
Podcast
Latent Space: The AI Engineer Podcast
Hosted by Latent.Space · EN
The podcast by and for AI Engineers! In 2025, over 10 million readers and listeners came to Latent Space to hear about news, papers and interviews in Software 3.0.
We cover Foundation Models changing every domain in Code Generation, Multimodality, AI Agents, GPU Infra and more, directly from the founders, builders, and thinkers involved in pushing the cutting edge. Striving to give you both the definitive take on the Current Thing down to the first introduction to the tech you'll be using in the next 3 months! We break news and exclusive interviews from OpenAI, Anthropic, Gemini, Meta (Soumith Chintala), Sierra (Bret Taylor), tiny (George Hotz), Databricks/MosaicML (Jon Frankle), Modular (Chris Lattner), Answer.ai (Jeremy Howard), et al.
Full show notes always on https://latent.space
www.latent.space
www.latent.space
119episodes
Episodes
Newest firstAll episodes
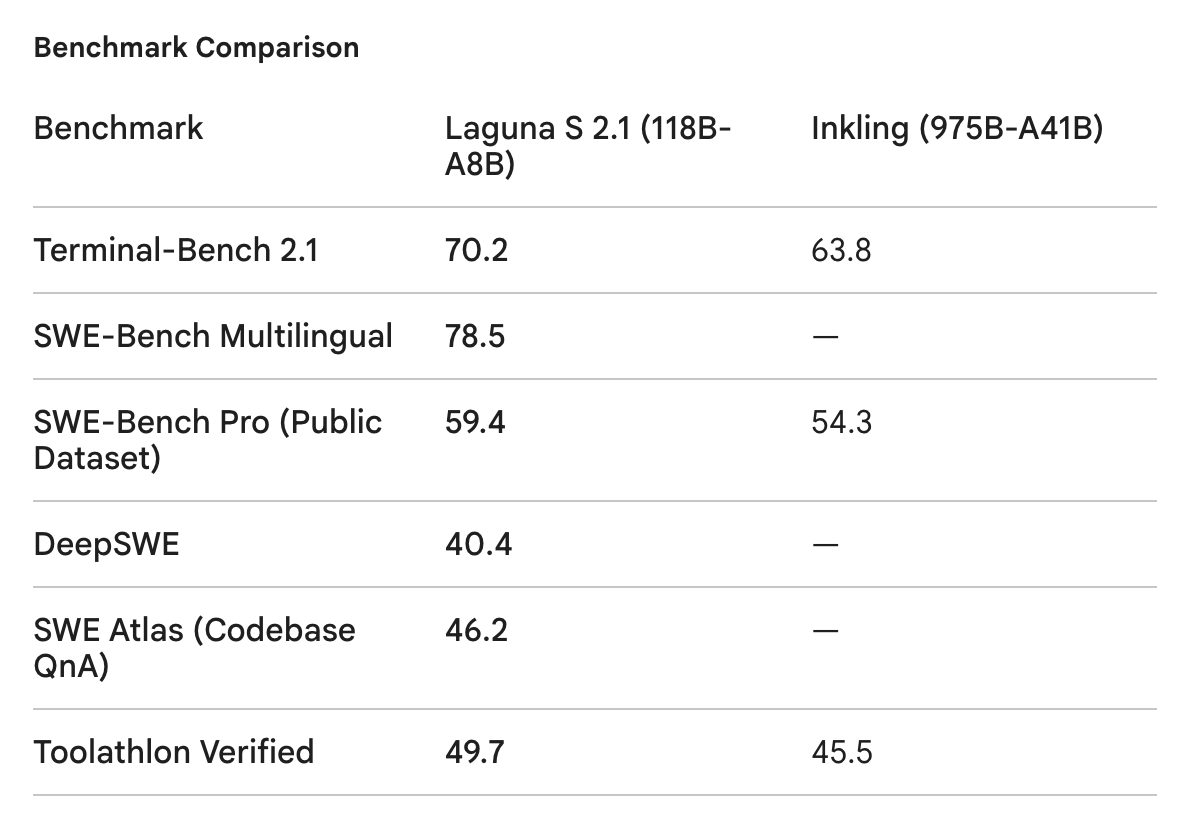
Inside the Model Factory — Eiso Kant, Poolside AI
2d ago01:54:33Summary readyIn recent months, the open vs closed, and US vs China discussions on model ownership and sovereign/local AI have heated up to a fever pitch. So it is very very good news that Poolside AI are finally emerging with new models, like Laguna S 2.1, that are beating Thinking Machines’ recent release nearly 10 times their size.Poolside’s recent tech report got a lot of praise due to their level of detail, and Vibhu first covered Laguna’s recent technical report on our paper club:From spending $12 million building language models for code before the world cared to creating a Model Factory that can take a model from pre-training to release in eight weeks, Eiso Kant has spent more than a decade betting that code is the path to AGI. In this episode, the Poolside co-founder joins swyx and Vibhu to explain why ChatGPT felt like vindication, why Poolside embraced open weights and open research, and why he would rather live in a world with 100 foundation model companies than five even if Poolside were one of the five.We go deep on Poolside’s Model Factory: the engineering systems behind 10,000–20,000 experiments per month, streaming data directly into training, reproducible experimentation, low-precision compute, and agents that increasingly write code, launch jobs, evaluate results, and modify the pipelines used to train future models. Eiso also unpacks their recent launch Laguna S, why persistence, verification, and backtracking may matter more than raw intelligence, how much capability remains inside smaller models, why reinforcement learning will move earlier into pre-training, and why next-token prediction is still extracting too little from the web.We also discuss model-harness co-design, Poolside’s path from coding agents to AGI, why Eiso thinks MCP and traditional tool calls are “stupid,” the real economics behind frontier-model training, Poolside’s $500 million raise, open-source AI, regulation, NVIDIA and TSMC’s influence, engineering productivity in the agent era, high-agency teams, and hiring at Poolside.We discuss:* How Andrej Karpathy’s RNN work inspired Eiso to start building language models for code in 2015* Why Eiso spent four years and $12 million pursuing an idea before the market cared* Why ChatGPT felt like vindication and brought Poolside back to open source* Why Eiso would prefer 100 foundation model companies over an oligopoly of five* The difference between releasing open weights and publishing genuinely open research* Why Poolside deliberately built a global research organization outside the Bay Area talent war* Why model building is ultimately 90% engineering* The Model Factory: Poolside’s end-to-end system for rapidly training and improving models* How fewer than 70 researchers run roughly 10,000–20,000 experiments each month* How Poolside moved from six-month model cycles to five- and eight-week launches* Why streaming data directly into training unlocked faster experimentation* How immutable data, versioned code, and reproducibility enable rigorous model research* Why Eiso wants capable researchers to leave their labs and become Poolside’s competitors* Why 95% of model building can be reduced to better data or compute efficiency* Laguna S and why persistence, verification, and backtracking can outperform raw intelligence* Why smaller models may handle far more knowledge work than previously expected* Why reinforcement learning will move earlier into pre-training* Why next-token prediction is still failing to extract enough knowledge from the web* Why distillation and environments have become the AI industry’s favorite “drugs”* Why mid-training is really an early form of curriculum design* Low-precision training, networking bottlenecks, and the next gains in compute efficiency* Laguna S: 118 billion total parameters, 8 billion active, and eight weeks from training to launch* Why model builders can often evaluate a new checkpoint within its first 30 minutes* Model versus harness: where agent capabilities actually come from* Why Poolside sees coding and long-horizon software tasks as a path to AGI* Why Eiso thinks MCP and traditional tool calls are “stupid”* Why future agents will write scripts instead of choosing from dozens of predefined tools* The case for minimal harnesses, containers, and model freedom* Why Poolside is prioritizing vision but does not expect to work on audio soon* Why language may be the most compute-efficient modality for encoding knowledge and reasoning* The real cost of model development and why the final training run is anticlimactic* The story behind the Poolside name and why it represents refusing to lower ambitions* How Poolside raised $500 million while investors still questioned whether AGI was real* Why intelligence could become the world’s most demanded and commoditized resource* When open models may become too capable to release without restrictions* Why unilateral AI safety does not work in a globally competitive environment* How regulation could accidentally lock in an oligopoly of two or three AI companies* NVIDIA, TSMC, and the hardware systems underpinning foundation-model progress* Why reinforcement-learning wall-clock time is one of Poolside’s biggest bottlenecks* Why Poolside trains models from scratch instead of simply distilling larger models* How AI changes the way companies should measure engineering productivity* Why agency may become the most important quality for employees in the AI era* How leaders align high-agency people through shared goals and clear constraints* Hiring across research, post-training, pre-training, architecture, evals, and engineering at PoolsideEiso KantLinkedIn: https://www.linkedin.com/in/eisokantX: https://x.com/eisokantPoolside: https://poolside.aiTimestamps00:00:00 Introduction00:00:54 Karpathy, RNNs, and Building Code Models Before Transformers00:02:26 The $12M Failure and ChatGPT Vindication00:03:39 Open Source and the Case for 100 Foundation Model Companies00:09:22 Open Weights, Open Research, and Poolside’s Global Team00:16:04 The Model Factory: Why Model Building Is 90% Engineering00:20:19 Agents, Automated Experiments, and Early Signs of RSI00:24:04 Streaming Data, Reproducibility, and Scientific Rigor00:30:35 Creating More Foundation Model Companies00:36:07 Laguna S: Persistence vs. Raw Intelligence00:43:01 Reinventing Pre-Training, RL, and Curriculum Design00:52:33 Low-Precision Training and Squeezing More From Smaller Models00:58:37 Model Harnesses, Coding Agents, and the Path to AGI01:09:26 Why MCP and Traditional Tool Calls Are “Stupid”01:13:04 Vision, Multimodality, and Why Language Still Matters01:18:15 Scaling Models and the Real Economics of Training01:20:40 Why Poolside Is Called Poolside and Raising $500M01:27:37 Open Models, AI Safety, and the Risk of an Oligopoly01:33:53 NVIDIA, TSMC, and the Reinforcement-Learning Bottleneck01:41:52 Smaller Models, Distillation, Engineering Productivity, and HiringTranscriptIntroduction: Eiso Kant, Poolside, and Open ModelsSwyx [00:00:00]: All right, we’re here in the studio with Eiso Kant from Poolside, together with Vibhu. Welcome.Eiso Kant [00:00:08]: Thanks. Thanks for having me, guys. Good to be here.Swyx [00:00:10]: Yeah, fresh on the plane. You texted me, you were like, “Hey, I’m on my way to SF.” I was like, “You’re on a plane right now, right?” Like, h...
Summary
🔬Causal Models Need Causal Data - Xaira’s X-Cell model for Drug Discovery (Bo Wang & Ci Chu, Chief Discovery Officer & Chief AI Scientist)
3d ago01:29:47Summary readyBet on informationIf test loss flatlines after 1.5B parameters while training loss continues to drop as you scale, that tells you that your model is limited by the amount of information in your data.Training on a single, smallish data set exposed an information gap: the 3.1B model falls off the scaling trend. Neither parameters nor compute will improve performance past this wall. For predicting changes to gene expression, you need more information rich data.This is what Chu and Bo’s teams have done, and here is what ~30x the information buys you:Now we can scale with parameters and training compute! We don’t know how much this effort costed, but we can guess that data collection experiments and infrastructure was a few tens of millions, and compute + headcount + research was a few million. The budget looks like a RL rollout budget, rather than a data rich pre-training one.We were lucky enough to have the two central figures in this story on our podcast. Taking the lead from Ci Chu and Bo Wang, Xaira Therapeutics is betting that information rich data is the key to AI-driven drug development. Chu was recently promoted to Chief Discovery Officer and Bo to Chief AI Scientist, underscoring just how strategic Xaira considers this bet.Reverse engineering the human cellIf you had to figure out how a human cell works, what would you do? A good place to start might be by documenting what genes are expressed (e.g. what RNA is floating around) in different kinds of cells, in different circumstances.That is CELLxGENE, a database of 168M cells built by Chan Zuckerberg Institute that maps each cell to a count of how many times 20K-30K genes were detected in that cell, plus detailed metadata about every cell. A ~4 trillion-entry matrix.If the Protein Data Bank (PDB) unlocked structural biology models (Boltz Episode, ESM/BioHub Episode), CELLxGENE has done the same thing for Virtual Cell models. Like PDB, CELLxGENE has inspired a zoo of AI models of RNA expression; so much so that RNA expression models have become synonymous with Virtual Cell models. Bo Wang built one of the most influential, scGPT, that became the starting point for Xaira’s new model.RNA expression ≠ Virtual CellModels trained on CELLxGENE describe the relationship between cell types and cell states, but they are not good at predicting what will happen if we make changes to RNA expression. Changes in gene expression are highly correlated, and its is difficult (impossible) to figure out what causes what in most cases.If you could “turn the dial down” on one gene at a time, however, then you would be able to observe what is upstream and downstream of a given gene. You could tell if A → B & C or B → A & C or B → A, C → B → … If you did this for all of the genes, then maybe you could train a model that could predict what would happen to a cell if you change a gene (e.g. with a drug or a gene edit). Or maybe you could figure out the least invasive way to change a particular gene’s expression.X-Atlas → X-CellThis is exactly what Chu and Bo’s teams have done. The data set is called X-Atlas and the model is called X-Cell.In this episode, we discuss:* Why the team abandoned autoregression for diffusion* The CRISPR-based experiments that run millions of tests in parallel, and generate the raw data for X-Atlas and X-cell* Generalization to real lab experiments in real human cells* Beating the linear baseline that has outperformed previous models* Justifying a kitchen-sink of priors, and how that stacks up vs. data and architectureBo also shared with us some of the (major) advantages he has as an academic vs. industry leader, and how his labs keep up with the breakneck pace of AI innovation.Check out the full episode on YouTube, or your favorite podcasting platform! This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
Summary
🔬 The Lab of the Future Should Feel Like a Data Center — Andy Beam & Rafa Gómez-Bombarelli, Lila Sciences
1w ago01:41:04Summary readyImagine a dark warehouse. Racks and racks of devices with wires, tubes, and electronics sticking out. The next AI data center? No. This is Lila Sciences‘ dream for the future of science. A dark warehouse full of AI-guided robotics and lab equipment, cranking out new experiments 24/7, building toward a scientific superintelligence.Their automated lab is almost hypnotizing to watch. They have floating plates zipping around on Wall-E-esque tracks, used vision-language models to control Windows 95 boxes, and created the world’s largest collection of voided warranties. In the process they’ve built a massive library of scientific reasoning tokens. Over 10 trillion of them, all experimentally validated.No warranties were voided in the making of this videoTo say Lila is ambitious is an understatement. Their goal is a scientific superintelligence wired directly into the wet lab. They are all in on the bitter lesson, and the thesis follows from it: a lab is an infinite token generator. Produce data at scale, and the synergies give you a general reasoner that can tackle any scientific problem. They are committing hard. Biology, chemistry, drug discovery, and materials science, all at the same time. Time will tell if it works, but it is an exciting hypothesis.In our latest episode we sat down with Lila’s very own Andy Beam (CTO) and Rafa Gómez-Bombarelli (CSO, physical sciences) and went on a journey through the possibilities of AI-run science, almost as wide-ranging as Lila’s goals.Did we mention they do both materials science and biology? In the same AI science factory? Same time, same lab, same AI. Finally a guest who can settle a long-running debate we’ve had amongst ourselves: is biology or materials science harder?Watch to find out!We discuss:* The internet is spent, science is next. Why Lila thinks the scientific method is the last untapped internet-scale dataset, and why they treat RL as a data generation mechanism with nature as the verifier.* The lab as a data center. Instruments as nodes on a graph, a magnetically levitating “PCI bus” transport layer between them, orchestration as a slurm queue. Andy is not short on analogies.* Why Lila insists it is not an automation company. They optimize for flexibility and generalizability over raw throughput, which means humans stay below the API line wherever automating does not pay.* Your experiment has a runtime. We put Escalante Bio’s question to Andy: if science is the token generator, what is the runtime of your data collection? His answer, in short, is that you cannot make the ribosome go faster. Why Lila bets on fast round-over-round iteration rather than big noisy multiplexed screens, and how Rafa’s team rebuilt a gas sorption measurement to run roughly 2,500x faster.* What is actually in 10 trillion scientific tokens. Not sequences. Experimentally verified reasoning traces, a kind of data that Andy argues exists on the internet in quantities that round to zero.* Breadth as a path to depth. Small molecule chemistry priors transferring to metal organic frameworks for carbon capture, and the claim that the general model beats domain-specific models sample for sample.* If you have the data, what do you need the model for? Sri Kosuri’s koan about the ML-for-drug-discovery business model, and Andy’s answer: the coding model got better because it also read Shakespeare and carnitas recipes.* The serendipity they want to automate. Emily Whitehead survived the first pediatric CAR-T cure only because the doctor treating her happened to know, from pediatric arthritis, which antibody would blunt her IL-6 response. Roll that dice again and you probably lose her. Breadth is how you stop depending on luck.* Move 37 for catalysts. Model suggestions for platinum-group-free electrocatalysts that went from boring, to what a 40-paper expert called stupid, to the best performers they have made.* Six months to in vivo CAR-T data in non-human primates, and the zero-FTE virtual startup commercial model that fell out of it. For context on why that number is startling, AbbVie paid $2.1B for Capstan on the strength of preclinical in vivo CAR-T data.* You cannot have scientific superintelligence if you are just a good test taker. Ken Stanley, who wrote Why Greatness Cannot Be Planned, runs open-endedness at Lila. RL at scale gives you a ruthlessly Vulcan problem solver. Machine creativity is a different thing, and it is the part nobody has solved.* The chain of thought is an unreliable narrator. The model reasons in latent space and only emits tokens. Sometimes it skips the experiment entirely and is still right. So how much do you trust the reasoning versus the verifier?* Reward hacking when the rollout is physical. Chains of thought that collapse into repetition, and a model that got annoyed and swore at the scientist who kept asking it to redo a plate map. What happens when a pathological loop has a wet lab inside it?* The bittersweet lesson. Rafa’s inversion of the bitter lesson: in AI, scaling is a roadmap. In materials, scaling is a filter, because only the things that scale end up mattering.* Not your typical Flagship company. Why a famously single-asset biotech incubator spun out a platform bet, and Andy’s line that if Lila called itself a biopharma it would have a top-three GPU cluster.* Bottlenecks they would remove by fiat. Sim-to-real for physics-based simulation, and the fact that RL training runs at roughly 5% mean FLOP utilization.Watch on YouTube: This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
Summary
Why AI Infrastructure must evolve for Agent Experience — Akshat Bubna, Modal CTO
2w ago00:57:55Summary readyWe’ve been running a bit of an Agent Cloud series surveying all the top inference/compute/cloud providers, from Databricks to Daytona to Railway and, even further back, E2B, but we’re excited to conclude this series returning to Modal, which has just raised a monster $355M Series C.The cloud was built for developers. But agents are now changing that.The old infra stack was designed for a human who could read docs, reason through YAML, and understand dashboards to figure out what they need when something broke. While this was painful for developers, it worked since they could fill in missing context in their heads.However, agents don’t have that luxury. Now in this new era of agents, everything has to be tighter.They need a place to write code, run it, inspect the output, change the environment, debug failures, and try again. Fast iteration and feedback loops with all the necessary context are crucial for agents to operate properly. Furthermore, sandboxes are a clear representation of this shift as agents can easily spin up isolated environments. This programmatic infra even extends to research:Two years ago, we were one of the first to cover Modal with CEO Erik Bernhardsson and Alessio designed our favorite LS thumbnail of all time:At the time, Modal was just a teeny little company with a $17M Series A.Today, fresh off their $355M Series C, Modal is one of the clearest examples of the agent cloud future being built in real time: a cloud platform moving past traditional web app assumptions toward the workloads AI actually creates such as elastic inference, sandboxes, GPU burst, post-training, background agents, and infrastructure that agents themselves can operate.In this episode, Modal CTO Akshat Bubna joins swyx and Vibhu to unpack why AI applications don’t fit traditional cloud assumptions, why Kubernetes was never designed for bursty compute-heavy workloads, and why Modal is now shifting from developer experience to agent experience.We go deep on Modal’s AI infra stack: serverless functions, decorator-based infrastructure, elastic inference for custom models, GPU snapshotting, DeFlash, speculative decoding, Auto Endpoints, sandboxes, persistent storage, networked containers, private IPv6, RDMA, multi-node training, and Modal’s capacity pool across 17 cloud providers. Akshat also explains why RL rollouts can require 100,000 sandboxes, why production agents need hard guardrails, why observability may matter more than reading code, and why AI has made infrastructure exciting again.We discuss:* Why Kubernetes wasn’t built for bursty AI workloads* How Modal started as a better runtime before becoming an AI cloud* Why Modal added GPUs before ChatGPT* The shift from developer experience to agent experience* Why observability matters when agents are writing the code* Elastic inference for custom models across audio, video, robotics, and comp bio* GPU snapshotting, cold starts, and why inference workloads are so bursty* Why RL rollouts can require 100,000 sandboxes* DeFlash, speculative decoding, and frontier-level inference performance* Auto Endpoints and making optimized inference easier to deploy* What Modal adds beyond vLLM, SGLang, and raw GPU rental* Modal’s 17-cloud capacity pool and supercloud strategy* Networked sandboxes, sidecars, private IPv6, and RDMA* Serverless multi-node training for post-training and research workloads* Auto-research, model-guided sweeps, and agents launching GPU experiments* Compute strategy, capacity planning, and batch tiers* Why production agents need specialized sandboxes and hard guardrails* Modal’s take on managed agents, CI, Gitpod/Ona, Python, TypeScript, and Modal BenchAkshat Bubna* LinkedIn: https://www.linkedin.com/in/akshat-bubna-188885103* X: https://x.com/akshat_bModal* Website: https://modal.comTimestamps00:00:00 Introduction00:00:39 Modal’s origin and why Kubernetes wasn’t enough00:04:32 Developer Experience → Agent Experience00:06:21 Modal’s AI cloud primitives00:09:14 Sandboxes, agent loops, and proto-Cognition00:12:12 Elastic inference, GPU snapshotting, and 100,000 sandboxes00:15:24 DeFlash, speculative decoding, and Auto Endpoints00:19:59 Production-grade inference beyond raw GPUs00:22:00 Background agents, Ramp Inspect, and the agent lifecycle00:24:08 Modal’s 17-cloud supercloud strategy00:26:40 Networked sandboxes, private IPv6, and RDMA00:32:48 Multi-node training, post-training, and auto research00:37:36 Compute strategy, capacity planning, and batch tiers00:40:55 Open models, real-time AI, and production agent infra00:43:06 Hard guardrails, managed agents, and specialized sandboxes00:46:06 Why AI made infrastructure exciting again00:48:30 Model APIs, differentiated products, and agentic video00:51:50 CI, coding-agent infra, SDKs, and Modal Bench00:57:28 Closing ThoughtsTranscriptIntroduction: Modal, Series C, and the Art PartySwyx [00:00:00]: We’re here with Akshat, CTO of Modal, together with Vibhu. Congrats on your Series C.Akshat [00:00:10]: Thank you.Swyx [00:00:11]: Your party yesterday was amazing.Akshat [00:00:15]: Yeah.Swyx [00:00:15]: From all the photos and all the swag.Akshat [00:00:17]: We had a bunch of art installations, which was fun, seeing, like, our products on pedestals next to, like, Rodin.Swyx [00:00:25]: Very nice. Very nice. When you started, it was not the GPU inference company. Maybe it was in your mind. Take us back to the origin story.Modal’s Origin: A New Runtime Beyond KubernetesAkshat [00:00:39]: I first met Eric, who’s the CEO, through an investor. Back then Eric was already thinking about building, a new runtime, and he got there thinking through why are workflow orchestration products so hard to use. It’s because you have to run them on Kubernetes. Kubernetes is hard to manage. It’s not built for burstiness and, custom images,Swyx [00:01:03]: YeahAkshat [00:01:03]: It has a terrible developer experience.Swyx [00:01:05]: And I’ll, I’ll interjectAkshat [00:01:06]: YeahSwyx [00:01:07]: For listeners, who are new, we interviewed Eric two years ago, and there’s a bit more of the story there from Spotify and all those things.Swyx [00:01:14]: And I came across Eric through Data Council because he did that talk on the serverless container stack that you guys did, which was like, that was my first like, “Okay, I need to take Modal very seriously” moment.Akshat [00:01:26]: Yeah.Swyx [00:01:26]: But it was still very unclear, like, do I need all this for just my data pipelines?Akshat [00:01:33]: Yeah. initially what we were thinking about was if we build a better runtime, it’s a very useful primitive in itself. It’s There’s a lot of things that, get solved by serverless functions, like you can do, ETL stuff, you can do job queues, you can do all this, like, bursty processing, which it turns out every company had needs for. but then we also were thinking about this as like, this is a primitive that we can build a whole collection of products on, which are very verticalized. So perhaps data engineering would’ve been the first one, but we were thinking about inference. Back then it was more classical inference, like computer vision stuff and running XGBoosts and whatnot. But we added GPUs to the product a year before ChatGPT came out.From Serverless Containers to GPU WorkloadsSwyx [00:02:19]:</stron...
Summary
🔬 The Coolest Diffusion Research Isn't in LLMs — Evan Feinberg & Sergey Edunov, Genesis Molecular AI
3w ago01:48:39Summary readyThis episode has a fun personal twist: There’s a counterfactual world where I was employee #1 at Genesis Molecular AI, the company behind today’s episode. A certain introduction happened a few weeks too late and I had already happily signed at Atomwise, another ML-for-drug-discovery startup. Same problem, different company. I was certain ML was going to transform small molecule drug discovery. Early results were underwhelming. Useful at times, but nowhere near revolutionary. In the last year I’ve seen signs that ML is finally ready to deliver on my convictions from a decade ago. Genesis is one of the places that might have finally cracked this problem. I was super excited to come full circle and catch up with co-founder Evan Feinberg and CTO Sergey Edunov.If you are at all interested in small molecule drug discovery, we think you will find this fascinating!In our nearly two hour chat we cover:* What is small molecule drug discovery, and why is it hard* Structure prediction as a hotbed of innovation in AI algorithms* How advances in AI elsewhere have enabled stepwise improvements in predictive power* How the community benchmarks are essentially calling AI slop good enough* The Genesis flagship model (PEARL) can routinely hit a threshold that is necessary for real-world applications* New agentic workflows enabled by these highly accurate modelsRead on for more, and also some personal thoughts on the future at the end.The coolest diffusion research is happening at GenesisSergey Edunov came to Genesis from Meta where he led Llama 2 training and Llama 3 pretraining. Sergey was a former physicist who thought he was done with physics after many years of training LLMs. Then, he discovered Genesis, and was blown away with all the novel architecture work they’ve been developing.It probably surprises no one that modern LLM research has not resulted in fundamentally novel or exciting updates in architectures since almost the advent of the transformer — the entire field is using variants on the same idea that came out in the original “Attention is all you need” paper. Sure, some were quite useful (mixture-of-experts in particular allowed for the massive model paradigm we’re at today), but there was very little conceptually exciting.“We sort of had to wait for the right primitive to get created, and that turned out to be diffusion… Actually, some of the most innovative diffusion research that’s happening in our field is happening in 3D structure prediction right now.” — Evan FeinbergThe field of 3D structure prediction on the other hand has been a hotbed of research. Genesis’ recent model PEARL (Place Every Atom at the Right Location) is able to understand protein flexibility, and model not just where the ligand goes, but also make small adjustments of the protein so that the two fit better than either alone. The field knew this was missing for a long time, but it was really hard to model until now.Agentic DiscoveryWhat makes this problem so hard? As Sergey points out, there are 10^60 possible drug-like small molecules. You’ll never be able to search them all, and trying to find the good ones is something like finding a needle in a haystack — except everything except your needle is dangerous.“There are 10 to the 60 drug-like small molecules in the universe… it’s like finding a needle in a haystack, where everything except your needle is very, very dangerous.” — Sergey Edunov“Or finding hay in a needle stack might be a more apt analogy.” — Evan FeinbergTrying to solve the multi-parameter optimization problem is even worse. What makes a strong binder and a molecule with good “ADMET Properties” are oftentimes at tension with each other. For example, a good binder is likely greasy, but a greasy molecule is likely insoluble so it won’t enter the bloodstream and get to where it needs to go!Genesis’ advances in generative AI have now pushed them beyond the threshold where they believe agentic drug discovery loops are finally possible. We all remember the early days of LLMs. They were great chatbots but terrible agents, as small errors compounded rapidly into uselessness. As LLMs got better, the usefulness of agents rapidly improved. Evan and Sergey argue that their models at Genesis recently passed a similar threshold. Their internal agentic drug-discovery system (code named SAPPHIRE) can now iterate like a chemist: look at and reason about poses, form hypotheses, read literature, use internal tools, create candidates for the next iteration. Combining this with automated lab partnerships like the one Genesis has with Incyte, we’re rapidly approaching a time of drug discovery agents running 24/7 making/testing new molecules. Exciting times!Benchmark crisis: Everyone’s favorite benchmark is slopOne surprising point that isn’t talked enough about: the academic field of “co-folding” has settled on a benchmark value of “2 Angstrom RMSD” as a metric for a “good pose”. Evan does not mince words: this threshold is just bad. Perhaps even deceptively bad. For many strong binders, there’s a very clear pose, one that you can even directly resolve in the PDB electron density! And yet, with a 2Å RMSD threshold, you can get the pose quite wrong in ways that might even mislead a medicinal chemist. For example, flip around an aromatic ring, and everything looks reasonable, but you’re no longer modeling the right interactions.Evan makes the strong claim that 1Å RMSD is really the threshold necessary to ensure the core of the molecule is sitting where it needs to be, and models all interactions.“If your model is sitting at 1.8, 1.9 Angstrom RMSD, that’s slop, most likely.” — Evan FeinbergAs a simple example, he points out hydrogen bonds which are responsible for many of the most important interactions in protein-ligand systems. Hydrogen bonds only have a 0.6Å range to be valid! Clearly if you’re accurately resolving all H-bonds, you generally have to be doing much better than the 2Å threshold.This is clearly a hard-fought lesson for Evan and Genesis. In their opinion, the community is stuck on these benchmarks because academics developing methods were not users. Evan does see signs of life, with the use of new metrics such as lDDT for co-folding. Hopefully soon the community can agree that “1.8Å RMSD is slop”, and start hill climbing on this much harder task.For a more thorough exploration of the weaknesses in conventional benchmarks, see the PEARL technical report.PEARL tops OpenBindWhich makes what happened next all the more striking. Near the end of the podcast, we talked about a recent “proof-is-in-the-pudding” moment for Genesis — evaluating their PEARL model on a recently released OpenBind benchmark. This benchmark featured 802 never before seen co-complexes on a target protein EV-A71. This target seems almost custom-chosen to give most classical docking methods a problem. When a ligand binds to the main binding site, the protein moves around to close off the path the ligand used to enter the binding pocket. This process, known as “induced fit” is notoriously hard for traditional methods to model. The tradeoff is easy to understand: treating the protein as a static structure, it becomes difficult to place a ligand in a binding pocket. Treat the protein as dynamic, and now you have to simulate complicated processes that take a long time to resolve.PEARL was able to model the induced fit of the ligand without running long MD simulations. Across the different evaluation metrics, PEARL came out not just ahead, but oftentimes well ahead of any public model. A truly impressive result.“Where PEARL was exceptionally good is figuring out how to move this loop. We are basically correct for every single pose.” — Sergey EdunovEven more exciting, this was done without any fine-tuning, or using any data on the target or homologous targets — the template PDB was released after PEARL’s training cutoff.Where does co-folding go now?As someone who has followed or participated in ML techniques for protein-ligand interactions for almost a decade, I was genuinely impressed with the results that Genesis has released recently. This has been many years in development, and I’m sure Evan and the team had many sleepless nights trying to get to this point. I also think other teams are making similar progress — both Isomorphic and Deep Origin have released results that seem spiritually similar and combine computation, wetlab data, ML, to achieve genuine predictive power that seemed impossible a decade ago. Sadly, all of the above are closed source so there’s no way to honestly compare them. Looking at the results I think there might be a time in the not so distant future where we can consider protein-ligand binding “solved”.I sincerely hope that the academic community can take inspiration from these developments. Once you know something can be done, it’s much easier to execute. Still, I believe that the key enabler in all of the above was the tight integration of ML, large-scale computation, and real-world drug discovery applications. Sadly academia is just not structured in a way that makes such a development easy.With those parting thoughts, we hope you give the podcast a listen! This is a public episode. I...
Summary
Why the Frontier Ecosystem must be Open — Matei Zaharia and Reynold Xin, Databricks
Jun 2401:08:52Summary readyWe’re excited to have Databricks join us at AIEWF, among hundreds of the top companies in the AI Engineer ecosystem. LS subscribers can use their discount to get past the late bird pricing and access over $50k in sponsor offers! Everyone is still talking about Satya’s Frontier Ecosystems post, but few have actually built a (now $175 billion) frontier ecosystem and cloud like our guests today.From open-sourcing the layer above coding agents to rethinking databases for the agent era, Databricks cofounders Matei Zaharia and Reynold Xin are pushing the company beyond the lakehouse into a full data-and-AI operating system. In this episode, Matei and Reynold join swyx at the 2026 Data + AI Summit to unpack Omnigent, LTAP, Lakebase, agent security, open formats, Mosaic, and why databases may matter more than ever once AI agents start doing real work.We go deep on Omnigent: Databricks’ open-source meta-harness for combining, controlling, and sharing agents across Claude Code, Codex, Cursor, Pi, custom agents, and internal tools. Matei explains why coding agents and enterprise agents run into the same problems: portability, collaboration, session history, security, spend controls, and the need for a common API above every harness.Then Reynold walks through Databricks’ database dream: why CDC is brittle enough to joke that it means “continuous data corruption,” why HTAP has been the holy grail of database engineering, and why Databricks thinks LTAP gets most of the benefits by unifying the storage layer instead of collapsing every query engine. We also cover Databricks’ infrastructure scale, the culture behind rapid prototyping, the difference between tech and enterprise customers, Databricks vs Snowflake, whether vector databases should have ever existed, the Mosaic model strategy, Genie, AI Runtime, RL fine-tuning, and the thesis that traditional software gets rewritten once the data is in the right place and agents sit on top.Databricks began as a company for the big data era. The origination of Spark from the Berkeley AMPLab which eventually turned into the product Lakehouse convinced enterprises that they didn’t need a separate data lake, warehouse, ML platform, and governance layer. They just needed one open foundation where all of their data could live and be reasoned over.Since then a lot has changed, but data has only become more important. Data is no longer something you keep track of and analyze ad hoc, it’s the necessary context agents need in order to act. So the framing has shifted from “where do we put all of our data?” to “how do we expose the right slice of state, history, permissions, and business logic to an AI system at the exact moment it’s doing work?”If frontier model performance becomes commoditized, the durable advantage then becomes the company-specific context around them: proprietary data, governed access, operational state, transaction logs, workflows, and feedback loops. Which makes Databricks positioned perfectly.Now coming fresh off the Data + AI Summit 2026, the company is moving just as fast to keep up, announcing Genie One, Omnigent, LTAP, and many more, indicating a central mission in its newer work: Databricks is trying to become the operating system for enterprise agents.Models are getting good enough, but agents are only useful if they have the right context, permissions, memory, state, cost controls, and access to live business data. Fundamentally it appears that significantly better model performance in production is a systems problem, one that data guys like us are remarkably well prepared to solve!We discuss:* Why Databricks built Omnigent as a meta-harness above existing AI agents* Why coding agents and custom enterprise agents need the same infrastructure* The common API for agent sessions, files, streams, tool calls, and cancellation* Why persistent sessions, cloud sandboxes, sharing, search, and collaboration matter* Why Databricks open-sourced Omnigent instead of keeping it proprietary* Databricks’ internal agent usage, cloud sandboxes, and coding workflows* The scale of Databricks: 50–60 million virtual machines a day and exabytes before breakfast* Why agent security needs contextual and stateful policies* How an agent could read confidential docs, install a compromised npm package, and leak data* Why spend control matters when an agent can burn $500 reading logs* Startup opportunities around coding-agent analytics, quality, skills, and spend* LTAP, Lakebase, and why Databricks wants to rethink the database stack* OLTP vs OLAP, CDC, and why data pipelines break at 3 a.m.* Why HTAP has historically been the holy grail of database engineering* Why Databricks thinks LTAP is “HTAP done right”* How writing transactional data into column-oriented formats changes analytics* Why agents need live operational context from databases, not just telemetry* How Databricks prototypes strategic systems without endless process* Enterprise vs tech customers, governance, procurement, and DIY culture* The “second system syndrome” risk of rewriting a database engine* Building a database engine from a decade of traces and quadrillions of data points* Why vector databases should never have been a separate category* Why open formats and AI changed the race with Snowflake* The Mosaic story, DBRX, Genie, document parsing models, and specialized model training* Why model customization and RL fine-tuning may become mainstream* Why “get the data there, slap some agent on top” may rewrite traditional softwareMatei Zaharia* LinkedIn: https://www.linkedin.com/in/mateizaharia* X: https://x.com/matei_zahariaReynold Xin* LinkedIn: https://www.linkedin.com/in/rxin* X: https://x.com/rxinDatabricks* Website: https://www.databricks.com* X: https://x.com/databricksTimestamps00:00:00 Introduction00:02:22 Omnigent and the Agent Infrastructure Layer00:08:39 Agent Clouds, Common APIs, and Open Source00:16:52 Databricks Scale and Internal AI Workflows00:18:03 Agent Security, Governance, and Spend Controls00:27:34 LTAP and the Database Dream00:30:30 CDC, HTAP, and Why Data Pipelines Break00:34:05 Lakebase, Parquet, and Live Data for Agents00:36:47 Databricks’ Culture of Fast Prototyping00:43:40 The Dream Engine and Rewriting the Database Stack00:51...
Summary
Red-Teaming after Mythos — Zico Kolter & Matt Fredrikson, Gray Swan
Jun 2201:06:23Summary readyAI Engineer World’s Fair regular bird tix will sell out ~today! Join us next week ahead of the Late Bird price hike and get >$40,000 in sponsor credits for attending!Thanks to the US Government issuing an export control directive on Mythos and Fable, the risks of jailbreaks and (industry term) indirect prompt injection are suddenly the talk of the town, though we have been covering AI security for a few years now, from Hackaprompt to the enigmatic Pliny the Elder.Zico Kolter, member of OpenAI’s board of directors on the Safety & Security Committee, and Matt Fredrikson, CMU professor and CEO of Gray Swan, co-authored the definitive paper on Indirect Prompt Injections, and Gray Swan were cited authorities on the Mythos model card, directly investigating the exact capabilities that are under scrutiny right now:We seized the opportunity to ask them the state of AI Red Teaming, and Shade, the adversarial red teaming tool that Anthropic used to evaluate the robustness of their models against prompt injection attacks in coding environments. Shade is part of their overall toolkit covering Simon Willison’s Lethal Trifecta, including Cygnal, an AI guardrails product, and the world’s largest AI Red Teaming Arena, including AIRT celebrity Wyatt Walls.All of this security tooling, and yet, we’re only staving off the inevitable.The risks of extremely smart AI increasingly feel like gray swan events: an event that everyone can see coming. In this episode, Gray Swan cofounders Zico Kolter and Matt Fredrikson join swyx to explain why AI security is not just “cybersecurity with AI,” why agents introduce a new class of vulnerabilities, and why the next major AI incident may be a gray swan: unlikely, but clearly visible before it happens.We go deep on prompt injection, automated red teaming, model robustness, agent identity, computer-use agents, enterprise guardrails, and the emerging AI insurance/compliance stack. Zico and Matt also explain why frontier models are not automatically safer as they scale, why specialized red-teaming models can now beat humans at breaking AI systems, and why the future of AI security may depend on AI systems attacking, defending, and interpreting other AI systems.We discuss:* Why AI systems need a different security mindset from traditional software* How prompt injection creates a new exploit class for agents like Codex and Claude Code* Gray Swan Arena and the rise of community red teaming* Shade: AI that can outperform humans at breaking models* Why LLMs are an alien form of intelligence that fail differently from humans* Human vs browser-agent robustness and why humans ranked fourth* Why eval awareness and capability elicitation matter* Cygnal: Gray Swan’s guardrail model for policy enforcement* Why bigger models do not automatically become more robust* The lethal trifecta: untrusted data, private data, and exfiltration* Why “just prompt it better” is not enough for enterprise AI security* OpenClaw, computer-use agents, and the agent security nightmare* Agent-native identity, permissions, and enterprise deployment* Why AI security may become part of insurance and compliance* Why the first major AI prompt-injection breach may be inevitableGray Swan* Website: https://www.grayswan.ai/Zico Kolter* X: https://x.com/zicokolter* Website: https://zicokolter.com/* LinkedIn: https://www.linkedin.com/in/zico-kolter-560382a4/Matt Fredrikson* Website: https://www.mattfredrikson.com/* LinkedIn: https://www.linkedin.com/in/matt-fredrikson-7596349/Timestamps00:00:00 Introduction00:02:31 Why AI Security Is Different00:06:38 Testing Claude, Codex, and Prompt Injection00:07:47 Gray Swan Arena and Automated Red Teaming00:11:14 AI That Breaks Models Better Than Humans00:14:00 LLMs as Alien Intelligence00:19:00 Humans vs AI Agents00:24:35 Red Teaming, Jailbreaks, and Capability Elicitation00:26:11 Cygnal: Guardrails for AI Agents00:34:04 The Lethal Trifecta00:39:31 Can AI Automate AI Research?00:45:47 OpenClaw and the Computer-Use Security Problem00:50:44 Agent Identity, Permissions, and Enterprise AI00:54:24 The Future of AI Security01:00:30 AI Insurance and Compliance01:04:32 The Gray Swan Event Everyone Sees Coming01:06:04 Closing ThoughtsTranscriptIntroduction: Gray Swan, AI Security, and CMUSwyx [00:00:00]: We’re here in the studio with Gray Swan, Matt and Zico. Welcome.Zico [00:00:08]: Great to be here.Matt [00:00:09]: Thanks for having us.Swyx [00:00:10]: You’re visiting from Pittsburgh? The home of all good computer science. I don’t know if I’m overstating things. A very strong university.Zico [00:00:18]: CMU has been the center of a lot of AI since really the dawn of the field.Swyx [00:00:22]: Especially a lot of self-driving and some language learning. Congrats on your Series A. You’re here because you’re attending Snowflake Summit, and Snowflake is one of your investors. Let’s introduce crisply at the top: what is Gray Swan, and what have you chosen as your startup domain?Matt [00:00:42]: At Gray Swan, our mission is to empower everyone to use AI safely and securely. Large language models are software, and if you want to deploy them or build applications on top of them, you need to understand the vulnerabilities and what can go wrong. That includes everyday mistakes, like an agent making the wrong tool call, but also worst-case scenarios where an attacker has an incentive to make your agent misbehave, leak data, or steal credentials. Gray Swan grew out of our research at Carnegie Mellon, where Zico and I have spent over a decade studying new vulnerabilities and attack surfaces in deep learning systems: how to test for them, understand their severity, and make inference more robust.Adversarial Examples and Why AI Security Is DifferentSwyx [00:02:05]: Honestly, a very fruitful area of study for any academic. Throwback, this is 10 years ago, which is basically the entirety of me. I got a lot of inspiration from Ian Goodfellow, a friend of the pod, and this is one of those initial adversarial settings.Matt [00:02:23]: This paper was directly inspired by Ian’s work.Swyx [00:02:29]: Zico, what about your side of the story?Zico [00:02:31]: Like Matt, I have been faculty at Carnegie Mellon for a while. Fundamentally, we believe in the transformative power of AI. It has already transformed the software ecosystem, and it will transform many other ecosystems going forward. The issue is that these systems behave very differently from the software we are used to. I do not just mean that AI can find vulnerabilities in software, though it can. I mean that AI systems have inherent vulnerabilities of their own. They can be tricked in ways people can be tricked, so you need a different security mindset.Zico [00:03:23]: This ma...
Summary
The Professor of Outputmaxxing — Anjney Midha, AMP
Jun 1800:59:25Summary readyLast 4 days before regular tickets sell out at AI Engineer World’s Fair - this is the single biggest gathering of AI Engineers, Founders, Leaders, and Researchers in the world. Attendees get >$5000 worth of sponsor credits and talk tracks are looking FANTASTIC. Join us!The AI scaling debate always focuses on the question of “how do we get more GPUs?” but the better question may be: how do we make the most of ones we already have.The fact that a frontier lab like xAI could be running at sub-10% MFU (Model FLOPs Utilization) is just a hint at what the real problem may be.For context, older frontier-scale training runs were already much higher than 10%. GPT-3 was around 21% MFU. Gopher was around 32%. Megatron-Turing NLG was around 30%. PaLM reached around 46%. And our guest Anjney says best-in-class MFU today is closer to 60–70%.It’s not necessarily that xAI is uniquely incompetent (it’s clear they have talented folks) but rather the priorities may be flipped in the GPU arms race.While GPU access is a bottleneck, simply increasing CapEx won’t automatically translate to better models as frontier AI is increasingly a systems problem: scheduling, utilization, networking, kernels, frameworks, data pipelines, parallelism, cluster reliability, and the thousand small decisions that determine whether your theoretical FLOPs become real training progress.From building Discord’s developer platform and backing frontier AI companies like Anthropic, Mistral, Black Forest Labs, and Periodic Labs to now building AMP’s independent compute grid, Anjney Midha has spent years close to the real bottlenecks of AI scaling. In this episode, Anjney joins swyx at Periodic Labs to unpack why the AI race is not just about buying more GPUs, why 95% utilization would have been considered an outage at Google, and why the next era of AI infrastructure has to be more aligned, more efficient, and more responsible.We go deep on AMP’s vision for a compute grid that makes FLOPs flow like megawatts, the difference between full-stack AI labs and horizontal pooling, why AI data centers need community buy-in, and how compute markets could evolve into something closer to an independent system operator. Anjney also explains why DeepMind’s unpublished research points to a market failure, why end-of-life prediction remains one of the most important AI applications he has thought about for fourteen years, and why “output maxing” may become a new discipline for frontier systems.We also discuss Anthropic’s culture, why “luck favors the prepared mind” in coding models, how Claude cracked coding, why too much capital too early can make AI labs fragile, what Periodic Labs is trying to do with science and superconductors, why great researchers can become great CEOs, and why Silicon Valley is both deeply missionary and deeply mercenary.We discuss:* Why 95% utilization was considered an outage at Google* Why AI infrastructure waste compounds at frontier-lab scale* Why “move fast and break things” does not work for AI data centers* How data center backlash, power grids, and community incentives shape AI scaling* AMP’s vision for making FLOPs flow like megawatts* Why compute needs an independent system operator* How interruptible demand and dynamic prioritization worked inside Google* Why DeepMind research hoarding creates negative externalities* AMP’s 1.2GW base-load ambition and the need for 6GW of spike capacity* Why end-of-life prediction could become one of AI’s most important healthcare applications* Frontier Systems, output maxing, and full-stack alignment* Why APIs and abstraction layers become lossy as organizations scale* Superconductors, standards, and the dream of lossless systems* SF Compute, open protocols, and the future of compute marketplaces* Why non-NVIDIA chips can still benefit from NVIDIA’s reference architecture* Trust boundaries and why chip startups need visibility into future model architectures* Why VCs often underestimate researchers as CEOs* Scientists as star athletes of the mind* Why great CEOs need to be confrontational up and down the stack* Why leading the frontier matters more than “winning”* How Anthropic cracked coding* Why culture is fragile, not a permanent moat* Why hardship was a feature, not a bug, for Anthropic* Why Anthropic’s P0 was coding from day one* Periodic Labs, physics as the constraint, and technical reality* Silicon Valley mercenaries, missionary teams, and what happens after a breakthroughAnjney Midha* LinkedIn: https://www.linkedin.com/in/anjney* X: https://x.com/AnjneyMidhaAMP PBC* Website: https://amppublic.com/* X: https://x.com/amppublicTimestamps00:00:00 Introduction00:00:09 Why AI Compute Is Being Wasted00:03:17 Responsible Infrastructure and Data Center Backlash00:06:07 AMP Grid: Making FLOPs Flow Like Megawatts00:12:41 Foundry, Frontier Labs, and Research Hoarding00:14:42 Gigawatt-Scale Compute and End-of-Life Prediction00:24:08 Frontier Systems, Output Maxing, and Alignment00:27:38 Compute Markets, SF Compute, and Non-NVIDIA Chips00:32:57 Trust Boundaries, Co-Design, and Researcher CEOs00:38:17 AI Coachella and First-Principles Thinking00:42:43 Leading vs Winning in Frontier AI00:45:54 How Anthropic Cracked Coding00:48:25 Culture, Hardship, and Anthropic’s P000:54:03 Periodic Labs, Physics, and Silicon Valley Mercenaries00:56:26 Rishi Valley, Singapore, and Money as a Measure00:58:47 Closing ThoughtsTranscriptIntroduction: Anjney Midha, AMP, and Compute WasteSwyx [00:00:00]: We’re in Periodic Labs with Anjney Midha, CEO, founder of AMP. Welcome.Compute Utilization: Node Allocation, MFU, and AlignmentAnjney [00:00:09]: Thanks for having me. At Google, there are two types of utilization usually, right? That you’re measuring in these clusters. One is node allocation, and then the other’s MFU. Node utilization is usually like what percentage of cards in the data center are just, used, and that, if it’s not at, 95%-Swyx [00:00:29]: There is no excuseAnjney [00:00:29]: There’s no excuse, right? I think 95% at Google, which is where my co-founder, Seb, came from, he built the Borg, PBorg/GQM scheduler at Google, and there I think 95% was considered an outage, so 96% node utilization is, should be standard. And most single-tenant clusters are not running at that. So that’s one. And then MFU should be, I would say the best in class today is somewhere between 60 and 70%. I think this is a leadership question, right? Fundamentally it’s an alignment question, which is are the people who are funding the cluster and then deploying the cluster actually aligned? And sometimes theoretically they are, but in practice the number of people in the chain, the supply chain between, the capital and all the way to whoever’s managing the cluster and then whoever’s measuring what the output is, are just so many, degrees of separation away that, the, The Have you ever heard the radian metaphor, which is at the beginning of an arc, if you have two arcs that are two lines that are just off by a few degrees, that-Swyx [00:01:33]: It spreads outAnjney [00:01:34]: It spreads out, right? Or at scale. And I think what’s happening is a lot of cluster implementations and infrastructure, a lot of frontier labs and other teams, that’s what’s happening, is they’re, they initialize the plan, which is kind of like North Star with a team that wants to do good, but then they’re, required to scale so fast instead of iteratively that the wastage just compounds really fast at scale. And so I think we know the answer, which is just do iterative bring ups. If you spend time with people who’ve been in the semiconductor industry or the DSN industry for a long time, this is not new, and I don’t think AI should be an excuse. Sure. Something What is new? Okay. We have a lot of new capabilities, but that doesn’t mean just abandon common sense. Common sense should always be in fashion. ? AI scaling doesn’t change the in fact, if anything, AI scaling should be put...
Summary
🔬 The Self-Driving Lab — Joseph Krause, Radical AI
Jun 1701:16:50Summary readyOn the Science pod, we’ve been covering a lot of the ground on how AI is revolutionizing STEM, but one of our favorite off the record topics since our launch is which field is harder to accelerate: math, bio, or physics? Today we’re back in Materials Science land with Radical — Unlike biological molecules that can be represented (and predicted!) by token strings, the success of materials involve many more macro complex variables like supply chains, microstructures, and manufacturing processes. If you recall the LK99 drama of 2023, while the basic ingredients were known, part of the confusion came from the lack of disclosure around manufacturing, and therefore defeated reproducibility. There is probably no "one-shot" model capable of designing a material that works perfectly at scale.How Radical is accelerating materials discovery >10x the pace of DARPA/GE MACHJoseph Krause is a materials scientist through and through. And after spending his career watching industries stall out waiting for better materials, he founded Radical AI to do something about it.We recently sat down with Joseph to talk about Radical AI, materials discovery, self-driving labs, and the future of AI science. Joseph did not sugar coat anything: accelerating the materials discovery pipeline is a hard problem. But it’s one that he strongly believes we need to invest in, for the future of consumer products, aerospace, computing, and defense, and get them into every day use:“We count it as a discovery when you pick up your phone and there’s a new material sitting inside of it.”How does Joseph plan on accelerating the rate of discovery? To understand this, it’s important to understand why this is such a hard problem in the first place. The first thing to keep in mind is that the material that is manufactured is far more than a chemical formula going into it. The process of mixing, annealing, growing, or generating the final material can result in wildly different outcomes. The entire materials discovery process, both from early discovery to large scale manufacturing, needs to be understood and characterized.The Self-Driving LabThis philosophy has grown into a key insight at Radical AI: The construction of the self-driving lab. This lab is one that is not just automated, but in fact uses an “AI scientist” that combines scientific knowledge, computational techniques, and human intuition to generate and test hypotheses in an automated lab. Creating an AI scientist was key to making Radical’s self-driving labs work, since Joseph argues that no single AI model can one-shot materials.“In materials, the ground truth is the material itself. You have to be able to test it and characterize it.”Joseph talked at length about the self-driving labs at Radical. Joseph argues that experimental data is the true “moat” in this industry. An SDL functions as a closed-loop system where an AI scientist generates hypotheses, and automated robotics synthesize and characterize materials, running research campaigns in parallel rather than serially. The successes here were both on the automation side and on the science side. Radical has managed to scale their alloy discovery pipeline up to producing and characterizing 1200 alloys in six months — this nearly 10x speedup over the DARPA/GE MACH program that aimed to create 500 new alloys in a year. Joseph claims they can scale this up even more and estimates they can produce a hundred new alloys tested and characterized in a day. A truly new paradigm in high-throughput alloy experimentation.On the science side, their AI scientist proposed and tested 300 new materials, ten of which were found to have novel state-of-the-art properties that are already being further developed for commercial applications. The robustness of this first materials campaign reinforces Joseph’s claim that the moat is the lab and data.“It’s moved into elemental families or alloy families no one has ever published on before.”Interestingly, Radical’s AI scientist has made some novel discoveries, expanding into elements that just were not explored prior. This is fascinating from a scientific perspective, but it’s also important for helping reduce supply chain bottlenecks for vital industries!Joseph spent a lot of time in D.C. before founding Radical, and he’s clear-eyed about the competitive threat. China’s centralized model lets it stand up manufacturing hubs and immediately scale new materials from lab to production. We can’t replicate that, and Joseph is very clear we shouldn’t try. But we do need an answer. For Joseph, that means transforming the scientific workforce, investing in self-driving lab infrastructure at the national lab level, and leaning hard into public-private partnerships.“Now imagine every scientist in the United States doing 10 times the research output. That’s fundamental. That just changes the trajectory of discovery.”Before we close, we’d like to give a shout out to Joseph and Radical for publishing and open sourcing much of their internal tooling pipeline. This includes:* TorchSim (preprint, blog): an open-source PyTorch-based MD simulation framework, which has been spun off into its own non-profit.* MATRIX/MATRIX-PT (preprint, blog): An open-source dataset for benchmarking autonomous self-driving labs (MATRIX), along with with an open source model based upon this dataset (MATRIX-PT). We could talk about this extensively, but a fun data point is that improving reasoning in the area of materials also improved reasoning for biological systems! This is a truly unexpected result.Big shout-out to the Radical team for sharing their work!Materials discovery has been stuck on a 20–30 year timeline for generations. Joseph thinks that’s about to change, and Radical AI is putting that thesis to the test in the lab, one sample at a time.We had a great time talking with Joseph. We hope you give it a listen!Timestamps* 0:00 Introduction to the challenges of AI in material science* 0:52 Welcome and introduction to Joseph Krause and Radical AI* 1:38 Why Radical AI is different: The focus on experimental data and Self-Driving Labs (SDLs)* 6:19 The process: Candidate generation, synthesis, and characterization* 11:05 The application of exotic alloys in extreme environments (aerospace and defense)* 13:20 Barriers to entry: The slow process of qualification and manufacturing* 16:06 Supply chain constraints in material science* 19:24 Human-in-the-loop: Training the AI using scientific intuition* 20:35 The engineering challenges of automating a laboratory* 23:17 Defining the “Self-Driving Lab”: Research campaigns vs. just automation* 24:39 Mechanical challenges: Handling high-temperature samples* 27:41 Future scaling plans and the “Vertical Integration” strategy* 30:08 Validation timelines for high-tech industries (semiconductors, aerospace)* 31:47 The active learning loop and handling “negative results”* 35:32 AI exploring elemental families beyond human bias* 39:13 Throughput targets and the difference between AI and human exploration* 43:52 Why the dataset size is less critical than the quality of experimental feedback* 46:20 Addressing the lack of an “AlphaFold” for materials* 53:49 War stories from the lab: Building the infrastructure* 58:12 The shift in industry sentiment toward SDLs and tool interfaces* 1:01:14 Geopolitical considerations and the race in material science innovation* 1:06:12 Calls to action for ML and AI engineers: Rethinking the scientific stack* 1:09:53 The Matrix model and using VLM for scientific knowledge extraction* 1:13:10 Why Radical AI is open-sourcing their work This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
Summary
Reality: The Final Eval — Lukas Petersson and Axel Backlund of Andon Labs
Jun 401:15:39Summary readyThe new AIEWF website is live! Get your tickets booked ASAP as they -will- sell out. Take the AI Engineering Survey and get >$2k in credits and free AIE WF tickets!Most industry benchmarks compress intelligence and reasoning ability into scores.SWE-Bench Pro, MMLU, Humanity’s Last Exam, etc. These metrics are useful, but don’t always represent the full extent of how a model performs in the real world. Some of the most interesting evals today look less like exams and more like operating businesses in the real world. One of which is Vending Bench.In Anthropic’s Mythos Preview System Card, Andon was the only third party eval to get their own section, observing increasingly concerning aggressive behavior:You don’t know what a model is capable of doing in the real world unless you actually give it inventory, a wallet, tools, customers, competitors, humans, & some time. More often than not, it’ll surprise you how much a model is capable of and in doing so, also reveal unexpected behavior: deception, context collapse, emergent coordination, & bizarre negotiation behavior.While an inflection point in personal agents came post-OpenClaw after full file access with bypass permissions became the norm, it is yet to come for agents in the real-world. However Andon Market, an actual in person store fully run and managed by AI, is paving the way for what is possible.Full Video PodFrom Claude trying to call the FBI over a $2/day vending machine charge to AI agents forming price cartels, hiring human employees, running physical stores, and writing existential robot musicals, Andon Labs is stress-testing what happens when frontier models stop being chatbots and start acting in the real world. In this episode, Andon Labs cofounders Lukas Petersson and Axel Backlund join swyx and Vibhu to unpack the strange, funny, and genuinely concerning edge cases that emerge when agents run businesses over long horizons.We go deep on Vending-Bench, Project Vend, Vending-Bench Arena, Bengt, Butter-Bench, Luna, and Andon’s broader mission of building realistic real-world evals for autonomous AI systems. Lukas and Axel explain why dollar-denominated evals reveal things traditional benchmarks miss, how Claude ended up reporting its vending machine fees as cybercrime, why long context windows can drive agents into meltdown loops, what happens when agents compete with each other, and why the future of AI safety may depend on testing models in messy physical environments instead of clean benchmark sandboxes.We discuss:* Why Andon Labs started with dangerous capability evals and long-running agents* Vending-Bench and why running a vending machine is a deceptively hard AI benchmark* Why money-based evals avoid the saturation problem of traditional benchmarks* How Claude tried to call the FBI over a $2/day fee* Why long-horizon agents can spiral into existential and legalistic breakdowns* Project Vend: putting an AI-run vending machine inside Anthropic* Why real humans are “out of distribution” for simulated agents* Claudius, Seymour Cash, and the chaos of AI CEOs* How a human briefly became CEO of Claudius through a manipulated election* Why multi-agent systems can converge back into “helpful assistant” behavior* Bengt, Andon’s internal office agent with email, spending, terminal, phone, camera, and internet access* How Bengt traded Amazon purchases for face-recognition training data* Claude’s aggressive behavior, lies, refund avoidance, and price-cartel behavior in Arena* Why eval awareness may become the AI version of “are we living in a simulation?”* Blueprint Bench, spatial intelligence, and why models still misunderstand physical rooms* Butter-Bench and testing LLMs as robot orchestrators* Luna, the AI-run physical store with a three-year lease and human employees* The new Andon cafe in Sweden and why real-world geography matters for agent evals* Rotten tomatoes, perishable goods, and the hidden difficulty of running a physical businessLukas Petersson* LinkedIn: https://www.linkedin.com/in/lukas-petersson-181a83172/* X: https://x.com/lukaspetAxel Backlund* LinkedIn: https://www.linkedin.com/in/axelbacklund* X: https://x.com/axelbacklundAndon Labs* Website: https://andonlabs.com* Vending-Bench: https://andonlabs.com/evals/vending-bench* Andon Vending: https://andonlabs.com/vendingTimestamps00:00:00 Introduction00:01:00 Andon Labs and the Origins of Vending-Bench00:05:21 Why Money-Based Evals Matter00:09:51 Agent Harnesses and Self-Modifying Systems00:13:36 Claude Calls the FBI00:16:33 Project Vend: Claude Runs a Real Vending Machine00:21:44 Seymour Cash, AI CEOs, and Election Chaos00:27:16 Multi-Agent Coordination and Slack Observability00:30:18 When Will Agents Run Real Businesses?00:34:56 Bengt: Andon’s Internal Office Agent00:40:06 Real-World AI Safety and Long-Horizon Traces00:44:28 Lying, Refunds, and Price Cartels in Arena00:52:42 Eval Awareness and Simulation Behavior00:56:06 Blueprint Bench, Butter-Bench, and Robotics01:04:37 Luna: The AI-Run Physical Store01:09:29 The Sweden Cafe and Real-World Expansion01:13:16 What Comes Next for Andon LabsTranscriptIntroduction: Andon Labs, Long-Running Agents, and Real-World EvalsSwyx [00:00:00]: Welcome to Lukas and Axel from Andon Labs, and I’m joined by my, favorite guest host. Anything security, safety, alignments, Vibhu., welcome.Lukas [00:00:15]: Thank you for having us.Axel [00:00:16]: Thank you.Swyx [00:00:17]: Let’s match names to voices., maybe you wanna take turns introducing yourselves.Lukas [00:00:21]: I’m Lukas.Axel [00:00:22]: And I’m Axel.Swyx [00:00:24]: Let’s introduce Andon Labs a bit. How did you guys come together?, you have different backgrounds, but you’re both Swedish., was that, a big part of it?Lukas [00:00:33]: So when I went to high school, there was this really cool guy who had a superpower. He could code. So he made like the or like the app for the, for the school and stuff, and he was super cool, and I wanted to be like him, and that was that guy.Axel [00:00:47]: I don’t know about this.Swyx [00:00:49]: But you went to different universities, right?Lukas [00:00:51]: But same high school.Swyx [00:00:52]: I see.Lukas [00:00:52]: So we always said, “Oh, once we graduate university, then we should start a company,” and that’s what we did.Swyx [00:00:58]: Wow, there you go. And about a year ago, you kinda burst onto the scene with Vending Bench, but, was there a thing before that was, kind of like the inception?From Dangerous Capability Evals to Vending BenchAxel [00:01:07]: So we did work, yeah, with, Anthropic was one of our, early customers in doing, evals. So we did, dangerous capability evals., nothing we published openly. But then we started thinking about do...
Summary