← Latent Space: The AI Engineer Podcast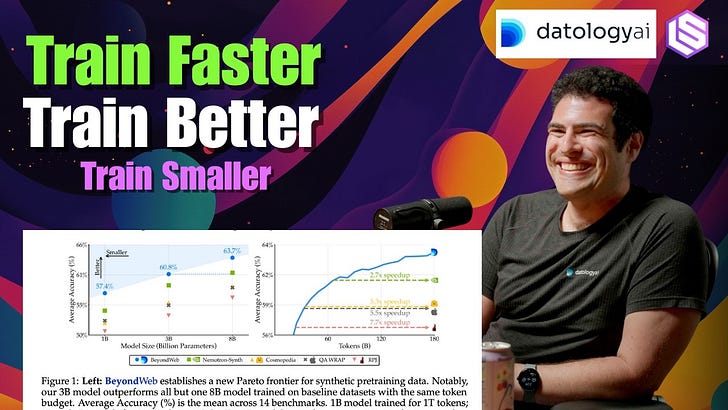
Loading summary
Transcript137 lines
- [00:00]
Ari Marcos
Foreign.
- [00:05]
Alessio
Welcome to the Litenspace podcast. This is Alessio, partner and CTO at Decibel. And I'm joined by swix, founder of Small AI.
- [00:11]
Ari Marcos
Hello.
- [00:12]
Swix
Hello. And we're so excited to be in the studio with Ari Marcos, CEO, co founder of Datology. Welcome.
- [00:17]
Ari Marcos
Thank you so much for having me, Ari.
- [00:19]
Swix
So you first came across my radar. I mean, I guess Datology is like a relatively, I guess, exciting or well hyped startup, at least with the fundraising and the high profile of the people that you hire. I reached out to book this interview after you. You worked on the rc. I don't even know how to pronounce it. Rk.
- [00:35]
Ari Marcos
Rc. Yeah, rc. It's inspired by a real transformer that was called rc.
- [00:40]
Swix
Yeah, the RC foundation models. You guys have been doing a lot of data work. How would you describe Datology today?
- [00:47]
Ari Marcos
Yeah. So our mission at daitology is to take everything around the data side of machine learning, right? So going from you have a bunch of data sitting in storage to you're going to feed it into a model via a data loader. There are a ton of choices you would make in that process, ranging from how you're going to filter the data, how you're going to sequence the data, synthetic data you're going to generate, if any, how you're going to batch the data, all of those things. And those will have a tremendous impact on the performance of the model that you train on the data. One of my favorite catchphrases is models are what they eat. If you show them great data, they're going to be really high quality. If you show them low quality data, they're going to be low quality. But this is a frontier research problem. How do you actually do this effectively? How do you do this automatically at scale? Right. It has to be automatic to be able to process trillions of tokens, billions of images, things like that. And that's our mission at Datology is to take that whole process, make it really easy so that anybody can get access to state of the art data curation without needing to be an expert themselves. And in doing so, help the folks we work with to train models much faster to much better performance and to also help them train much smaller models to the same or better performance, which I actually think is some of the most exciting stuff going forward. But fundamentally, that's what we do at Datology is help people curate their data so they can train models faster, better, smaller.
- [02:00]
Swix
So the key words for that, data curation as a service, data efficiency, all those terms in the pre chat before we started recording, you mentioned that there's a cool story around how you got into data in the first place, right? You were at gdm, you were at Meta as a research scientist. Describe how that became an interest.
- [02:16]
Ari Marcos
My PhD is actually in neuroscience, so I come much more from an empirical science sort of background. I actually spent time trying to teach mice how to count and then analyze the activity of thousands of neurons in the brain. While mice did count and try to understand how did that actually happen, what were the neural dynamics enabled? That, and that's actually initially how I got into machine learning, was as a means to analyze my neural data sets. I also started my PhD 2011. So Alex net came right after that. Atari, DQN right after that. Lots of evidence that AI was going to be very, very exciting, which led to me transitioning. But as a result, because I had this kind of somewhat different background of being trained as an empirical scientist rather than as a computer scientist, my real first mission when I joined AI was to try to build more of a science of deep learning. Something that I think is still true today in many cases is that deep learning is an empirical sc. But most people that have computer science backgrounds were trained more in the context of a branch of theory. Everything was very provable. That was the initial pushback to deep learning, actually, was that you couldn't prove anything in it. But deep learning is at its core an empirical science. Right? We have to run large experiments, we understand the rules for how we design these systems, but the properties that come out of them when we actually train them on a ton of data are emergent and unexpected. So I always really wanted to write these papers where they had two halves where the first half of the paper was trying to understand why is this representation desirable or undesirable. Why does the model good or bad, and then understand that, and then use that understanding to then improve the model. And that was always my goal. That was kind of the perfect paper. Rather than just throwing spaghetti against the wall and seeing what stuck, we were able to really understand why something didn't work and then use that understanding to improve it. Unfortunately, it turns out that it's not so difficult to do the first half of that, try to understand the system, but really, really difficult to actually use that understanding to improve the system. A lot of times what would happen is you go to optimize for this variable, you find here's this property of representations that makes models good. You go and you optimize for that. And then it turns out that wasn't a causal variable that was a correlate and it doesn't actually work. So I maybe wrote 30 papers where we did that first half and maybe only three or four where we did that second half. And that was always kind of frustrating and dissatisfying to me. And then around 2020 I had several papers that all kind of slapped me in the face at the same time with the same insight, which is that all that really matters is the data. And I had come into all three of these papers very much focused on inductive biases. How do we put inductive biases into models? Either through changing the objective or through changing the architecture, which is where most of the field was and still where you see a lot of the papers at the big conferences are about architectures and various tweaks to architectures. But I had these multiple papers, all of which made this clear takeaway that the data is the only thing that matters. I'll give you one example. There's a paper we had called Convict where the idea was to take a vision transformer and initialize it as if it was a convolutional neural network. And that way you could actually start with this inductive bias of convolution, but the model could choose to unlearn it if it wanted to. So the idea was it was a soft inductive bias, not a hard inductive bias. Convnets have a hard inductive bias. You can't not be convolutional in a convnet. But in this case you initialize the transformer that way and then if it wants, the model could learn not to be that. And the idea here was that this would be really helpful for models to give them this inductive bias, but then they could learn not to use it if they didn't want to.
- [05:31]
Swix
Just to follow up, there's a one to one mapping of a convnet to a transformer and you can map it directly onto the weights.
- [05:36]
Ari Marcos
Exactly. You can map it exactly correctly. It turns out if you make it just say you have a 3x3 kernel, you can have nine heads, each head corresponds to a different part of that kernel. And then you can initialize it so it is exactly.
- [05:48]
Swix
So it's like a very coarse thing that can then be refined as with training.
- [05:51]
Ari Marcos
Exactly. And then it can choose to change its weight so that it can undo the weight tying that you impose on it this way. We actually had a follow up paper which showed you could take a train network and actually instantiate a Train CNN as a vit as well. So there's a way to do this, turns out, in the small data regime, and when I say small data here, I mean say less than 500,000 data points. And this was in the context of image self supervised learning. So in that small data regime, this is super helpful. And where this paper's actually been cited is a whole bunch of niche scientific problems where there's very little data, for example, volcano prediction, where you have like 1500 data points or things like that. But the advantage of using this soft inductive bias decays as the data size increases and eventually actually becomes harmful. So if you see enough data and the threshold at which this changes is around like a million data points. So it's not massive by any stretch by our current model. So basically, once you get past a million data points, that soft inductive bias no longer helps you and it actually now is mildly harmful. So I had this paper and a couple other papers that all kind of made this same point that basically when you get to enough scale, inductive biases matter not at all. All that really matters is the learned posterior from the data distribution. And that's really what defines everything. And then of course, the rise of the transformer really showed that actually starting with models that fewer inductive biases built into their architecture is the right thing. So we had this combination of factors which ultimately actually was very confronting for me because I had spent the last six years of my career working on inductive biases, and now I'm faced with several different papers, all of which show me that, hey, what you've been working on isn't actually really that important.
- [07:32]
Swix
Bitter lesson pulled.
- [07:33]
Ari Marcos
Bitter lesson indeed. So the bitter lesson was indeed very bitter for me. And that was really my inculcation in it, I suppose, where at the end I kind of thought to myself, okay, clearly the bitter lesson is true here. What should I do in this new world? And it became clear to me that there are really two options that made a ton of sense. Either go work on making GPUs, go burr. And I'm not a hardware engineer. I don't know how to make GPUs go faster or work on data. And for a whole bunch of reasons, data has been dramatically underinvested in relative to its impact. Something I've said before, and I'll say again, is that data is the most underinvested in area of research relative to its impact. And I don't think it's even close. And there are a Whole bunch of reasons for this which we can go into, some of which have to do with the culture of machine learning, some of which had to do with the incentives that have been set up. But data has systematically, generally not been considered. Even if you go and you look at the scaling laws work from Kaplan and Chinchilla and all these other things, they all assume IID data, which is insane. We know that all data are not created equal. That garbage in, garbage out is the oldest adage in computer science. And yet all these scaling laws assume that all data is created equal. That makes no sense whatsoever. That's what led me to start working on this problem. And it turns out that there's a really cool thing about data research, in addition to it being something that's impactful relative to the investment, which makes it a great research area and makes it an even better company. What I'd said previously was that with representations you have this disconnect where there's questions which are kind of scientifically interesting about understanding why a representation is good, and then the questions that are practically relevant, how do I use this to improve it? And I think what was so frustrating to me early in my career was that those were different questions. A lot of the time, the questions that I wanted to ask, which were curiosity driven and really interesting to me as a scientist, ended up often not being the questions that were practically relevant downstream. But it turns out with data, this is no longer true. With data, if you can understand what makes a given data point useful or what makes a given data point not informative, you can almost always use that insight to make a data set better and therefore make a model better. So what this means is that the set of questions which are scientifically interesting and the set of questions which are practically relevant in data research are largely the same questions. And that's really rare to find in research, period. And what this means is that we can ask the questions which, as scientists, are extremely motivating to us, but then have very high confidence that the answers to those questions are going to help us to build models that train much faster, that train to much better performance, and that can train with far fewer parameters. So that's a little bit of a high level of kind of how I got into the data problem. And I think the pain that I had to go through to get there in the first place.
- [10:15]
Alessio
You mentioned something about the incentives in the data not being aligned. Can you unpack that? Because I think from the outside you have companies like Skale that obviously have become super successful, so people are investing a good amount of money. But what you're basically saying Nvidia is like 4 trillion and Skale is not 4 trillion. So why do you think there's that inefficiency?
- [10:34]
Ari Marcos
Okay, so first off, we have to divide the research community from the industrial community because I think they're very different. And I think in general, data work has been far more valued in industry consistently than it had been in the research community. First and foremost, part of this is that data work has just often been considered second class citizen sort of work. It's the grunt work, it's the plumbing, it's the stuff that you don't want to work with as a super hoity toity scientist. There are even some tweets recently going around, people saying data cleaning is boring, it's low value work. Whereas I think what you'd find is that if you talk to the most talented AI researchers and you ask them what's the secret to your success, they'll largely tell you that they look at the data. Ultimately, these models are a reflection of the data that you showed. And yeah, it can be tedious, it can be challenging, but it is so critical to get this right. So I think first off, there is this general perception that this is lower quality work, or not quality, but lower prestige work. And that's been there for a long time. I think part of this had to do with the way that research incentives were set up. The data set was viewed as the given. So if you think about research circa, say 2018, given ImageNet maximized performance on the VAL set or on the test set, right? But the data set ImageNet was given as something you don't change. Even Kaggle had this framework, right? Given the data set. Go and make this better. People might try things like bootstrapping or stuff like that, but generally the assumption was you're going to improve the model through better modeling, not through improving the data set. And part of this also was just in the supervised learning era, this made sense, right? We generally weren't compute limited, we were generally very data limited. Right? Data was very scarce. Like if you want to assemble Imagenet, you have to go to MTurk and get a whole bunch of people to label the data set. And then there's generally some quality floor, right? Because a human has looked at every data point in this data set. Even if there's still a lot of errors there, at least it's not going to be as bad as just just the Internet scraped. But then in 2019, the field underwent this pretty Massive change. We figured out how to train without labels. And one of my more controversial viewpoints, I think is that I think the transformer is a great advance, to be sure, but I think it's one of a very large set of equivalently good architectures that we could have found. And there are many, many ways we could get to the same performance without the transformer. But I do not think there's any way we could get to where we are today without self supervised learning and the ability to train on unlabele. That was the real advance to my mind, that enabled us to get these incredible increases in capabilities, which is like the mask objective. It's not just masking objectives. I think mask language modeling objective is one. But even next token prediction, right? But generally this notion that hey, instead of having to get an external label from a human, we can ask the model to predict one aspect of a data point from other parts of that data. And that is really powerful because think about it, right? That meant that we went from imagenet a million data points to literally trillions of tokens, a million fold increase in data quantity in a matter of like several years. That's completely unheard of. And that also changed everything because now we went from data being scarce and having a high quality floor to now all of a sudden data is absolutely massive. All of our models are basically always underfitting the data, whereas previously we would do 160 epochs on an image data set, right, where they would all be overfitting the data generally. So now we move to this underfitting the data regime. There's no more quality floor. And now we have all of these problems with redundancy, with low quality, with low information gain, all various things that come with these massive unlabeled data sets. So I think the problem also changed pretty dramatically from the 2010s to the 2020s. And I think that's what makes it so exciting as a scientific question is that this didn't really make sense to study prior to 2020, but now this makes tremendous sense and is I think absolutely critical for us to solve in order for us to enable these models to continue to improve and also to enable the cost effectiveness of these models so that they don't just stay as something that's only possible to achieve if you have hundreds and hundreds of millions of dollars. Making the data better can be a massive compute multiplier. It can change the performance per dollar by orders of magnitude. And in many ways that's our whole goal is how do we make that easy and effective for everyone.
- [14:49]
Swix
Totally.
- [14:49]
Alessio
And you were a meta from 2018 to September 23rd, which is both during Llama 1 and Llama 2. At what point inside of Meta, maybe some of these learnings become apparent, like, okay, we should start to spend resources working on this. You mentioned 2020, so I'm wondering if that was like, I think Llama One.
- [15:08]
Swix
Was already a big breakthrough.
- [15:10]
Ari Marcos
Yeah, Llama One definitely put more effort into data filtering, I think, than many others and definitely started to change this. But even then I would say that actually even when I left meta, this was still an area of kind of the idea of actually curating the data to figure out what's the high quality, high value data, I think still was fairly underappreciated. And if you talk to a lot of the folks on the data teams within the big Frontier labs, what you'll find is that they've actually invested really heavily in crawling. Oftentimes they've really worked on getting better crawlers and trying to clean up the source of the data that's coming in, which makes sense. But ultimately I think what you really need to do is you need to take this perspective of given everything that the model has seen so far, and given a potential candidate set of data, what data point is going to teach the model the most the next time it sees a data point? And that's a pretty different framing for how to think about this problem. And I think there's certainly been some great work done, although it's all secretive within, I think the bigger labs. But that's a really hard problem. That's a frontier research problem. And I don't think we still know how to solve that. I think data curation also is a hard problem to solve, quote unquote, because it's not one where there's a single silver bullet. There's not just do this one trick and all of a sudden things work. It's rather, Here are these 50 different things that you can do, each of which provides a pretty modest gain on its own. But then if you can figure out how to make them combine, you then get a really big gain. But you have to figure out first off, what are all of these different things you want to do? And then two, how do you make them play nice with each other? Because by default they don't play nice with each other.
- [16:36]
Swix
Yeah, I'll make a quick observation on you mentioned self supervised learning. I definitely agree that just getting rid of labels altogether is great. Or forming your own labels.
- [16:45]
Ari Marcos
Right.
- [16:46]
Swix
And I have a general observation That I think that extends to things that are not just learning. So self supervised, I don't know, optimization, Self supervised neural architecture search, Self supervised curation. If you can just automate everything. I think that's the lesson, really. Just get the machines to do it. Because we are the rate limiters if we must label everything.
- [17:05]
Ari Marcos
Yeah, I think that's very true. It's actually something I think about a lot is are we actually falling prey to the bitter lesson again here by trying to have human guided methods of data curation? Probably the best open effort on data curation is DCLM Data Comp lm. It was led by Ludwig Schmidt, a professor at Stanford and about 30 students across many different institutions. Really wonderful effort to kind of curate common crawl style data sets.
- [17:33]
Swix
Yeah, we've actually covered data Comp and DCLM on the podcast.
- [17:36]
Ari Marcos
Awesome. Great. But DCLM had a really cool study at the end of the paper that I don't think gets nearly enough attention as it should. Okay, so they had these 30 grad students spend two years basically trying to design what are the optimal filtering criteria for these models. And they built a system that's pretty good at this. So then they asked all those students predict what that system is going to do. So given a data point, is the system going to say keep the data point or is it going to say reject the data point? These are nominally the best experts you could ever hire to do this. These are students who have just spent all of their time looking at NLP data for two years. They could not predict what the DCLM classifiers would say above chance. So this comes up a lot of times where people often ask me, how can you possibly do this without a human in the loop? It just seems impossible. You need to have a human to actually rate these data. But I think that what the takeaway from that study is, and I think there's a number of other piece of evidence that also suggests this, is that obviously we have to be automated because humans just can't scale to billions of data points, trillions of tokens. It's not possible. But even if we could, we actually wouldn't want that humans are not good at this task. And to give an intuition as to why humans aren't good at this task, I think the easiest way to think about this is that the value of a data point is not just a function of that data point itself. It's rather a function of how that data point relates to every other data point in the training set. Right. So if I have 10,000 copies of slightly variable summaries of Hamlet. I don't need all of those. But if I were to look at any one of those individual summaries, I might say, hey, this is really high quality. This is a really accurate. It tracks all the characters, it's well written, it's clear. But I don't need 10,000 of those. And that's just a task that a human would never be able to do, because a human can't keep the whole data set in their head, obviously. So even if you could have this scale with humans, you wouldn't want to.
- [19:32]
Alessio
But. So what's the right number between 1 and 10,000?
- [19:35]
Ari Marcos
The unsatisfying answer is it depends. But it's also the right answer. So it depends on how complex the concept is. So redundancy is really useful. Right. And removing all redundancy is a bad thing. If I remove all redundancy, then I'd only be able to understand, say, a golden retriever in the one situation that I've ever seen it in before. I wouldn't be able to generalize, and that would be bad. Right. So some redundancy is good, but I think we all have the intuitive understanding that infinite redundancy is not good, it's bad. So where is this line for different concepts? Well, one example I like to give for this is elephants versus dogs. So elephants are pretty stereotyped. There are two kinds of elephants, elephants in the world. There are Asian elephants and African elephants. They're all gray. They all have floppy ears, they all have a trunk and some tusks. They all have wrinkly skin. African elephants are bigger than Asian elephants, but largely, they're all pretty similar. There's not too much variability. So I don't need that much data or that much redundancy to understand the concept of elephants fully and completely. But dogs, on the other hand, are totally different. Dogs are super variable. There are hundreds of breeds, not to mention all the mixes of different dog breeds, their different shapes, sizes, textures, colors, all of these different things. The amount of data that I need in order to properly understand dogs is going to be a lot higher than the amount of data I need to understand elephants. So this comes to some of the challenge when you're actually trying to do this sort of creation, at least on the filtering side, is you have to. First off, you don't get a data set where you're given, hey, these are a bunch of dogs, these are a bunch of elephants. Instead, you just get, here's a bunch of data, right? So first off, you have to unlock. You have to in an unsupervised way discover what these concepts are, use something about that concept in order to make some inference about how complicated it is or how complex it is and therefore how much data you need to understand it. Figure out, okay, this is a really complicated concept. I probably should keep a lot of redundancy. This is a really simple concept, I don't need that much redundancy. And then make that appropriate choice of what do you want to remove. So this is, I think where a lot of the challenge comes from. But these are the sorts of factors that you have to keep in mind when you're trying to design these systems.
- [21:34]
Alessio
How do you draw the line of a concept though? Right? Because then it's like, well, the elephant and the dog, but what about mammals? And then what about, you know what I mean? It's like, how should people think about it? Maybe Is that why you need the turology? Because it's hard to talk?
- [21:47]
Ari Marcos
Yeah, no, I think that's right to some extent. I mean, look, it's an empirical question like all things are right is that with every data set that you can choose different level of fine grained. Ultimately it's a hyperparameter, it's a knob that you can tune right for, for how aggressive are you going to be with respect to creating new concepts versus keeping concepts together? And it's one of these things where I think to your point, it's why we've run hundreds and hundreds of thousands of experiments to try to figure this out. I think this is something where it requires just a lot of experimentation to understand how to do this. I think one of the challenges we have is not only do we have to make this so that this works on one data set, but we also have to build a system that can automatically adapt, adapt to any arbitrary data distribution and be able to make the appropriate inferences in zero shot on a new data distribution. So we kind of have these two sets of questions. First off is like, how do we push the frontier of data curation forward? And then second of all, how do we do out of distribution generalization where we say, hey, we have this great data creation approach. How do we make sure that this generalizes to a novel data distribution?
- [22:46]
Swix
I don't know if this is a good time, but I was going to ask for a brief history of data sets. It might be too much. I don't know. I'll just list off because we've done the datasets 101 episode. I think that was One of our earliest episodes by far, because we want people to know the datasets. And I think everyone starts with Common Crawl. I think every lab has their own web scrape. Would you say that's true or do they start from Common Crawl at this point?
- [23:08]
Ari Marcos
Yeah, like I said, this is where most of the labs, I think, have actually invested most of their time and effort is in building better versions of Common Crawl for themselves.
- [23:16]
Swix
Yeah, I would just name check some of these. If you have commentary, just chime in. GitHub source of code, maybe Stack overflow, even though that's cut off these days. I don't know. Do people get code from anywhere else?
- [23:27]
Ari Marcos
I mean, I think there are obviously places where you buy code data, but for public code, I think those are the most common. I think some interesting things about those that I just personally find surprising. Stars are not a good predictor of whether data is useful for models or not. I think that's the most popular repos are not necessarily higher quality, at least with respect to do they improve a model's coding capabilities? I haven't done it, but the Starcoder paper has done it. And there have been a couple other papers that have all shown that. Something that I just consistently found to be a little bit surprising. There's a lot of things that are kind of counterintuitive about data curation.
- [23:59]
Swix
This shows that I haven't read the paper, but did they find anything good that was a sign of a good code base?
- [24:04]
Ari Marcos
There wasn't anything that was super predictive. Oh, man. Honestly, in some ways, some of them were length. Some of these simple heuristics actually ended up being better. But nothing was super discriminative there, which is kind of interesting.
- [24:16]
Swix
Okay, cool. I'm going to keep going. Arxive, which is GitHub for papers, books, books one, books two, and obviously books three. Controversial. I think anthropic's getting sued over books three.
- [24:27]
Ari Marcos
Yeah, I think a bunch of people are getting sued. Meta has also been getting sued Sean.
- [24:29]
Swix
Preserver over Books three in some sense. Can we just look past it? I don't know. It's like books are transformative use. I don't know if you have a view on this.
- [24:38]
Ari Marcos
Well, I think the recent ruling was interesting, although it was an appellate court ruling, so presumably it's going to go to a higher court afterwards. But what they ruled was that it's fair use so long as you purchase the book. So you can't download books 3 and then use it because that's piracy and that you've stolen the books in the first place. But if you bought a copy of all of those books, then you can train it on and then it just counts as fair use. Which I think is an interesting and to me it feels pretty reasonable line there. One fun thing about books 3 is that it also has a lot of not safe for work stuff in Books three, which is kind of interesting. If you actually go and look through it.
- [25:15]
Alessio
There should be a stripe one click checkout with bookstore. Just buy bookstore and then get a warehouse and then get the most in there. I wonder what the cost would be. I'm sure somebody ran the numbers. I'll look it up.
- [25:29]
Swix
I don't know if you can comment on this at all, but in the Meta lawsuit, I remember there was an email thread with some of the research scientists inside of Meta talking about Books three and Zuck was like, just do it. This is public, right?
- [25:40]
Ari Marcos
Yeah, that was, I think, public in part of the lawsuits.
- [25:42]
Swix
Yeah. Any reflections, comments?
- [25:44]
Ari Marcos
All I can say is that when I was at Meta, certainly legal stuff around data sets was very challenging and becoming increasingly challenging. And there are a number of situations where the only person that could approve things was Zuck because of the scale of the risk, I think. And it definitely made publishing at Meta near the end more challenging around just what we could do with any data set. Because I mean, realistically, companies like Meta and OpenAI Anthropic are big targets for these lawsuits.
- [26:11]
Swix
Yeah. So my conspiracy theory for what happened to llama4 is the lawyers got to it.
- [26:15]
Ari Marcos
The lawyers got their data sets and they had to change what they used.
- [26:19]
Swix
Yeah, they were just like hand tied behind their back when other labs were not. Because Matt Miller had an active lawsuit.
- [26:24]
Ari Marcos
I think that's possible. I think probably more of it just has to do with the challenges of just continuing to scale and having that be the goal. This is actually a lot of the reason why I got into data and started Datology was that the scaling laws always were terrible. What the scaling laws paper showed was that there was a predictable relationship between Kaplan one. Yeah, the Kaplan one. There's a predictable relationship between performance computer data. Right. That's really useful. But it was a bad, predictable relationship. Power loss scaling is terrible. It means that Every time you 10x your data, you get a diminishing marginal return on performance. This is why you had these prognostications, oh, GPT N is going to cost a trillion dollars to train. It's because you take that scaling curve and you just naively extrapolate it out. I Think that's what we've seen to some extent with the failure of the mega models with 4.5 and llama 4, now others. I think that there is a challenge of just continuing to do that naively and you have to figure out how to break it. I think there are a number of theories of ways how to break it, and I don't think they're mutually exclusive. My bet is that data quality is a massive way to do this. And in many ways. Actually the paper that was the foundational paper for datology, it's called Beyond Neural Scaling Laws, and was fortunate to get a best paper at NeurIPS. And what that paper showed was that if you use your data correctly, you can actually bend the scaling laws themselves. And an interesting kind of technical part of this is that I mentioned what we really care about about is how much new information do you learn from the next data point. So technically that's the marginal information gain per data point. Perplexity is another variant of it. There's a duality between them. It turns out that we were able to prove in perceptrons at least, because that's generally what all you can ever prove things in. So in small scale. And this work was led by Ben Sorcher, who was a really fantastic grad student I worked with on this paper. And what he showed was that there's a direct duality between power loss scaling and the fact that you also see that the marginal information gain per data point point also decays as a power law. And that's why you get power law scaling, because every successive data point is teaching you less and less and less and it follows a power law. So then you get performance decaying as a power law as well. So if instead you can keep that so it's flat, then you bend the scaling law and now all of a sudden you learn dramatically faster because the amount of information you're learning is not decaying with data set size. Now that was all in theory, what you could accomplish. And we proposed a couple metrics that got us one step there. But in many ways I would actually say that the whole point of datology is how do we realize the potential that was shown in that paper? How do we actually make that a reality? And I think fundamentally, if we want to get scaling to work well, fundamentally we need to do a better job here.
- [28:58]
Alessio
Are you measuring the quality of these open data sets over time? Are the most recent open data sets better than the older ones at a good rate or just marginal?
- [29:07]
Ari Marcos
They do get better. But I think they're not relative to the headroom in potential. I would say Nematron is actually pretty similar in quality to dclm. It came out about six months later. It has more unique tokens. They made a really big deal about it having more unique tokens, but on average the quality is pretty straightforward. When we think about what we are able to accomplish at daitology, we usually think about along these three axes. I mentioned train faster, train better, train smaller. So typically, specifically, basically that's first question, train faster. Given a certain baseline data set, how much faster can we achieve the same performance and how many fewer tokens? So we're able to now get to the same performance as DCLM about 12x faster. So in fewer than 10% of the tokens we can match what you get from training to convergence.
- [29:53]
Swix
And when you say performance, you mean like GPQA or you mean logs?
- [29:57]
Ari Marcos
Yeah. So we typically take the accuracy across, across 15 standard benchmark tasks that are relevant for a given model size. So your MMLUs, your ARCs, your races, et cetera.
- [30:07]
Swix
The problem with those is are you training to the test? Right.
- [30:11]
Ari Marcos
I'm sure you know this and that's something that we're super careful about because it's really easy to overfit to these benchmarks of course and then end up with models that are really brittle. And I think this is something that we've seen especially with synthetic data. And synthetic data is a big part of what we do. At datology we found that it can drive pretty dramatic gains chains if you do it correctly. There are lots of ways to do synthetic data incorrectly. We've seen a number of models that are trained on a lot of synthetic data and end up doing really well on benchmarks, but then kind of don't pass vibe checks and people don't really use. So we do a lot to try to prevent this. First and foremost we keep a held out set of test sets that we only look at very occasionally and we also don't evaluate on a whole bunch of other evals that we then have models that end up getting eval'd on later to try to really ensure this. But yeah, this is fundamentally how we measure. We look at an average of benchmarks just trying to kind of think what's, what's fair and reasonable with respect to what we can do. So that's like the first thing we typically look at. Then we look at train better. Of course, under the same compute budget, how much better can you do? With a given data set we're able to beat the best open data sets by anywhere from four to five points, depending on the specific data set and eval. Some of the evals actually are much bigger than 4 to 5 points. 4 to 5 points on average, and those are absolute points. We generally find that in order to get that same performance from training longer on the baseline data sets, you'd have to train on those baseline data sets sets at least five to 10 times longer to try to match that performance. Because every successive point of accuracy, of course, gets harder and harder to achieve. And then finally train smaller. Basically say, okay, given holding performance constant, what's the smallest parameter count model that we can get to outperform? We can already get models that have fewer than half the parameters and also train faster and also outperform the larger models trained on the uncarriated or alternatively curated data sets by a large margin. So this is a big roundabout way of getting to this answer. Of the open data sets, I think kept up with this improvement with a fairly small team. We're now a team of about 30. Most of the results that I've discussed were achieved with a team of under 20. Because we've grown quite a bit in the last couple months and with not that much compute by common standards more than academics, but certainly nowhere close to the frontier labs, we've been able to achieve, I think pretty dramatic results. I think the reason for this is because there's so much headroom here. We've already been able to get 10x gains. I think there's at least another 100x behind this that are still to be done. There's so much stuff that we're just not even doing right now that I know makes sense to do, let alone all the things that we are doing that I know we can be doing better, that we're still very suboptimal with respect to how we're doing this. I know that the way we do our synthetic data right now could be much better, that the way we do our filtering could be much better. The way we do our model based filtering, our embedding based filtering, all these different aspects could be much stronger. So I think there's just so much headroom here. I think the challenge is that there's not a huge incentive to do this in the open dataset community. I mean, the labs which have the biggest incentives obviously have incentives not to share anything with respect to that. So you're left to kind of, you know, the Allen Institute, things like dclm, hugging face, et cetera, to make progress there. But I do think that this is Such this is a hard enough problem that it really demands a whole company that is really focused on this. I think what you see in all the Frontier Labs is that they have data teams and if you talk to the folks that work on those data teams, what you'll kind of systematically hear is that typically they're under resources source relative to the gains that they're delivering, that they're always having to fight for attention. And this is just like a fundamental thing that I saw at Meta, I saw at DeepMind and I've heard at all these other places. It was a big part of why I decided to start Datology instead of doing this within Meta. I had the opportunity to start a data team there and that was to try to centralize this. But fundamentally I think that this is such an important problem that it's a problem that needs to be the end itself, not just the means to the end, which I think is what you see in many of these big groups. You need to have a large team of really talented people who are really passionate about looking at the data, and there aren't that many people who are that passionate about it to just focus on how do we build the best possible data sets for model training. I think it's hard to do this as a data team. I think there's a real benefit of being a data company and that's a lot of why I started Datology.
- [34:20]
Alessio
How do you think the almost economics of the open source data sets world evolve? Because you basically have these open source data sets that are good, but maybe they're not quite as good to make production data systems and then you have companies like yourselves that are sitting on top of it. Do you think at some point there's going to be some sort of rupture between like, hey, why are you just taking my open source data set and making it better in private for people without contributing back? And do you guys have plans to then open source other sets? I think there's like kind of this open question of are these things actually useful in the open then, or should you just do it in private?
- [34:56]
Ari Marcos
Yeah, it's a great question and one that we've thought a lot about. I mean, so first off, one thing to note is that while we do work with folks who are just training on open models in general, we really built our product and designed it to be able to work with companies that are training on a combination of open source and proprietary data. And that proprietary data could just be data they've been collecting as a matter of business for the last decade, or that could be data that they've sourced from a data annotator or another data provider. And some folks we work with have all three. Right? You're going to use open data, they're going to use data that they've acquired and then they're going to use data that's part of their business to begin with. And that's, I think, a lot of where our focus goes. Although of course we are excited about working with lots of folks who are training on more open data sets. So I published for a decade, more than that even this was very near and dear to my heart and it's something that we thought a lot about at Datology. I think one of the challenges of building a startup today, especially a startup for which science is a critical component, which as I mentioned is one of the things that really attracted me to starting daitology, is this tension. Fundamentally we have to build a business. In order to do that, we have to have a moat. And you can think about kind of three places, I think, where our moat could come from. One is from science know how, one is from engineering infrastructure and the challenge of just implementing this yourself. And then finally there's a brand moat that you can eventually reach. We're very far from a brand moat at this point in our journey. Eventually I would love to have a brand moat where whenever anyone thinks data and AI they think datology and oh, that's right, should go first. I hope that we get to that point. But in the meantime we have to rely on the other two moats on the science know how and the engineering infrastructure. I think on the open data side, what we've seen is that the engineering infrastructure definitely can be a moat, but unfortunately I think that science know how moat is actually pretty important and a lot of the evidence that we've seen so far has suggested that that is something that's meaningful. As an example, you know, many of the customers we talk to that one of the first things they'll ask is, hey, compare to the best open source data. So if we were giving away everything we needed to in order to build that best open source data set, some folks would just go there. So I think that's been where our challenge has been. Now what we've tried to do, and I think we've done a good job of, and I'm generally happy with the balance we've struck, is try to, in the blog posts that we put out, give a lot of intuition as to kind of what we're doing and how it works. Without necessarily getting to that point of reproducibility. That's, I think, much more open then you see most of the big labs be. If you look at the data section of the Gemini Tech report, it basically says data quality was the single most important thing for making great models. One paragraph, we used algorithms and heuristics. Great. I think some people were even pointing out recently there's been a lot more attention on rephrasing as a method for using synthetic data.
- [37:44]
Swix
Was it the Apple payment?
- [37:46]
Ari Marcos
The Apple paper? The Kimi paper has mentioned this. A bunch of others and some folks recently pointed out that, hey, in our blog post from November, we were talking a lot about that. That's something that we do a lot of pratyush maining. The guy who first came up with rephrasing was one of our first employees. So we've improved on that pretty dramatically and taking it to new places. But that's something that I think that there would have been an incentive to just not even talk about that at all.
- [38:08]
Alessio
Sorry, just on that, do you feel like this is a great example of you were talking about about it in the data and then the Kimi paper comes out with a model and then people are like, oh, the rephrasing is important. But you're like, hey, I was telling you that before, but I just didn't have a model to show you that it was important. Do you think that still, even in open science, like a limiter for people, that if you don't have a model, people don't care? Same with Deep Seq. A lot of the things in the paper were kind of known, but then once you have them applied, people care.
- [38:34]
Ari Marcos
I think that's certainly something that happens and I think speaks to the same sort of cultural incentives that we talked about earlier, where I think that people tend to think about this very much in ultimately it being a means to an end. And I understand why that is. Of course, ultimately when we sell better data, ultimately we're selling a better model. At the end of it, we're a more cost effective model. But I think that the fact that people don't care about it as much unless they're smacked in the face with it, I think is both a tragedy and an opportunity. And I would love it if it weren't that case. But given that it is, that's I think the opportunity we see at datology to really make an impact here.
- [39:13]
Swix
This might be a little bit of a tangent, but you mentioned synthetic data, you mentioned rephrasing, so I figured now is a Good time to go into it. I figured that most of the work of datology is filtering, but I see synthetic data as something slightly different. It is in a general domain of improved data quality, but it's different than filtering.
- [39:30]
Ari Marcos
Yeah.
- [39:31]
Swix
Am I right to equate synthetic data with rephrasing or are there other parts to synthetic data in your mind?
- [39:36]
Ari Marcos
Yes, I think there are different parts of synthetic data. There are two parts. But let me first actually just comment on the filtering versus things. I used to actually use the word data filtering or data pruning and actually that paper I mentioned that was at Neurips, that one actually has data pruning in the title and that's how you beat scaling laws through data pruning. When I started datology, I really changed the language to be data curation over data pruning or data filtering. And that's because curation is a lot more than just filtering. Filtering and saying, hey, this is a bad data point we want to get rid of it is absolutely an important part of what we do. But it's also about rebalancing data sets up, sampling certain data distributionally and down sampling others. It might not mean filtering, it might just be changing the weighting with which you take it. The order in which you present data can be really impactful curricula and we now have seen this with discrete curricula for multi phase training and things like that. That's not filtering. The way you batch the data can be an important factor. Synthetic data can be an important factor. The way you mix sources, all of these sorts of things beyond just filtering. So filtering is a very important part of what we do and it will always be something that we care a lot about about, but it's much more than that. Okay, so now to the question about synthetic data. I think at a high level there are two approaches to synthetic data and we have focused more on one of them, the rephrasing one, than the other. Although I think there is opportunity in the other one. So the first approach is create new data where the knowledge that's in that data is largely coming from the model that's generating that synthetic data.
- [41:03]
Swix
Oh, that's distillation then.
- [41:05]
Ari Marcos
It's a version of distillation. And I think that this version of synthetic data could be construed as distillation in disguise. And I think it is a very clear version of this. And when you think about the criticisms and synthetic data around model collapse and stuff like that, I think they largely apply to this version of you have a net new Data creation that's coming out of these models. So that's like top one.
- [41:24]
Swix
I'll slip one in there. There's also model steganography where you can sort of hide preferences in a model and distill it down.
- [41:30]
Ari Marcos
Absolutely. And now we've seen the recent owl stuff around that.
- [41:33]
Swix
If people search anthropic owls, you'll see it.
- [41:36]
Ari Marcos
Yeah, exactly. The other way is this rephrasing, rewriting approach. So this, this is the information that's in the data is actually coming from the data that you're conditioning the rephrasing on in the first place. And all the model's doing is it's reformatting the data or presenting it in a new way that maybe is easier for a model to learn.
- [41:56]
Swix
Yeah, cleaning. Right.
- [41:57]
Ari Marcos
It's cleaning it in some way. It could be cleaning it, it could be making it, you know, the information more accessible. It could be putting that information in a format that is more representative of what the model's going to be faced with downstream. So I do think that like, one thing that definitely happens with synthetic data is we are bringing more post training, like down into pre training.
- [42:15]
Swix
Sounds like sft.
- [42:16]
Ari Marcos
And in general, like, one of my beliefs is that most of what we do in post training is better done in pre and mid training and earlier on in training in general, it's just.
- [42:25]
Swix
The scale, you know, you don't have that scale until now.
- [42:28]
Ari Marcos
It's just that. Yeah, exactly. I think if you assume this paradigm where, you know, pre training is incredibly expensive and something that you can only do very, very rarely, and then post training is cheap, then it's makes sense. But as soon as you break that assumption, and I think deep seek showed that already you can get a frontier model for a marginal cost of a couple million dollars. That's gone down since then because we've gotten better at it and compute has come down in price since then. I believe that getting to a frontier model should cost a million dollars or less for most organizations, at least in a specialized domain. And when you think about what enterprises need, that's generally what they need. They don't need a model that can do everything. They need a model that can do a constrained set of tasks to very high accuracy for as low an inference cost as possible. And I think that that will be under a million dollars very, very soon. And that changes a lot of these dynamics. But going back to the synthetic data question of these two different types, so I think there's one towards this net new creation, I think that's where you have a lot of risk. That's where you get the model collapse concerns. Where I train a generative model on a given data distribution. It overfits the modes and it underfits the tails. So then if I have it generate a bunch of data, it's going to be more mode and and less tail. And then I do that a bunch of times and eventually I get a spike, I get a delta function.
- [43:42]
Swix
Only mode.
- [43:43]
Ari Marcos
Only mode, Exactly. That makes sense why that happens. I will note that if you filter the data after each point, that's now information injection and that can break all of this and I think can prevent.
- [43:54]
Swix
Model collapse, which a little bit is what RL is.
- [43:56]
Ari Marcos
Which is a little bit what RL is. I think you can absolutely view it that way. And I think actually a lot of the work that has suggested that RL is really just eliciting the capabilities of pre trained models like random reward or a single example and then it's just changing the distribution. It's like aligning to the distribution the model has in the first place are I think very in line with that way of thinking about it.
- [44:15]
Swix
You're distilling from a perfect model which is the environment or the verifier or whatever and then you're distilling that into the thing. So it's amazing, it's beautiful.
- [44:24]
Ari Marcos
But the cool thing about rewriting is that because the model that's doing the rephrasing just needs to know how to rephrase. It doesn't need to know how to anything about the content itself. It doesn't need to understand it. It means you can use a pretty weak model to do the rephrasing and have it generalize and generate data that can teach a model that's much better than the model that's doing that rephrasing. So I think with this distillation in disguise, I'm generally quite skeptical that you can get a model that will be better than the teacher that's generating the synthetic data. When you do this sort of net new data creation, it's possible you can could through some sort of heavy rejection sampling on the big model because you're effectively inserting new information when you say which of the synthetic outputs is good or bad. Right. There's some new supervision coming in there, but I'm generally skeptical of that. Whereas we've seen this, we actually have a blog post coming out in the next week or two about kind of our synthetic data generation which we call beyond Web. Wow. And we'll have some cool scientific experiments in there. Too, to our point of trying to figure out this balance where we can share some of the science but also do so in a way that is sustainable for our business. And one of the things you show there actually is that by doing this you can actually get a model to do much, much better than if you had trained on all of the data, all raw tokens in the first place. So that by doing this rephrasing effectively, you actually can break this data wall and now get models that are better than either of the models that generated the data with rephrasing. I think this is super possible because most of the information is coming from the data, it's not coming from the model itself.
- [45:59]
Swix
Couple follow ups on that. Just things I've always wondered, are textbooks all you need?
- [46:04]
Ari Marcos
No, they are not all you need. I think textbooks are great and I think there's a lot of really great content in high quality data points like that. But obviously textbooks are also a very narrow data distribution. And if there's only one thing that you should take away from this entire interview about what is good for data quality, it's diversity in many ways. Right there, there was this like I used to do all this work on out of distribution generalization and we had all of these very careful studies where we would say, okay, let's make this corner of the data distribution, then we leave this held out where it's never seen this combination of things and let's see if it can generalize. And then LLMs and the modern way of training models came along and said, hey, what if nothing was out of distribution? What if we just made it so that we train all the things, everything and everything's now in distribution.
- [46:53]
Swix
And by the way, that's. That is in line with AGI, right? So you might as well.
- [46:57]
Ari Marcos
And that's basically what we've done. And it's worked. It's worked shockingly well, like way beyond anyone I think or most people would have expected. I certainly was shocked by it. I made a strong bet that there is no way you can get compositionality just from scaling and well, you can. Turns out it does work when you get big enough.
- [47:15]
Swix
What I was really referencing was this is the Microsoft v Papers 1, 2, 3, 4. A lot of them do their rephrasing or rewriting in textbook format. And I feel like there's a little bit of cargo culting of like, oh, just because you write like Wikipedia or write like textbooks, the models learn better. I don't know. That's not automatically proven to be the case.
- [47:33]
Ari Marcos
I think that's also probably part of the reason why you see a big difference between the benchmark scores of those models and their real world use. They went to too narrow a distribution. And I think this is the problem with synthetic data fundamentally is that you're always going to have some bias here. I think you can do a lot to make it more diverse and we have put a of lot of effort into finding ways to do that. For example, we rephrase into many, many, many different styles and formats. That's really important to get stuff that's good. But I think this is the risk, right, that you go on way too narrow a distribution and models are always going to be fairly peaky with their output distribution and then that actually results in reducing diversity. That said, I will say that there is a takeaway of that. Textbooks all youl Need. That I think is correct. Which is repeating higher quality tokens is almost always better than seeing net new lower quality tokens. So epoching over higher quality data almost always better than getting the same amount of new data of an unknown quality or of average quality. Average in this case being like what you just get from an Internet dump or something like that. Or even a reasonably filtered Internet dump. It's always better.
- [48:38]
Swix
The modification I made or the study I would want to commission out of that is instead of having another epoch on high quality data, if you found high quality data good, go and paraphrase it and then an entry and on that maybe that'll get additional gains. I don't think I've seen any papers that have been to that effect.
- [48:53]
Ari Marcos
The Kimi paper actually had an experiment to that effect where they tried adding multiple epochs and they looked at how many rephrasings they did of each of them and had some results there that were interesting to that effect.
- [49:03]
Swix
Amazing. And then the other question was more on curriculum. Curriculum learning had a bad rep for a while. How come it's back? What's changed?
- [49:11]
Ari Marcos
Yeah, so a bunch of things. And this was really interesting because when I was going out and initially deciding whether to start datology and raising and talking to various initial recruits and stuff, so it was like mid 23 and at the time I was saying curricula are going to be a really important aspect and a lot of people were basically just like, no, curricula don't work. We tried this a bunch of times and curricula don't work. Curricula are one of these ideas that I think always had to work in the sense that it just made too much sense. There are a Number of these things where it might be hard to figure out how to make it work well, but it always had to work. There was actually a really cool paper from Stanford that had a nice way of conceptualizing this, which is imagine a graph where each of the nodes are a different concept or idea that you want the model to understand. And then the edges are basically the dependency between those concepts, right? So if concept A helps you learn concept B, there would be an edge from concept A to concept B, right? So now this is the graph. Imagine this graph of all concepts in the world and all the different edges between them, right? Huge graph. If that graph is empty, then it would mean that nothing is helpful for learning anything else. And then curricula would not make any sense. You should just randomly order things. If that graph was complete so that there is an edge of equivalent weight between every pair of nodes, then similarly it would mean that everything is equally useful for learning everything else, and curricula don't work and you shouldn't use them. Any other graph besides those two graphs curricula makes sense. I think it's pretty obvious that neither of those is the graph of the actual world that we live in. Clearly, the world does have dependencies. Some very, very obvious. Obvious like the fact that it'd be hard for me to do division and multiplication if I don't understand addition and subtraction and some much more vague. But I have always believed that this has to work. And the challenge has largely been that if you're fully saturating your data, then there's really no advantage of Greek, unless if you wouldn't be able to learn it otherwise. Generally, I think the idea behind curricula is that it makes you much more efficient. But in the supervised learning world, we were fully saturating these data data sets, so maybe a curricula would get you there faster. But that wasn't the bottleneck or the limiting factor. So there wasn't a clear incentive to actually go and do these hard experiments to try to figure out how to make a good curriculum. Because who cares if I can get you to image net performance in 80 epochs instead of 160 epochs? That's nice, but it's not a big deal in the first place. But now we're in this totally different world where now all of a sudden all of our models are underfitting the data. This is super important. Important and getting a curriculum right could literally make the difference between spending 10 times as much on a model, training hundreds of millions of dollars potentially, and now all of a sudden, curricula make a ton of sense. So I think that's why the problem didn't really make sense, to really put a lot of effort into previously. And now we've seen pretty clearly with discrete curricula that this makes a big impact. And largely what we talk about when we say mid training is really just a later phase of your discrete curriculum, I think is another way of thinking about it. Right? You could even think of post training as part of a curriculum. In fact, one of the things that I'm really excited about is, you know, we mostly focus on pre and mid training at Datology. So far, one of the kind of most consistent asks from every one of our customers has been, can you do more on post training? Can you also help us curate the post training data? So we're starting to invest pretty heavily there. And one of the things I'm really excited about is actually viewing this whole thing from pre training to mid training to post training holistically as a single process and then asking questions like how do we optimize our pre training data to make post training more effective? Or things like that. These are I think really exciting questions and something that you don't see happen even at the big labs because they have entirely separate teams. Right? There's a pre training team, there's a mid training team, there's a post training team, and the mid training team is a customer of the pre training team. And the post training team is like a customer of the mid training and pre training team. But it's quite hard to actually have signals propagate through all these. So I think this is a really exciting area.
- [52:56]
Swix
I'll push you a bit on this. Yeah, I think a popular view is post training is elicitation of capabilities that you already trained in pre training. So what dependencies can you have that feedback into pre training?
- [53:09]
Ari Marcos
So I'm inclined to agree with that view and I think that that view would lead very strongly to the fact that you should be trying to optimize your pre training data to make post training processes more effective. So you should try to figure out how do I optimize my pre training data so that the slope of the test time compute curve or so that the slope of the RL curve is as steep as you possibly can be, or alternatively, how do I optimize my pre training data so that the slope of the jailbreaking curve is as shallow as possible? Fundamentally, I think alignment in post training doesn't really make sense as a long term solution. If you can easily align a model through post training. You can easily misalign a model through post training. If it's easy to put it in, it's easy to take it out. If it's really hard to put it in, it's really hard to take it out. That's just like a truism of model. So if you do alignment during pre training, you'll actually end up with models that are, I think, largely impossible to misalign without putting a massive amount of data into them. I think there are a lot of benefits to that and I think we've also seen evidence for this, like looking at the difference between llama and Quen with respect to their ability to be post trained. Right. It's much easier to rl Quen than it is to do llama. Likely that has to do with the fact that quen put a lot of synthetic reasoning traces into their training data.
- [54:14]
Swix
Even with wrong examples.
- [54:16]
Ari Marcos
Yeah, but even with wrong examples it's still showing here, um, which is wild. Right. But I think that pretty clearly shows that it's the base model that's doing it. It's not the rewards you're giving. If, if you give random rewards and the model still learns, it's probably not the reward signal that's doing it.
- [54:34]
Swix
That's cool.
- [54:34]
Alessio
I'm just curious, on the customer usage, how many people are doing post training? Obviously nobody today because you don't have it. But when people come to you, are people looking mostly to do post training on Open models, on OpenAI models or, or what do they ask for?
- [54:49]
Ari Marcos
Yeah, so we usually work with folks who are either training their own models from scratch or doing continued pre training on an open model with a bunch of domain specific data that they have that's unique to their use cases and their business. We typically focus on folks that are doing training with significant cost. So typically that means at least a couple tens of billions of tokens, oftentimes more. So kind of the standard small scale post training fine tuning in case we don't focus as much on. That said, I think this has been a question that a lot of people have asked us consistently like, hey, who's actually training their own models? Why don't I just rely on this, rely on the open models? And I think there are a number of reasons why we see people do this. So first off, I think sovereign AI has been a pretty big place where we've seen a lot of demand. Lots of countries, they want to have models that they own that are unique to their language, their culture, and that requires them to have really good data curation, of course, in order to do.
- [55:42]
Swix
This effectively, just to double click countries, owning models isn't actually a thing that I know about. I'm from Singapore. We have the CEO model, but it's not owned by a country. And I can't name any other country that owns a model.
- [55:54]
Ari Marcos
Yeah, I think that's actually correct. It's largely what you see right now is these public private partnerships where governments are making pretty large grants.
- [56:01]
Swix
PII UAE is the closest.
- [56:03]
Ari Marcos
Yeah, I think you have those. I think you also have these places, right, where the funding is the country. And it becomes a little bit unclear where it comes from. But yeah, I think usually what you see see is that countries are doing big grants to private companies or public private partnerships to go build that sort of sort of thing. So that's a big thing. I think we've seen a lot of larger enterprises that have a lot of their own data that want to do this. And when you think about this, ultimately what we see is that, okay, across those three value, train faster, train better, train smaller, which matters. And when train faster, in principle, that's the easiest one to compute. I say, okay, this model would have cost you $10 million to train. I get it to you, you for a million dollars or for $800,000 or whatever, right? Great, I saved you a ton of money. In practice though, nobody wants to train a $10 million model for a million dollars.
- [56:49]
Swix
But they already have the model.
- [56:49]
Ari Marcos
They already have that. They want to train a $100 million model for $10 million. They want to train better. So train faster usually doesn't matter so much from the perspective of, hey, this model's now a lot cheaper. It does matter a lot more from the perspective of you can iterate much faster. Right? Because when you think of the workflow of most ML engines engineers, you start a training, you go and you sit on your hands until the training finishes. You find something else to do. But largely you're waiting and your iteration is bounded by how long that takes. If you can take something from taking 10 days for a model to finish training to being overnight now, your existing team is way more productive and can do far more iterations and stuff like that. So that's where we usually see that matter the most. Most people care the most about train better. Right? I can get a better model for the same compute and we can absolutely deliver that through data. Data is effectively a compute multiplier because all models are underfitting their data sets. If you can make your model more data efficient, you effectively make your compute more valuable. Because if you think about compute as I inject a certain number of dollars and I get a certain performance back, if I use better data then I will get more performance back per dollar invested and now my compute is more valuable. So that's where train better I think tends to be the most meaningful thing. But interestingly, for the most companies that are most advanced on their AI transformation journey, train smaller is the one that I think actually means the most. Because when you think about the of ownership of these models is going to be very, very heavily weighted towards inference. It's all inference. And you think about a company that's spending say 50 mil a year on inference, which in the scheme of things is not very much, right? If you deploy a model that's twice as big as it needs to be, that's going to cost you 25mil in year one. The cost to train a model that has fewer than half the parameters but is just as good or even better at your particular use cases is say two or three million dollars. That's a no brainer. If you can do it easily, right? If it's really hard, then you're never going to do that. But if you can do it easily and you can get it right on the first try, that's a no brainer. And then 50 milli years is not going to be very much. We know that all of these products have a tiny, tiny fraction of what their eventual user bases will be. We're still very much in the first inning here. Everyone that listens to this podcast is using AI nonstop, but the rest of the world is not. So the inference costs are going to skyrocket with these models. And if you use a general purpose model that then you constrain to say, hey, this model knows about everything. But now only do this one thing. That model is going to have a ton of parameters that do not need to be there that are going to massively increase the cost of serving that model. So I think that when you think about the use case of an enterprise where they need a model that's an inch wide and a mile deep, it can do a small handful of things, but it can do that really, really effectively to five nines of reliability. And it can do it for as low a cost as possible. The economics make it so that it really makes a lot of sense to do this yourself if you can do it easily. And the way we think about it is that there were kind of two big barriers. First, you have to get training right and then you got to get data right. And on the training side, I think three years ago this was super hard. Right. But Mosaic was the first one to really recognize that there was a huge opportunity in making this easy. And now this has largely been commoditized by things like SageMaker and Together and lots of different folks that help you on the training. But on the data side, the barrier is just as high as ever. And in many ways, that's our mission at Datology is how do we bring that barrier down so that anyone who wants to train a model can do so with the best quality data on their first try. They don't have to go and spend 40 years in the desert. They don't have to get it wrong 100 times first, which is what will happen if you don't have this experience. But instead on the first shot, they get a really great model.
- [60:19]
Swix
Yeah, just a follow up question on train smaller. Yeah, I fully agree and I think that this is something a lot of people are investing in. You are primarily doing work on the data side. Data pruning, which maybe is a bad word now. Data curation, whatever. I think a lot of people, Jonathan Frankel was on the podcast very early on, but a lot of people were betting on pruning the model itself. You have a working model at size and you just lop off anything above a certain epsilon. Is that confirmed to just be dead?
- [60:49]
Ari Marcos
So it's funny, Jonathan actually interned with me when I was at Meta and we worked on this stuff together. He had the lottery ticket hypothesis, which is a really beautiful paper, which he now completely disowns. You know, I had this whole idea when Jonathan and I worked together that we wanted to create a lottery ticket initialization. It would just be an initialization you'd sample from for initializing the weights. That would then be one of these, like perfect winning ticket initialization. But we actually found out that the problem was that the lottery ticket was actually data dependent. And that was where the fundamental problem came. That as soon as you change the data distribution a little bit, like the winning tickets exchanged in a really big way. I don't think pruning is dead. Parameter pruning still absolutely has a place, but I think certainly we found it challenging to really realize the potential of it. I think one of the big tricks with pruning parameter pruning, just to be clear, was that unstructured pruning, when you would prune weights randomly, so you view all the weights as a smorgasbord and Just prune them random randomly. That worked really well. And you could remove massive quantities of the weights with unstructured pruning. The problem is that unstructured pruning doesn't really give you a clear compute advantage because you need to have a sparse matrix now to reflect this. And there's a pretty huge overhead of sparse matrix multiplies. GPUs are not very good at sparse matrix multiplies. There's some support for them now.
- [62:10]
Swix
There's some hardware optimizations for that and.
- [62:12]
Ari Marcos
There'S some hardware and people have Talked about building ASICs that would be really good at unstructured pruning, but I don't think I've seen one that works super well. I think if someone did make something that worked really well for models that were pruned in an unstructured way, that could be effective structured pruning, in which case you just remove a unit, you just remove a neuron that is really easy to make as a faster in a gpu, but that just doesn't work nearly as well. So I think there's still potential here. I don't think it's the panacea that I and I think many others had hoped. That said, I think one thing that's cool about using better data to train smaller models is that it's complementary with any other approaches for optimizing inference. So I think pruning and quantization obviously still have a lot of role to play in helping inference go faster. And that would stack on top of anything that we're doing, which I think is kind of cool.
- [63:03]
Swix
Yeah. One also I think kind of grand challenge, golden question that'd be very valuable for you. And just in general is this idea of what is the smallest possible model for given capability? Do you have any insights on that? I did a podcast with Jack Morris, was out of Cornell, and I think there's some information limit and I think he had some answer. It's like 8 bits per parameter or something like that. I forget what the conclusion was.
- [63:29]
Ari Marcos
Yeah, I'm not sure if I would put out a specific number, but I would definitely say far, far smaller than what our current models are trained to be.
- [63:37]
Swix
Right.
- [63:38]
Ari Marcos
We are nowhere close to this. And I am generally of the belief that most of the models that the vast majority of people will be using in say three years will be single digit B or smaller. I think we've seen this very clearly. You look at just the Llama series. If you want to exclude llama 4, do so. But llama 1 through 3, you can see pretty clearly that the 7B variant from N plus one generation is pretty close to the 7DB variant from the prior generation. If it's not quite there. But there's still a very clear trend trend here. We're seeing this with the Quinn models, right? You look at some of these small Quinn models and they're just incredibly performant relative to what state of the art was a year ago. I think it's pretty clear that these models are way too big. I personally would bet against kind of the next frontier being trillion parameter models and rather that we're going to really optimize the inference cost of that. I think also Test Time Compute as a paradigm really pushes you towards small models because if your cost of solving a problem is cost of inference times number of thinking steps and you have to do a lot of thinking steps, well, now this is a really minimizing the cost of inference is really important. And I think that anything we can do to make it so that you can just make that inference model that is doing the one step of thinking a lot faster enables Test Time compute to be a lot more efficient, effective.
- [65:07]
Swix
Yeah, I think there's another version of this which is the sort of Andrej Karpathy cognitive core concept of a model that doesn't know anything, but can use tools a lot to figure out. Again, another information theoretical limit that would be very helpful to figure out is what is the minimal viable model for that stuff like 0 on GPQA, 100 on BrowseConf.
- [65:29]
Ari Marcos
I really like that idea and I think it's very possible to do that because not knowledge storing takes a lot of capacity, it takes a lot of parameters. You don't need it and you don't need it and we can just look. Actually, one of my first papers that I ever wrote was actually about showing that when you train models on randomized labels, because this was something that was kind of a common test to do, that was the one way you could prove that a model was memorizing would be that you randomize all the labels and now there's no actual true association. It would have to memorize it. And models could do this really well. There was an ICLR best paper from 2017 that showed this, that people were really surprised. Surprised that models could memorize all of imagenet. Now this seems crazy because of course models can memorize the whole Internet, but at the time that was crazy. Wait, they could just memorize a million labels? That's wild. And what we found there actually was that if you went and you just deleted units with a model that memorized it would be really damaging to the model that memorized. But a model that actually learned a generalizing solution, you could delete a lot of units and it would be pretty robust to that. So it's actually a very clear demonstration of exactly this concept that the more you memorize, the more capacity using dropout regularization. There's a lot of dualities to dropout and I think there's an argument to be made that dropout helps to prevent memorization and it helps to learn more generalizable solutions. And that's part of why it worked well. But yeah, I think it's very possible to do this. And I think we're wasting a ton of capacity in these models on knowledge that is just totally unnecessary for them.
- [66:49]
Alessio
To have before we wrap. Just because we started with the RCE models and then we never talked about them. I think the most interesting thing to me was they started started with 23 trillion tokens of data and then you helped them get down to 6.6 trillion. Any learnings from that? And this is a 4.5B model which is par with Gemma 4B and a little worse than Quant 3, but roughly the same. Any learnings there experiences things that autobio models should adopt.
- [67:17]
Ari Marcos
So yeah, so we started for that one. We started with a combination of dclm, Nematron and fineweb. We basically just concatenated them all together. It's about 25 trillion tokens to combine for all those to produce 7 trillion out of that. I think what was exciting to us about that was in general seeing the speed at which the model learned. So it was beating Gemma pretty consistently before the 1 trillion mark, which was pretty cool to see and I think really highlighted in many ways how higher quality data can get you much better performance much more quickly. General insights, I think, or takeaways from that. I mean, I think it was exciting for us as kind of one of our first real RC is the first customer that we're talking about and being public about since starting the company. So obviously that was an exciting moment. But I think really generally it's a good showcase about the fact that combining all of these different techniques can give you a really big gain. I think that's one of the things we've been saying, but it's nice to have a real demonstration about that. This is not something where it was synthetic data taking us here or it was filtering taking us here. It was really about thinking about how do we actually combine all of these techniques. And one of the things we've consistently found actually is that when you take these different techniques and you try to make them work together, they don't. Generally you can make them work together, but it's quite hard to do so. So I think what was quite exciting for us there was showing that that's possible and then combined with that. I think people first off tend to think that you can't stack curation. I think the fact that we started with some of the best curated open data sets and were able to make them dramatically better is a pretty good insight to the fact that there's still a ton of headroom left here. Like we didn't need to go to Common Crawl to get those tokens. We are due, of course, doing work on that and, and we think there's a lot we can do to improve there. But just starting from that, and we actually now are making bigger data sets from that. I think we can get up to 15 trillion just starting from that corpus and still have pretty identical quality to that, which is pretty neat. So I think showing that you can get there and that it really stacks. One of the other things we consistently find is that if we apply our curation on top of say DCLM and then we apply it on top of fineweb, the gap between fineweb and DCLM is maintained. In the gap between kind of datology curated DCLM and datology curated fineweb, they both get a lot better. But datology DCLM is still better than datology fineweb. So there really is a lot that we can do here. And I think that would be the biggest thing that I would just say there's so much still left to do here. We're just scratching the surface. We're pretty excited about what these results showed. We already have better data sets than what RC trained on because that model was largely trained in May and pretty excited about all the next trainings that we'll have that go even, even bigger.
- [69:46]
Swix
I have a couple more lightning fun questions. What data does everyone want? Based on your customer conversation, what data does everyone want? But it's really hard to get.
- [69:54]
Ari Marcos
I mean, I think expert data is the pretty obvious thing. That's domain experts, domain expertise. That said, I would also note that most people don't know what data they actually should be getting.
- [70:03]
Swix
They just show up with whatever they have.
- [70:05]
Ari Marcos
Yeah, I think something we've actually found shockingly frequently is we talk to folks who have been planning for a really expensive training run, millions of millions of dollars training run. They've been thinking about the architecture they're going to use, they've been thinking about all this stuff and then they reach out to us and they're like, hey, we realize we need a good data set and we're planning to kick off training in two weeks. Can you help us? And a lot of it's like, hey, you probably should be thinking about your data set before all the other things. If anything, that's actually the most important thing. So I think, I don't say the most surprising thing is maybe how often people don't even have a conception of what good data is. And oftentimes I think when people what they think is good data, data often isn't, which goes to the DCLM point, I think that we mentioned in the past. It's very counterintuitive and really hard for humans to identify. This is high quality, this is low quality.
- [70:53]
Swix
This is a little bit of a recruiting question. What data efficiency question. If somebody had an answer, they should join Datology immediately.
- [71:00]
Ari Marcos
The first thing I would just say is if you are one of these people that keeps on finding yourself just staring at the data, you keep on going into the data set. If you continue, tell me what your favorite and least favorite C4 example is. You belong at Datology. You should come join us and join a bunch of other nerds that love doing that exact same thing. I think in many ways that's kind of the single biggest predictor of whether someone is going to be really happy at Datology is how much do you just look at the data in your own work. Because I think you'd be surprised by how many really talented researchers don't do it very often that they really just view it as a given. I think, I think it's been pretty surprising across the board. That said, there are so many questions that I am on the science side that I'm just super excited about. I mentioned the interactions between pre and post training. That's definitely one that we're really excited about. One of the things that we really care a lot about is making it so that our product and curation automatically adapts to novel data distributions. If you have this where it has to be fully automated and we didn't talk about this too much, but one of our challenges often is if we're working with an enterprise that has a lot of proprietary data data, they obviously don't want to give that to us. So we bring our curation to their data. But this means that it has to adapt automatically. We have pretty limited access into going and looking at that data. So that's actually a really hairy and interesting out of distribution generalization problem. But it's also really important because there's no golden curation. A curation is only optimal with respect to a given set of downstream use cases or tasks. Right. So we need to be able to define based off of if the model needs to be able to do X, Y, how should we use that information to adjust the curation that we do to make sure that we're giving the data that's most relevant for solving tasks xyz. And that needs to happen automatically. So we have a number of ways that we can do that for a number of our techniques. But that's a very broad and general question that we want to apply to every part of our pipeline. So that the way we do synthetic data differs based off of the downstream use case. So the way we're doing this, the way of doing every different part, filtering, et cetera, is going to change based off of that. So that's another of question that we're just really excited about and fundamentally anything about really trying to answer this question about how do you value data with respect to a target. When I think of datology and our core competency, I think every company needs to have an unfair advantage or some core competency. They do better than anyone else. And for us at Datology, I want us to be, and I think we already are the best in the world at valuing data with respect to a downstream use case. In many ways I think that's kind of the NP complete problem of AI. If you can do that, you can kind of do anything. And that's the thing that we're really focused on. And of course curation is like the very obvious direct application of that core competency. But when we think about kind of the vision for the company in the long term, it's about taking what are all the other ways we can operationalize that same core skill set. And I think there are tons of really interesting ways things you can do there. But that's the fundamental question that we really want to answer. And then there are tons of different ends, entry points to that question. But if that's a question that excites you, if you have been working on data somewhere else and you have felt this pain of being a second class citizen or having the data team be kind of dismissed and you want to be in a place where literally the only reason that the company exists is because data is all we care about. The name of the company, Datology, the science of data. That's why we're here. Then you should absolutely talk about to us.
- [74:24]
Alessio
Awesome. And just to wrap on some gossip, let's talk about Meta and Super Intelligence. And just in the notes, when you talk about science moat and whatnot, you raised a lot of money from very prominent people. So you have Jan Lecun as one of your investor. Jeffrey Hinton, Jeff Dean. So Wenari says that they have a science mode. Believe it. So maybe since you have Jan as an investor, this is more of a touchy question, but what do you make of the whole Meta super intelligence team? And Jan was also on LinkedIn and he was like, hey, I'm actually working on. At fair, we're focused on the next generation of AI, not on this current generation, so my role is the same. But then maybe people might say, then why didn't you do the current generation 10 years ago? What do you make of the whole change and whether or not you think this is an interesting direction for meta, especially given the large platform and user base that they have?
- [75:22]
Ari Marcos
Well, first, with respect to Jan specifically, I mean, Jan's an incredibly talented scientist, of course, but I think that his preference has always been to do science rather than to run an organization. So I think he ran FAIR organizationally for a year or two right at the very beginning. But pretty quickly he handed that off to other people. And when I was there, it was Joelle Pinault and Antoine Bordes and then Joelle for most of it that really were running for. And she was an incredible leader. I really respect her deeply and couldn't have asked for a better kind of advocate for science within fair.
- [75:53]
Swix
When she left, people were saying, this is the end of fair.
- [75:55]
Ari Marcos
I hope that's not true, but I also had that concern. But I think Jan always really wanted to just actually do the science himself. And he's generally, for most of the time I was at fair, he kind of operated with his own group of a couple postdocs and visiting scientists. And then he'd have a couple students through animals, nyu, and he would kind of do his own research there. So I don't think he was ever, or at least not since the beginning, in a role where he was defining AI strategy for meta. I don't think that's the role he wanted at any point. I think he really wanted to be doing that research. So I don't think that his role probably is changing very significantly in the sense that he wasn't doing that previously, and I don't think it was what he wanted to do. I mean, I think one thing that's pretty cool about it obviously is it showcases the importance of data, that Meta is willing to spend quite this much on scale kind of acquisition, not acquisition that we're seeing today.
- [76:44]
Swix
Alex Wang is not going to underrate data, let's put it that way.
- [76:48]
Ari Marcos
Yes, he's not going to underrate the importance of data. And I do think that this is an area where the stuff we've done is quite different than I think what we've seen from the data annotators, which have been more focused on collecting the data versus actually optimizing and curating it. I think there's quite a bit you can do on top the of of those things. So I think it definitely draws some attention to that. I will also just say, generally when Zuck makes a very big bet, it's not proven wise to bet against him. Just historically that's been the case and most of the big bets I think have panned out. I think the one that's still really up in the air is the Metaverse, but I would actually argue that I think that's going to end up paying off in the long run. I think the Ray Ban glass is pretty darn cool. And a lot of the foundations of what was in reality Reality Labs will go into those also. Fair was part of Reality Labs actually for like a year and a half after one reorg, like initially Fair wasn't and then it got reorged into Reality Labs. So I think when I left, actually Fair was officially part of Reality Labs. Wow. If I recall correctly, and there was at least a one and a half, two year period where that was the case. So some of the AI investment actually that like laid the foundations came out of real out of that Metaverse investment in the first place. You know, that said, I think, you know, we talk about data as being a compute multiplier all the time. Talent, I think obviously, is a compute multiplier. And given the amounts that they're spending on compute, I think you can make a good argument as to why spending a crazy amount on talent is also worth it. So I'm excited to see what they do. I hope that they put a lot of focus on data and become customers. Yes.
- [78:15]
Swix
Awesome. Well, thank you so much for chatting and coming by and insisting on in person because you're actually very charismatic in person. So I'm glad you did this.
- [78:23]
Ari Marcos
Well, thank you very much. Thanks for having me and a joy to, to get to chat in real life.
- [78:28]
Swix
Awesome.
- [78:29]
Ari Marcos
Cool.