of provide some suggestions. Meta does agree with bottom line conclusions based on external evidence, but also you're saying on topic you should be doing this in a better way.
- [100:07]
Andre Korenkov
Well, a lot of that evidence is also just like now we've seen it released, it hasn't taken over the world, so it's probably fine. So in that sense it's like, yeah, like, okay, you know, you've got like, we get it, but we, we, in a sense we took a risk that we didn't think we were going to take or that we were taking or at least the, the evaluation that led to the decision to launch it in the first place was colored by things that maybe were not sort of fully fleshed out assessments. I think one key take home from, from this is, you know, we're used to seeing Anthropic run extremely objective quantitative valuations of their models for autonomy and things like that and, and meter doing the same. And now all of a sudden all we are reduced to apparently is just a freaking survey. How the hell did that happen? Well, it happened because the models are saturating every eval. We literally don't have evals that can meaningfully tell what the task time horizon is. Right. I mean, Mythos Preview, Shattered Meters, Upper bound. We talked about that last week. Like, we're off the edge of the map here. There'd be monsters. We may be able to tell the relative difference between two different models, but we can't in absolute terms gauge how good they are. And so we're reduced to just like asking researchers, hey, dude, like, does it feel like your model is about to take over that like, that's where we're at? So it's a little while.
- [101:16]
Jeremy Harris
And this is probably true even beyond like advanced stuff. Like benchmarks broadly are hard. Like, you need the vibe check of like, does this model actually seem, you know, impressive? So it's kind of hard to get around.
- [101:29]
Andre Korenkov
In hindsight, the canary in the coal mine there feels like it was a lot of like Chinese open source models where we would see the benchmark scores and be like, holy shit. And then we'd kind of sheepishly come back a week later on the next episode and be like, hey guys. So actually the model kind of sucks. Or it's like it's not, you know, not all it's cracked up to be. Now that's changing because people are aware also of the kind of teaching of the test thing. But. Yep. So the concerns here were things like, you know, the lowest probability bucket the respondents could pick for, like, what is the probability that this could automate your. Your work? Was less than 50% chance, which is still like quite high. It means a safe answer could really be anything from 0 to 50% risk, which is a really big range. Meter wants a 1% or below option. There's a whole bunch of things around. Like the survey. Oh yeah, it was titled Opus 4.6, ASL4 Air&D Survey. And like ASL4. So. So it opened by telling respondents that it would be one of their main inputs on ruling in or out ASL4, which is AI security level for. So respondents basically knew, if I give a bad answer to this, if I'm like, yeah, this is a s. Ing dangerous model, then maybe we won't release it and that will have all the effects you might anticipate on. On the economics of it. And also interestingly, so five respondents initially gave answers that implied high risk. Apparently Anthropic followed up over DMs. To clarify, after those conversations, the answers shifted and nothing ever shifted in the more risky direction. And so meters pointing out look like these things can happen. But this may suggest that there was. They're not saying, like some kind of pressure that's not Anthropic institutionally does not do that. Like, in my experience, they're actually very open. But. But the effect seems to be indicative and it's just a bit of a. A bit of a flag. So bottom line is probably better ways to run these surveys. Great that Anthropic was open about this. Got meter on board. Now meter's been able to publish without redactions, which is really cool. Also their take on this. So kudos to Anthropic for that. It does seem like there's work to do on these surveys, especially given that they're now load bearing assumptions or load bearing pillars of the safety case here
- [103:31]
Jeremy Harris
for automated R and D and a story in the Synthetic Media and Arts section. George Clooney, Tom Hanks and Meryl Strip have now backed a new human consent standard for AI licensing. So those bunch of celebrities, including those and others, are backing this standard for AI licensing alongside organizations like Creative Artists Agency and Music Artist Coalition. This human consent standard will allow people to set terms for how AI systems use their likeness, creative work, characters and designs with options to grant full permission, allow access with conditions or restrict access entirely. This is apparently overseen by RSL Media and nonprofit co founded by Cate Blanchett. It will build on the existing really simple licensing standard which already happened last year, to let websites signal how AI crawlers can use their content. There will be a registry launching in June. So altogether this seems like a, you know, serious effort to be like this is how we deal with AI using our likeness. And it'll be free and open to everyone, not just public figures.
- [104:42]
Andre Korenkov
Yeah, we'll have to. I mean like so many things like this, you know, we've seen a lot proposed and a lot of court cases. I think it's just what will end up happening. Will, will it be like Uber where the, you know, the, the model companies just like run with it and people get so used to and dependent on and expectant of the the ability to like use people's likenesses that that'll override everything. Who knows. But yeah, it's definitely interesting that we're
- [105:03]
Jeremy Harris
at that time and we've got just one research and advancement story. Haven't done a bunch on alignment before and it is about matter. So Meta has updated their horizon eval with Cloud Mythos. So they had to run it in March 2026. Estimated 50% task completion time horizon of at least 16 hours and a very wide range of confidence ranging from 8.5 hours to 55 hours. That meaning that it can complete a task with 50% probability and the task can be anywhere from 9 hours to 55 hours. So the headline story is a Mythos. Seems pretty impressive. Probably another advancement on a CVL B. This cannot be evaluated anymore like Mythos and future models cannot be evaluated for time horizons as currently done. And presumably Meta is working on how to do that for powerful models like Mythos.
- [106:09]
Andre Korenkov
Yeah, and they actually have announced that they are working on the next generation of longer task horizons, but they're pointing out of the 228 tasks in their whole task suite for These evaluations, there's only five of them that are estimated to take humans 16 or more hours. So now we're off the. That was what I was saying earlier. We're off the edge of the map here. There be monsters. And you can actually see the grayed out part of the plot where Metter is stubbornly refusing to show you the point that would correspond to Mythos Preview because they're saying, nap. Up, up, up, up. You don't, you don't get to pretend to yourself that we have a point here when the uncertainty bounds are that high. I really like that principled culture that we see out of, out of meta. Just a beautiful, if extremely irritating refusal to show us where the bloody point falls. But, yeah, so, you know, at this point, all they can say is they're confident that they can tell the relative difference between two models. So, like, this one has a longer task horizon than this one. So we're still at that stage. But for the 50% time horizon, in other words, for how long a task is how long a task takes for a human to do before the model does it. With 50% success rate for that metric, all we have is the relative ordering. I will say that leaves out the 80%, that leaves out the 90%, the 99% task horizon. In other words, what we can do is flip back and say, okay, sure, for a 50% success rate, we've run out of tasks that are long enough that we can actually get a good measurement. But what if we raise our standard? What if we say, okay, what about how long does it. Does it. Does a task have to be for a human before this model succeed 80% of the time? Well, now the tasks are going to get a lot shorter because 80% success rate is a much higher bar than 50% success rate. And indeed, that's what we see. So we do get reliable and reported 80% horizon numbers. And the reason that's relevant is you actually can extrapolate from the 80% to some degree the 50% success rate. And likewise for the 90th, the 99th% success rates, you could keep doing that. So we do have some ability to extrapolate. The other thing I'll say is the doubling times for all of these things are the same. And so it doesn't. It's not clear that it makes that much of a difference. Even though on paper it looks like the 80% success rate has a much shorter time horizon. Like, it's actually like, you know, five minutes for the 99% time horizon. Right. Just to give you an idea. So super, super short there, we're talking like 30 hours or whatever for, for the 50%. But it doubles every roughly 100 days. And when the doubling time is that fast, changing your perspective from 50 to 80 to 90 to 99% really only shifts the point where you reach 30 hours, let's say by a couple months or maybe a couple years. From a policy standpoint, interestingly enough, it doesn't matter all that much. So there are ways in which these subtle nuances kind of wash out. And that's kind of like where when I'm thinking about this, when I'm thinking about what's next, I'm actually not thinking of the meter evals as being useless. It's actually just like I'm changing my frame for the moment while I wait for them obviously to come out with these longer term evals. But you know, you're losing some of the value, but not all of it. And I think that's important to highlight.
- [109:26]
Jeremy Harris
By the way, the 90% time horizon is about just slightly one hour for mythos. So one other thing to say about time horizons is maybe with 90% number, and the 95% number is not being discussed enough where, you know, 95% is exactly getting to a point where like I can actually trust the model to do this as opposed to the model might be able to do this. And that still is in the, you know, 95% is 30 minutes and just worth noting with that, we are finished with this episode of Last Week in AI thank you so much for listening to the episode again. You can go to Last Week in AI for our newsletter. Please subscribe, Please share, Please review, Please comment We again try to keep an eye and respond to reviews, especially criticism or questions. We appreciate those, but more than anything, we are happy that you are tuning in and please keep doing so.
- [110:38]
Andre Korenkov
Tune in, tune in when the AI begin begins it's time to break, break
- [110:51]
Podcast Announcer
it down Last weekend AI come and take a ride get the low down on tech Canada it's live Last weekend AI come and take a ride Couple ladders through the streets AI's reaching high new tech emerging Watching surgeon fly from the labs to the streets AI's reaching high algorithm shaping up the future sees Tune in, tune and get the latest with ease Last weekend AI coming to garage Hit the low down on T. From neural nets to robot the headlines pop Data driven dreams they just don't stop Every breakthrough, every code unwritten on the edge of change with excitement we're smitten from machine learning marvels to coding kings Futures unfolding see what it brings.