← Latent Space: The AI Engineer Podcast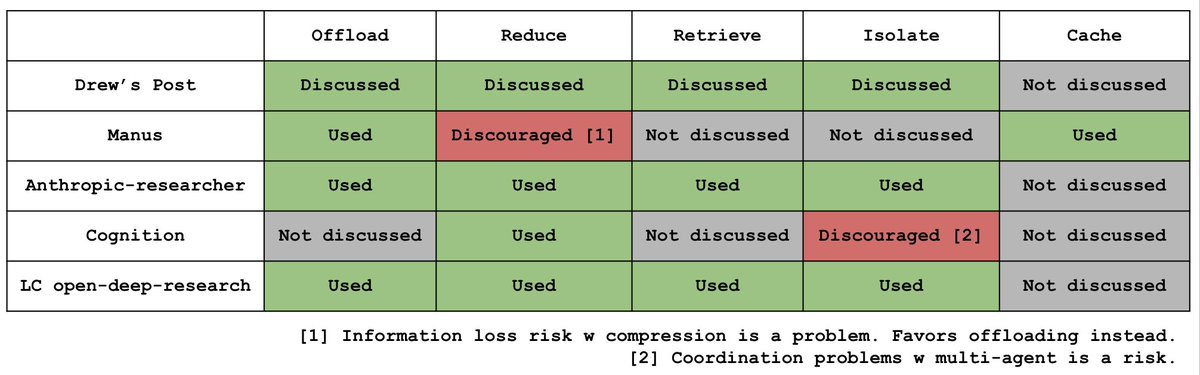
Latent Space: The AI Engineer Podcast
Context Engineering for Agents - Lance Martin, LangChain
00:57:33
Loading summary
Transcript109 lines
- [00:00]
Lance Martin
Foreign.
- [00:05]
Alessio
Welcome to the Latent Space Podcast. This is Alessio, founder of Kernel Labs, and I'm joined by Swix, founder of Small AI.
- [00:11]
Swix
Hello. Hello. We are so happy to be in the remote studio with Lance Martin from LangChain, Langgraph and everything else he does. Welcome.
- [00:20]
Lance Martin
It's great to be here. I'm a longtime listener of the POD and is finally great to be on.
- [00:25]
Swix
You've been part of our orbit for a while. You spoke at one of the AIEs and also obviously we're pretty close with LangChain recently though you've also been doing a lot of tutorials. I remember you did R1 deep researcher, which is a pretty popular project, and Async Ambient Agents. But the thing that really sort of prompted me to reach out and say like, okay, it's finally time for the Lance martinpod is your recent work on context engineering, which is all the age. How'd you get into it?
- [00:54]
Lance Martin
Well, you know, it's funny, buzzwords emerge oftentimes when people have a shared experience. And I think lots of people started building agents kind of early this year, mid this year, quote unquote, the year of agents. And I think what happened is when you kind of put together an agent, it's just tool calling a loop. It's relatively simple to lay out, but it's actually quite tricky to get to work well, and in particular, managing context with agents is a hard problem. Karpathi put out that tweet canonizing the term context engineering, and he kind of mentioned this nice definition, which is context engineering is the challenge of feeding an LLM just the right context for the next step, which is highly applicable to agents. And I think that really resonated with a lot of people. I in particular had that experience over the past year working on agents, and I wrote about that a little bit in my piece Talking about building OpenDeep research over the past year. So I think it was kind of an interesting point that the term capture common experience that many people were having, and it took hold because of that.
- [01:54]
Alessio
How do you define the lines between prompt engineering and context engineering? So is a prompt optimization context engineering in your mind? I think people are confused. Are we replacing the term? What is it?
- [02:08]
Lance Martin
Well, I think that prompt engineering is a subset of context engineering. I think when we move from chat models and chat interactions to agents, there was a big shift that occurred. So with chat models working with ChatGPT, the human message is really the primary input. And of course a lot of time and effort is spent in crafting the right message that's passed to the model. With agents, the game is a bit trickier though, because the agent's getting context not just from the human, but now context is flowing in from tool calls during the agent trajectory. And so I think this was really the key challenge that I observed, and many people observed is like, oof. When you put together an agent, you're not only managing of course the system instructions, but system prompt and of course user instructions. You also have to manage all this context that's flowing in at each step over the course of a large number of tool calls. And I think there's been a number of good pieces on this. Manus put out a great piece talking about context engineering with Manness, and they made the point that the typical Manus task is like 50 tool calls. Anthropics Multi Agent research is another nice example of this. They mentioned that the typical production agent, and this is probably referring to cloud code, could be other agents that they've produced is like hundreds of tool calls. When I had my first experience with this, I think many people have this experience. You put together an agent, you're sold the story. That's just tool calling in a loop. That's pretty simple. You put it together. I was building deep research. These research tool calls are pretty token heavy. And suddenly you're finding that my deep researcher, for example, with a naive tool calling loop was using 500,000 tokens. It was like a dollar to $2 per run. I think this is an experience that many people had and I think it's kind of that the challenge is realizing that, oof, building agents is actually a little bit tricky because if you just naively plumb in the context from each of those tool calls, naively, you just hit the context window of the LLM. That's kind of the obvious problem. But also Jeff from Chroma spoke about this on the recent podcast. There's all these weird and idiosyncratic failure modes as context gets longer. So Jeff has a nice report on context rot. And so you have both these problems happening if you build a naive agent. Context is flowing in from all these tool calls. It could be dozens to hundreds. And there's degradation in performance with respect to context length and also the trivial problem of hitting the context window itself. So this was kind of, I think, the motivation for this new idea of actually it's very important to engineer the context that you're feeding to an agent. And that spawned into a bunch of different ideas that I put together in the blog post that people are using to handle this. Drawn from anthropic, from my own experience, from Manus and others.
- [04:47]
Swix
So I'm just going to put some of the relevant materials on screen. Just because we like to participate, we like to have some visual aid. We did our posts on GPT5 and we call it thinking with tools. So we're dealing with part of the tools is to get context. And I think using tools to obtain more context, like the agent can figure out what context it needs and if you just tell it to. And then the other one is actually, I thought you did a blog post on this, but apparently it was just like, this is it.
- [05:14]
Lance Martin
I will say it's funny and actually I was hoping you'd bring this up. I also have a blog post, but it's all moving so quickly that I didn't meet up after the blog post and updated the story a little bit with this meetup. So actually this is a better thing to show. But I do have a blog post too. But things change between my blog post and the meetup, which are like two weeks apart. So that's how quickly these things are moving. Exactly. That's the blog post.
- [05:36]
Swix
Should we do this sequentially then?
- [05:37]
Lance Martin
I think it's actually okay to just hit the meetup because it's just easier to follow one thing and it, it's. It's like a superset of the blog post story.
- [05:46]
Alessio
Okay, how do you define the five categories? So I mean, I understand what offload kind of means, but like, can you maybe. Yeah, go deeper.
- [05:57]
Lance Martin
Yeah, we should. Let's walk through these. Actually, when I talked about naive agents and the first time I built an agent, agent makes a bunch of tool calls. Those tool calls are passed back to the LLM at each turn and you naively just plumb all that context back. And of course what you see is the context window grows significantly because this tool feedback is accumulating in your message history. A perspective that man has shared in particular I thought was really good. It's important and useful to offload context. Don't just naively send back the full context of each of your tool calls. You can actually offload it. And they talk about offloading it to disk. So they talk about this idea of using the file system as externalized memory rather than just writing back the full concepts of your tool calls, which could be token heavy. Write those to disk and you can write back a summary. It could be a URL, something so that the agent knows it's retrieved a thing. It can fetch that on demand, but you're not just naively pushing all that raw context back to the model. So that's this offloading concept. Note that it could be a file system, it could also be for example, agent state. So Langgraph, for example, has this notion of state. So it could be kind of the agent runtime state object, it could be the file system. But the point is you're not just plumbing all the context from your tool calls back into the agent's message history. You're saving it in externalized system, you're fetching it as needed. This saves token costs significantly. So that's the offloading concept.
- [07:25]
Alessio
I guess the question on the offloading is like, what's the minimum summary metadata or whatever you need to keep in the context to let the model understand what's in the offloaded context. Like if you're doing deep research, obviously you're offloading kind of like the full pages maybe, but like how do you generate like an effective summary or blurb about what's in the file?
- [07:45]
Lance Martin
This is actually a very interesting and important point. So I'll give an example from what I did with OpenDeep Research. So OpenDeep Research is a deep research agent that I've been working on for about a year and it's now, according to Deep Research Bench, the best performing deep research agent, at least on that particular benchmark. So it's, it's pretty good. Listen, it's not as good as OpenAI's deep research, which uses end to end RL. It's all fully open source and it's pretty strong. So I just do carefully prompted summarization. I try to prompt the summarization model to give an exhaustive set of kind of bullet points of the key things that are in the post, just so the agent can know whether to retrieve the full context later. So I think it's kind of prompting if you're doing summarization carefully for recall, compressing it, but like making sure that all the key bullet points necessary for the LLM to know what's in that piece of full context is actually very important when you're doing this kind of summarization step. Now Cognition had a really nice blog post talking about this as well, and they mentioned you can really spend a lot of time on summarization. So I don't want to trivialize it, but at least my experience has been it's worked quite effectively. Prompt a model carefully to capture. Exactly. So in this post they talk a lot about even using a fine tuned model for performing summarization. In this case, they're talking about agent to agent boundaries and summarizing e.g. message history. But the same challenges apply to summarizing e.g. the full contents of token heavy tool calls so the model knows what's in context. I basically spent a lot of time prompt engineering to make sure my summaries capture with high recall what's in the document but compress the content significantly.
- [09:27]
Swix
I do think that the compression that was also part of the meetup findings of yesterday where we were at the context engineering meetup that Chroma hosted that you do want frequent compression because you don't want to hit the context route limit. I'm not sure there's much else to say like offloading is important and you should probably do it. There was also a really interesting link, I guess somebody, I think dex was linking it to the concept of multi agents and why you do want multi agents is because you can compress and load in different things based on the role of the agent and probably a single agent would not have all the context.
- [10:02]
Lance Martin
That's exactly right. And actually one of the other big themes I hit and talk about quite a bit is context isolation with multi agent. And I do think this does link back to the cognition take, which is interesting. So their argument against multi agent, it's.
- [10:18]
Swix
Literally called don't build multi agent.
- [10:20]
Lance Martin
Correct. And what they're arguing is a few different things. One of the main things is that it is difficult to communicate sufficient context to subagents. They talk a lot about spending time on that summarization or compression step. They even use a fine tuned model to ensure that all the relevant information so they actually show it a little bit down below as kind of a linear agent. But even at those agent agent boundaries they talk a lot about being careful about how you compress information and pass it between agents.
- [10:51]
Alessio
Yeah, I think the biggest question for me coding is kind of like the main use case that I have and I think I still haven't figured out how much of value there is in showing how the implementation was made to then write. If you have a sub agent that writes tests or you have a sub agent that does different things, how much do you need to explain to it about how you got to the place the code base is in versus not? And then does it only need to return the test back in the context of the main agent? If it has to fix some code to match the test, should it say that to the main agent? I think that's kind of like it's clear to me like the deep research use case because it's kind of like atomic pieces of content that you're going through. But I think when you have state that depends between the sub agents, I think that's the thing is still unclear to me.
- [11:39]
Lance Martin
That's one of the most important points about this context isolation kind of bucket. So cognition argues, which actually I think is a very reasonable argument. They argue don't do subagents because each subagent implicitly makes decisions and those decisions can conflict. So you have subagent one doing a bunch of tasks, subagent two doing a bunch of tasks. Those kind of decisions may be conflicting. And then when you try to compile the full result in your example with coding, there can be tricky conflicts. I found this to be the case as well. And I think a perspective I like on this is use multi agent in cases where there's very clear and easy parallelization of tasks cognition. And Walden Yan spoke on this quite a bit. He talks about this idea of kind of read versus write tasks. So for example, if each subagent is writing some component of your final solution, that's much harder. They have to communicate like you're saying, and agent to agent communication is still quite early. But with deep research, it's really only reading. They're just doing context collection and you can do a write from all that shared context after all the subagents work. And I found this worked really well for deep research and actually anthropic report on this too. So their deep researcher just uses parallelized subagents for research collation and. And they do the writing in one shot at the end. So this works great. So it's a very nuanced point that what you apply context isolation to in terms of the problem, yes, you can see this is their work matters significantly. Coding may be much harder. In particular, if you're having each subagent create one component of your system, there's many potentially implicitly conflicting decisions each of the sub agents are making. When you try to compile a full system, there may be lots of conflicts with research. You're just doing context gathering in each of those subagent steps and you're writing in a single step. So I think this was kind of a key tension between the cognition take don't do multi agents and the anthropic take. Hey, multi agents work really well. It depends on the problem you're trying to do with multi agents. So this was a very subtle and interesting point. What you apply multi agents to matters tremendously in how you use them. I like the take that apply multi agents to problems that are easily parallelizable, that are read only e.g. context gathering for deep research and do like the final quote unquote write in this case report writing at the end. I think this is trickier for coding agents. I did find it interesting that claude code now allows for sub agents, so they obviously have some belief that this can be done well, or at least it can be done. But I still think I actually kind of agree with Walden's take. It can be very tricky in the case of coding if sub agents are doing tasks that need to be highly coordinated.
- [14:29]
Swix
I think that's a well explained contrast and comparison. Not much to add there. I think it's interesting that they have different use cases and different architectures evolved. I don't know if that's a permanent thing that might fall to the bitter lesson as you would put it. Yes, we should probably talk about some of the other parts of the system that you set up. Yeah, because there's a lot of interesting techniques there.
- [14:52]
Lance Martin
Let's talk about classic old retrieval. So RAG is obviously it has been in the air for now many years, obviously well before LLMs and this client pole wave. One thing I found pretty interesting is for example, different code agents take very different approaches to retrieval. Varun from Windsurf shared an interesting perspective on how they approach retrieval in the context of Windsurfing. So they use classic code chunking along carefully designed semantic boundaries, embedding those chunks. So classic kind of semantic similarity vector search and retrieval. But they also combine that with for example grep. They then also mention knowledge graphs. They then talk about combining those results, doing re ranking. So this is kind of your classic complicated multi step RAG pipeline. Now what's interesting is Boris from Anthropic and Cloud Code has taken a very different approach. He's spoken about this quite a bit. Cloud code doesn't do any indexing. It's just doing quote unquote agentic retrieval, just using simple tool calls. For example, using GREP to kind of poke around your files. No indexing whatsoever. And it obviously works extremely well. So there's very different approaches to kind of rag and retrieval that different code agents are taking. And this seems to be kind of an interesting and emerging theme like when do you actually need more hardcore indexing? When can you just get away with simple just kind of agentic search using very basic file tools?
- [16:24]
Swix
Yeah, One of the more viral moments from one of our recent podcasts was Boris Part with us and Klein also mentioning that they just don't do Code indexing, they just use agentic search and that's a really good 8020. And then if you really want to fine tune it, probably you want to do a little mix, but maybe you don't have to for your needs.
- [16:44]
Lance Martin
Yeah, I actually just saw Klein posted I think yesterday talking about that they only use grep, they don't do indexing. And so I think within the retrieval area of context engineering, there are some interesting trade offs you can make with respect to are you doing kind of classic vector store based semantic search and retrieval with a relatively complicated pipeline like Varun's talking about with Windsurf, or just good old kind of agentic search with basic file tools? I will note I actually did a benchmark on this myself. I think there's a shared blog post somewhere. I'll bring it up right now. Yep, I actually looked at this a bit myself. This was a while ago, but I compared three different ways to do retrieval on all landgraph documentation for a set of 20 coding questions related to landgraph. So I basically wanted to allow different code agents to write langgraph for me by retrieving from our docs. I tested claude code and cursor. I used three different approaches for grabbing documentation. So one was I took all of our docs around 3 million tokens. I indexed them in a vector store, just a classical vector store search and retrieval. I also used an LLMs txt with just a simple file loader tool. So that's kind of more like the agentic search. Just basically look at this LLM TXT file which has all of the URLs of our documents with some basic description and let the LM or the code agent in this case just make tool calls to fetch specific docs of interest. And I also just tried context stuffing to take all the docs 3 million tokens and just feed them all to the code agent. So these are some results I found comparing claude code to cursor. And interesting what I actually found. This is only my particular test case, but I actually found that elem Txt with good descriptions which is just very simple. It's just basically a markdown file with all the URLs of your documentation and like a description of what's in that doc just that passed to the code agent with a simple tool just to grab files is extremely effective. And what happens is the code agent can just say okay, here's the question. I need to grab this doc and read it. It'll read it. I need to grab this doc, read it, read it this worked really well for me and I actually use this all the time. So I actually personally don't do vector store indexing. I actually do LM Txt with a simple search tool with claude code is kind of my go to Claude code. In this case, this was done a few months ago. These things are always changing. In this particular point in time, Claud code actually outperformed Cursor for my test case. This actually claude code pilled me and this was. I did this back in April. So I've been kind of on Claude code since, but that was really it. So this kind of goes to the point that Boris has been making about Claude code about Incline as well. You give an LLM access to simple file tools. In this case I actually use an LLM Txt to help it out so it can actually know what's in each file. It's extremely effective and much more simple and easier to maintain than building an index. That's just my own experience as well.
- [19:46]
Swix
The scaled out form of LLMs Txt I really like and I use quite a bit is actually the deep wiki from Cognition. So I made a little Chrome extension for myself where any repo, including yours, I can just hit deep wiki. And this is an LLMs txt kind of. But also I read it.
- [20:05]
Lance Martin
This is a great example and actually I think that this could be a very nice approach. Take a repo, compile it down to some kind of easily kind of readable. Yeah, LLM Txt. What I actually found was even using an LLM to write the descriptions helped a lot. So I have actually a little package on my GitHub where it can rip through documentation and just pass it to a cheap LLM to write a high quality summary of each doc. This works extremely well. And so that LL Txt then has LLM generated. Yeah, this one. This is a little repo. It got almost no attention and. But I found it to be very useful. So basically can. It's. It's trivial. You just point it to some documentation. It can kind of rip through it, grab all the pages, send each one to an LLM and LLM writes a nice description, compiles it into an LLM Txt file I found when I did this and I then fed that to Claude code. Claude code's extremely good at saying okay based on the description. Here's the page I should load. Here's the page I should load for the question asked. I use it when I'm trying to generate element. Txt for new documentation, but I'VE done this for Langgraph. I've done it for a few other libraries that I use frequently. You just give that to Claude code, then claud code can rip through and grab docs really effectively. Super simple. The only catch is I found that the descriptions in your LLM Txt matter a lot because the LLM actually has to use the descriptions to know what to read, you know. Anyway, that's just a nice little utility that I use all the time.
- [21:31]
Alessio
When we had Client this at the context 7 MCP by Upstash, which is like an MCP for like project documentation and stuff like that, was one of the most used. Have you tried it? Have you seen anything else like that that automates some of this stuff away?
- [21:45]
Lance Martin
Well, you know, it's funny. We have an MCP server for linegraph documentation that basically gives, for example, Claude code the nlm Txt file in a simple search file search tool. Now, Claude has built in Fetch tools, but at the time we built it, it didn't. But it's a very simple NCP server that exposes ellm Txt files to, for example, cloud code. It's called MCP Doc. So it's a little, very simple utility. I use that all the time. Extremely useful. So you basically can just point it to all the elem Txt files you want to work with.
- [22:17]
Alessio
Well, the MCP docs have a MCP server that you can search the docs with, so it's kind of all the way down. But I guess my question is like, should this be like one server per project? Or like at some point you're going to have kind of like a meta server? And I think part of it is once you move on from just doing tool calling in servers to doing things like sampling and kind of like prompts and resources and stuff like that, you can do a lot of the extraction in the server itself as well. And again, it goes back to your point on context engineering. It's like maybe you do all that work not in the context, but in the server, and then you just put the final piece that you care about in the context. But it seems like very early.
- [23:01]
Lance Martin
Yeah, this is actually a very interesting point. I've spoken with folks from Anthropica about this quite a bit. It is. I found that storing prompts in MCP servers is actually pretty important, in particular to tell the LM or code agent how to use the server. And so I actually end up do having separate servers for different projects with specific prompts. And also sometimes I'll have. You can Also serve resources. So sometimes I have specific resources for that particular project in the server itself. So I actually don't mind separating servers project wise with project specific kind of context and prompts necessary for that particular task.
- [23:36]
Swix
Yeah, a lot of people actually may have missed some features of the NCP spec and you do have prompts in there. It's probably one of the first actual features that they have, which actually may be kind of underrated. Like people kind of view MCP as just in tool integration, but there's actually a lot of stuff in here, including sampling, which is underrated too.
- [23:59]
Lance Martin
That's exactly right. And actually the prompting thing is pretty important because even to use our little simple MCP doc server for langgraph docs, you actually. I found it. It's better of course if you prompt it, but then I had to put in the readme initially, like, oh, okay, here's how you should prompt it. But of course that prompt can just live in the server itself. So you can kind of compartmentalize the prompt necessary for the LLM to use the server effectively within the server itself. And this was a problem I saw initially. A lot of people were using our MCP doc server and then finding, oh, this doesn't work well. And it was like, oh, it's a skill issue, you need to prompt it better. But then that's our problem. The prompt should actually live in the server and should be available to the code agent.
- [24:35]
Swix
Right.
- [24:36]
Lance Martin
So it knows how to use the server. Right. So that's maybe retrieval. And that's a whole. Retrieval is a big theme. It obviously predates this new term of context engineering, but there's a lot going on in the retrieval bucket. It certainly is an important subset of context engineering.
- [24:50]
Swix
I'm wondering if there's any other trends in retrieval. Before you leave the topic, I think one other thing I was tracking was just Colbert and the general concept of late interaction. I don't know if you guys do a ton on that, but some sort of in between element between full agentic and full pre indexing and two phase indexing maybe is what I would call it. Any comments on that?
- [25:15]
Lance Martin
I haven't personally looked at Colbert very much. I played with it only a little bit, so we don't have much perspective there, unfortunately.
- [25:21]
Swix
All right, happy to move on.
- [25:23]
Lance Martin
We could talk about me reducing context briefly. Everyone's had an experience with this because if you use cloud code, you hit that 95. You know, you've hit 95% of the context window and you're about to. And cloud code is about to perform compaction. So that's like a very intuitive and obvious case in which you want to do some kind of context reduction when you're near the context window. I think an interesting take here though is there's a lot of other opportunities for using summarization. We talked about a little bit previously with offloading, but actually at tool called boundaries is a pretty reasonable place to do some kind of compaction or pruning. I use that in OpenDeep research. Hugging face actually has a very interesting OpenDeep research implementation. It actually uses like not a coding agent but the code agent agent implementation. So instead of tool calls as JSON, tool calls are actually code blocks. They go to a coding environment that actually runs the code. And one argument they make there is that they perform some kind of summarization or compaction and only send back limited context to the LLM leave the raw tool call itself which is often token heavy as we're talking about deep research in the environment. So it's another example Anthropic and their multi agent researcher also does summarization of findings. So I think you see pruning show up all over the place. It's pretty intuitive. I think an interesting counter to pruning was made by Manus. They make the point and the warning that pruning comes with risk, particularly if it's irreversible. And cognition kind of hits this too. They talk about we have to be very careful with summarization. You can even fine tune models to do it effectively. That's actually why Manus kind of has the perspective that you should definitely use context offloading. So perform tool calls, offload the raw observations to for example disk so you have them then sure do some kind of pruning summarization like Alessia was asking before to pass back to the LLM useful information. But you still have that raw context available to you, so you don't have kind of lossy compression or lossy summarization. So I think that's an important and useful caveat to note on the point of summarization or pruning. You have to be careful about information loss.
- [27:43]
Swix
This is something that people do disagree on and I'll just flag this on pruning mistakes, pruning wrong paths. Mana says keep it in and so you can learn from the mistakes. So other people would say that, well, once you've made a mistake, it's going to keep going down that path that there's a mistake you got to. You got to unwind or you Just got to like prune it and tell it. Do not do the thing I know to be wrong. So you. So then you just do the other thing. I don't know if you have an opinion, but like, I would call this out as a. There was someone that spoke yesterday that disagreed with this.
- [28:13]
Lance Martin
That's actually very interesting. Drew Bruinig has a nice blog post that hits this point. He talks about this theme of context poisoning, and apparently Gemini reports on this in their technical report. He talked about, for example, a model can perform a hallucination, and that hallucination is stuck in the history of the agent, and it can kind of poison the context, so to speak, and kind of steer the agent off track. And I think he cited a very specific example from Gemini 25 playing Pokemon they mentioned in the tech and report. So that's one perspective on this issue of we should be very careful about mistakes in context that can poison the context. That's perspective one. Perspective two is like you're saying is if an agent makes a mistake, for example, calling a tool, you should leave that in so it knows how to correct. So I think there is an interesting tension there. I will note it does seem that Claude code will leave failures in. I notice when I work with it, for example, it'll kind of have an error, the arrow will get printed and it'll kind of use that to correct. So. And in my experiences working with agents, in particular for tool call errors, I actually like to keep them in. Personally, that's just been my experience. I don't try to prune them. Also, for what it's worth, it can be kind of tricky to prune from the context, from the message history. You have to decide when to do it. So you're introducing a bunch more code you have to manage. So I'm not sure. I love the idea of kind of selectively trying to prune your message history when you're building an agent. It can add more logic that you need to manage within your kind of agent scaffolding or harness.
- [29:40]
Swix
It's a classic sort of precision recall, but like, sort of reinvented for context in an agentic workflow.
- [29:47]
Lance Martin
Exactly. Exactly. Right.
- [29:49]
Swix
While we're on the topic of Drew, Drew is obviously another really good author. He's coined a bunch of sort of context engineering lore. Any other commentary on stuff that you particularly like or disagree with?
- [30:01]
Lance Martin
So he and I did a meetup on this, and I kind of like this quote from Stuart Brand. It was kind of comical. If you want to know where the future is being Made look for where language is being invented and lawyers are congregating. And it was talking about this idea of why buzzwords emerge. And he actually was the one who turned me onto this idea that a term like conduct engineering catches fire because it captures an experience that many people are having. They don't come out of nowhere. And if you scroll down a little bit, he kind of talks about this. He's a whole post about kind of, I think it's how to build a buzzword. But he talks a lot about this idea of kind of successful buzzwords are capturing a common experience that many of us feel. And I think that's kind of the genesis of context engineering is also largely because many of us build agents. Ooh. There's lots of ways they can be quite tricky. And oh, context engineering is kind of what I've been doing. And you hear a number of people saying it and then it kind of resonates and you say, oh, okay, yes, that describes my experience. So I think that's just an interesting aside on kind of how language emerges anthropologically in different communities.
- [31:00]
Swix
I will co sign this because that's exactly what I use to coin or come up with. AI engineer.
- [31:06]
Lance Martin
AI engineer. No, exactly.
- [31:08]
Swix
Just because people were trying to hire software engineers that were more up to speed than AI and engineers wanted to work at companies that would respect their work and maybe also come out from the baggage of classical ML engineering. A lot of AI engineers don't even need to use Pytorch because you can just prompt and do typical software engineering. And I think that's probably the right way, at least in a world where most of the frontier models are coming from closed labs.
- [31:37]
Lance Martin
I think an interesting counter on this is when you, for example, people try to create language that doesn't really resonate, that doesn't capture common experience. It tends to flop. So which is to say that buzzwords kind of co evolve with the ecosystem. They tend to kind of become big and resonate because they actually capture experience. Many people try to coin terms that don't actually resonate that go nowhere.
- [31:57]
Swix
Alessia, do you have experience with that?
- [32:00]
Alessio
I'm the worst at naming things, but you do a great job, Sean. Yes, you nailed it. The few ones you put on Leyden's face. So that's right.
- [32:09]
Swix
Cool. Well, you know, I wanted to talk about context engineering. Okay. So sorry, I don't know if I sidetracked you a little bit.
- [32:15]
Lance Martin
No, that's perfect.
- [32:16]
Swix
The meta stuff on that hits a.
- [32:19]
Lance Martin
Lot of the major themes. I can maybe just Talk very brief about one more. We could talk about bitter lesson and some other things.
- [32:25]
Swix
Yeah.
- [32:25]
Lance Martin
If you go back to that table, I just wanted to give Manus a shout because I thought they had one other very interesting point.
- [32:32]
Swix
Oh, the table that you had.
- [32:34]
Lance Martin
Yes, exactly. We talked about offloading, reducing context retrieval, context isolation. Those are, I think, the big ones you can see, very commonly used. I do want to highlight Manus. I thought they had a very interesting take here about caching, and it's a good argument. When people have the experience of building an agent, the fact that it runs in a loop and that all those prior tool calls are passed back through every time is quite like a shock. The first time you build an agent, you have one token every tool call and you incur that token cost every pass through your agent. And so Manus talks about the idea of just caching your prior message history. It's a good idea. I haven't done it personally, but it seems quite reasonable. So caching reduces both latency and cost significantly.
- [33:19]
Swix
But don't Most of the APIs auto cache for you? I mean, if you're using like OpenAI, you would just automatically have a cache hit.
- [33:25]
Lance Martin
I'm actually not sure that's the case. For example, when you're building agent, you're passing your message history back through every time. As far as I know, it's stateless.
- [33:32]
Swix
There's different APIs for this across the different providers. But especially if you use just the Responsys API, the new one, it should be that if you're never modifying the state, which is good for you, if you believe that you shouldn't compress conversation history, bad for you if you do. If you never modify the state, then you can just use the assistance API. Everything that you passed in prior is going to be cached, which is kind of nice. Anthropic used to require weird header thing and they've made it more automatic.
- [34:01]
Lance Martin
Yeah, okay, so that's a good call out. So I had used Anthropic's kind of caching header explicitly in the past, but it may be the case that caching is automatically done for you, which is fantastic. If that's the case, I think it's a good call up for Manus.
- [34:13]
Swix
Yeah. Gemini also introduced implicit caching. Yeah, it's really hard to keep up. You basically have to follow everyone on Twitter and just read everything. So that's my bullet bot for it.
- [34:23]
Lance Martin
Yeah, yeah, yeah, yeah. Well, you know, it's interesting though. So APIs are now supporting caching more and more. That's fantastic. I'd use Anthropic's explicit caching header in the past. I do think an important and subtle point here is that caching doesn't solve the long context problem. So it of course solves the problem of like latency and cost. But if you still have a hundred thousand tokens in context, whether it's cached or not, the LLM is utilizing that that context. This came up. I actually asked Anton this in their context rot meetup or in their context rot webinar and they kind of had mentioned that the characterization of context rot that they made they they think they would expect to apply whether or not using caching. Caching shouldn't actually help you with all the context rot and long context problems. It absolutely helps you with latency and cost.
- [35:10]
Swix
I do wonder what else can be cached. I feel like this is definitely a form of lock in because you ideally want to be able to run prompts across multiple providers and all that. And yeah, caching is a hard problem. I think ultimately you control your destiny if you can run your own open models because then you can also control the caching. Everything else is just a half approximation of that.
- [35:36]
Lance Martin
That's right. That's exactly right.
- [35:38]
Swix
That is overall broad context engineering. Alessio, I don't know if you have any other takes from like the meetup yesterday or questions.
- [35:44]
Alessio
No, I think my main take from yesterday was like quality of compacting. I think there was like one of the charts was using the automated compacting of like a open code and some of these tools is basically the same as not doing it, unlike the quality of what you get from the previous instructions. And I think Jeff at discharge is like curated compacting is like 2x better. But I'm like how to, you know, it's like how do you do curated compacting? I think that's something that maybe we can do a future blog post on. I think that's interesting to me like how do you compact, especially coding agents, things where like it can get very, very long. I think for things like deep research is like, look, once I get the report it's fine. But for coding it's like, well, I would like to keep building. I found that even when you're writing tests or you're doing changes, having the previous history, it's helpful to the model. It seems to perform better when it knows why it made certain decisions. And I think how to extract that in a way that is more token efficient and still unclear. I don't have an answer but maybe a request for work by people listening.
- [36:50]
Lance Martin
Yeah, you know, that's a great point. It actually echoes some of Walt and Dan's points from Cognition also that the summarization compaction step is just, is non trivial. You have to be very careful with it. Devin uses a fine tuned model for doing summarization within the context of coding. So they obviously spend a lot of time and effort on that particular step. And Manus kind of calls out that they are very careful about information loss. Whenever they do pruning compaction summarization they always use a file system to offload things so they can retrieve it. So it's a good call out that compaction is risky when you're building agents and very tricky.
- [37:26]
Swix
You know, I think there were a lot of, there's a lot of previously a lot of interest in memory and I'm always, I was thinking about the interplay between memory and context engineering. I mean, are they kind of the same thing? Is it just a rebrand? Are there parts of memory? And you know, you guys recently relaunched langm, that's also a form of context engineering. But I don't know if this, there's like a qualitatively or philosophical difference.
- [37:49]
Lance Martin
Yeah, so that's a good thing to hit. Actually I may be thinking about this on two dimensions. Writing memories, reading memories, and then the degree of automation on both of those. So take the simplest case, which actually I quite like Claude code, how do they do it? Well, for reading memories, they just suck in your Claude MDS every time. So every time you spin up Claude CLAUDE code, it pulls in all our Claude MDs. For writing memories, the user specifies, hey, I want to save this to memory and then cloud code writes it to CloudMD. So on this axis of like degree of automation across ReadWrite, it's kind of like the 00. It's very simple and it's kind of very like Boris pilled, like super simple and I actually quite like it. Now the other extreme is maybe ChatGPT. So behind the scenes, ChatGPT decides when to write memories and it decides when to suck them in. And actually I thought Simon at AI Engineer had a great talk on this and it wasn't about memory, but he hit memory in the talk and he mentioned, I don't know if you remember this, but it was a failure mode in image generation because he wanted an image of a particular scene and it sucked in his location and put it in the image. Like it sucked in like half moon Bay or something and sucked it in the image. It was a case of memory retrieval gone wrong. He didn't actually want that. So even in a product like ChatGPT that spent a lot of time on memory, it's non trivial. And I think my take is the writing of memories is tricky. Like when actually should the system write memories is non trivial. Reading of memories actually kind of converges with the constructionary theme of retrieval. Like memory retrieval at large scale is just retrieval. Right. I kind of view them as it's.
- [39:29]
Swix
Retrieval in a certain context, which is your past conversations, which.
- [39:33]
Lance Martin
That's right.
- [39:34]
Swix
You know, it was different than retrieval from a knowledge base, different than retrieval from the public web. By the way, this is Sakon's write up on his website on here where.
- [39:43]
Lance Martin
He was just trying to generate images.
- [39:44]
Swix
And then suddenly it shows up.
- [39:46]
Lance Martin
There you go. Actually, it's a subtle point. I don't know exactly know what OpenAI does behind the hood with respect to memory retrieval. My guess is they're indexing your past conversations using semantic vector search and probably other things. So it may still be using some kind of knowledge base or vector store for retrieval. So in that sense I kind of view it just simply as, you know, in the case of sophisticated memory retrieval, it is just like a complex rag system in the same way we talked about with like varun and building Windsurf. It's kind of a multi step rag pipeline. So I kind of view memories, at least the reading part as just, you know, it's just retrieval. And actually I quite like Claw's approach is very simple. Just the retrieval is trivial. Just suck it in every time.
- [40:26]
Swix
I would also highlight the semantic differences that you've established. Episodic semantic, procedural and background memory processing. We've done an episode with the LEDA folks on Sleep Time Compute. I think these are just like if you have ambient agents, very long running agents, you're going to run into this kind of context engineering which is previously the domain of memory. And I would say that the classic context engineering discussion doesn't have this stuff. Not yet.
- [40:53]
Lance Martin
So actually there's an interesting point there. I did a course on building ambient agents and I built this little email assistant that I used to run my email. I actually think this is a bit of a sidebar on memory. Memory pairs really well with human in the loop. So for example, in my little email assistant, it's just an agent that runs my email. I have the opportunity to pause it before it sends off an email and correct it if I want, like change the tone of this email. Or I can literally just modify the tool call to have a little UI for that. And every time when you have these ambient agents, you edit, for example, or you give it feedback, you edit, the tool calls itself that feedback can be sucked into memory. And that's exactly what I do. So I actually think memory pairs very nicely with human loop. And like when you're using human loop to make corrections to a system that should be captured in memory. And so that's a very nice way to use memory in kind of a narrow way that's just capturing user preferences over time and actually uses an LLM to actually reflect on the changes I made, reflect on the prior instructions in memory, and just update the instructions based upon my edits. And that's a very simple and effective way to use memory when you're building ambient agents that I quite like.
- [42:01]
Swix
There's. There is a course which you can find on the GitHub and yeah, I mean, you know, you guys have done plenty of talks on async agents.
- [42:07]
Lance Martin
That's right. But I think it's a very good point that memory is often kind of confusing when to use it. I think a very clear place to use it is when you're building agents that have human loop because human loop is a great place to update your agent memory with your preferences. So it kind of gets smart over time. And learn stream it is exactly what I do with my little email assistant. So Harrison, I'm sure, I think he said this publicly, uses an email assistant for all his emails. He gets a lot as a CEO. I get much fewer because I'm just a lowly guy. But I still use it and that's a very nice play Way to use memory is kind of pair it with human in the loop.
- [42:41]
Swix
Yeah, totally. I've tried to use the email system before, but like, you know, I'm still. Still very married to my superhuman.
- [42:48]
Lance Martin
Yeah, fair enough. That's right. That's right.
- [42:50]
Swix
That's about the coverage that we planned on context Eng. You have a little bit on bitter lesson that we could wrap up with.
- [42:57]
Lance Martin
Yeah, that's a fun theme to hit on a little bit. I'd love to hear your perspective. So there's a great talk from Hyungwon Chung previously OpenAI now have MSL on the bitter lesson in his approach to AI research. The take is compute 10xs every 5 years for the same cost. Of course, we all know that the history of machine learning has shown. Yeah, exactly this slide. Exactly. History of machine learning has shown that actually capturing this scaling is the most important thing. In particular, algorithms that are more general with fewer inductive biases and more data and compute tend to beat algorithms with more e.g. hand tuned features, inductive biases built in, which is to say just letting a machine learn how to think itself with more compute and data rather than trying to teach a machine how we think tends to be better. So that's kind of the bitter lesson piece, simply stated. So his argument is this subtle point that at any point in time when you're for example doing research, you typically need to add some amount of structure to get the performance you want at a given level of compute. But over time that structure can bottleneck your further progress. And that's kind of what he's showing here, is that in the low compute regime, kind of on the left of that x axis, adding more structure, for example more modeling assumptions, more inductive biases is better then less. But as compute grows, less structure. And this is exactly the bitter lesson point, less structure, more general tends to win out. So his argument was we should add structure at a given point in time in order to get something to work with the level of compute that we have today, but remember to move it later. And a lot of his argument was like people often forget to remove that structure later. And I think my link here is that I think this applies to AI engineering too. And if you kind of scroll down, I have the same chart showing my little. Exactly. This is my little example of building deep research over the course of a year. So I started with a highly structured research workflow. Didn't use tool calling. I embedded a bunch of assumptions about how research should be conducted. In particular, don't use tool calling because everyone knows tool calling is not reliable. This was back in 2024. Decompose the problem into a set of sections and parallelize each one, those sections written in parallel into the final report. What I found is you're building LM applications on top of models that are improving exponentially. So while the workflow was more reliable than building an agent back in 2024, that flipped pretty quickly as Elems got better and better. It's exactly like was mentioned in the Stanford talk. You have to be constantly reassessing your assumptions when you're building AI applications. Given the capabilities of the models I talk a lot about here, the specific structure I added, the fact that I used a workflow because we know tool calling doesn't work. This was back in 2024, the fact that I decomposed the problem because it's how I thought I should perform research and this basically bottlenecked me. I couldn't use MCP as MCP got, for example much more popular. I couldn't take advantage of the fact that tool calling was getting significantly better over time. So then I moved to an agent start to remove structure, allow for tool calling, let the agent decide the research path. A subtle mistake that I made which links back to that point about failing to remove structure. I actually wrote the report sections within each subagent. So this kind of links back to what we talked about with subagents in isolation. Sub agents don't communicate effectively with one another. So if you write report sections in each subagent, the final report is actually pretty disjointed. This is exactly Alessio's challenge and problem bout using multi agent. So I actually hit that exact problem. So I ripped out the independent writing and did a one shot writing at the end. And this is the current kind of version of OpenDeep research which is quite good. And this is kind of the thing that's at least on deep research cements the best performing open deep research assistant, at least that's open source. So it was kind of my own arc. Although we do have some faded results with GPT5 that are quite strong. So you know, the models are always getting better and so indeed our open source assistant actually takes advantage and rides that wave. But I actually kind of experienced I felt like I actually got bitter lessons myself because I started with a system that was very reliable for the current state of models back in mid 2024, early 2024. But I was completely bottlenecked as models got better. I had to rip out the entire system and rebuild it twice, rechecking my assumptions in order to kind of capture the gains of the model. So I think I just want to flag I think this is an interesting point. It's hard to build on top of rapidly expanding models, rapidly improving model capability. And actually I really enjoyed from AI engineer Boris's talk on cloud code and they're very bitter lesson pilled. He talks a lot about the fact that they make cloud code very simple and very general. Because of this fact, they want to give users unfettered access to the model without much scaffolding around it. But I think it's an interesting consideration in AI engineering that we're building on top of models that are improving exponentially. And one of the points he makes is a corollary or the bitter lesson is that more general things around the model tend to win. And so when building applications we should be thinking about this, we should be adding structure necessary to get things to work today. And by keeping a close eye on models, improving rapidly and removing structure in order to unbottleneck ourselves. I think that was my takeaway. So I really liked the talk from Hyungwon Chung. I think that's worth everyone listening to. And I think a lot of lessons apply to AI engineering.
- [48:41]
Alessio
I think this is similar to incumbents adopting AI putting in existing tools because you already have the workflow, right? So you already have all the structure. You just put AI, it becomes better, but then the AI native approaches catch up as the models get better and then there's no way for existing products to remove the structure because the structure is the product, you know, and that's why then you have, you know, Cursor and Windsurf are being are better than VS code for like a native thing just because they didn't have to deal with removing things and why cognition is like, you know, again, it's like it doesn't even think about the idea as like the first thing. The ID is like a piece of the agent. And so I think you see this in a lot of markets, which is like, hey, again, if you have a workflow and you put AI, the workflow is better. The workflow is not the end goal. I think we're now at a place where you should just start without a lot of structure, just because now the models are so good. But I think the first two and a half years of the market there was kind of the stance of should I just put AI into the workflow that works, Should I rewrite the workflow? But the workflow is not that good because the models are not that good. But I think we're past that point now.
- [49:47]
Lance Martin
That's an amazing example actually. If you show your chart again, there's another interesting point in your chart. In the earlier model regime, the structured approach is actually better. And so an interesting take on this. Jared Kaplan, the founder of Anthropic, has a great talk at Startup School from a couple weeks ago and he mentions this point about oftentimes building products that explicitly don't quite work yet can be a good approach because a model under them is premium exponentially and it'll kind of unlock the product. We saw that with cursor. Part of the cursor lore is that it, it did not work particularly well. Cloud 3.5 hits and then boom, it kind of unlocks the product. And so you kind of hit that knee of the curve when the model capability catches up to the Product needs. But in that earlier regime, the structured approach appears better. So it's kind of this interesting, subtle point that for a while the more structured approach appears better, and then the model finally hits the capability needed to unlock your product and suddenly your product just takes off. There's kind of another corollary to this that you can get tricked into thinking your structured approach is indeed better because it'll be better for a while until the model catches up with less structured approaches.
- [50:56]
Swix
Your chart looks very similar to the Windsurf chart. I gotta bring it up because I was involved in the writing of this one. Isn't that similar? This is ceiling and then boom, you go slow lesson. But in Enterprise S that's right for me, okay, the lines are important, but to me the bullet points are the main thing. If you understand the bullet points, then you cannot. You can actually learn from the mistakes of others.
- [51:21]
Lance Martin
Right.
- [51:22]
Swix
There is one spicy take on this, which is like, you know, how much is landgraaff aligned with the bitter lesson? Yes, obviously, you guys are obviously aware of it, so it's not going to be a surprise. But I do think that making abstraction is easy to unwind is very important if you believe in a bitter lesson, which you do.
- [51:41]
Lance Martin
No, no, this is super important actually. And I actually talked about this at the end of the post.
- [51:45]
Swix
Yeah.
- [51:45]
Lance Martin
There's an interesting subtlety when you talk about Asian frameworks and a lot of people are anti framework. I completely understand and sympathetic to those points, but I think when people talk about frameworks, there's two different things. So there can be a low level orchestration framework. There's a great talk, for example, at Anthropic from Shopify, they built this orchestration framework called Roast internally and it's basically Langgraph. It's some kind of way to build kind of internal orchestration workflows with LLMs and Roast. Langgraph provides you low level building blocks, nodes, edges, state, which you can compose into agents. You can compose into workflows. I don't hate that. I like working low level building blocks. They're pretty easy to tear down, rebuild. In fact, I used for example, langgraph to build OpenDeep research. I had a workflow, I rip it out, I reboot. With agent, the building blocks are low level, just nodes, edges, state. But the thing I'm sympathetic to is there's also, in addition to just kind of low level orchestration frameworks, there's also agent abstractions from framework, import, agent. That is actually where you can get into more trouble because you might not know what's behind that abstraction. I think when a lot of people kind of are anti framework, I think what they're really saying is they're largely anti abstraction, which I'm actually very sympathetic to. And I don't particularly like agent abstractions for this exact reason. And I think Walden Yanz made a good point. Like we're very early in the archive agents, we're like in the HTML era. And agent abstractions are problematic because you don't know what's necessarily under the hood of the abstraction. You don't understand it. And if I was building, for example, OpenDEEP research with an abstraction, I wouldn't necessarily know how to rip it apart and rebuild it when models got better. So I'm actually wary of abstractions. I'm very sympathetic to that part of the critique of frameworks, but I don't hate low level orchestration frameworks that just provide nodes edges. You can just recombine them in any way you want. And then the question is why use orchestration at all? And actually I use Langgraph because you get some nice use, you get checkpointing, you get state management. It's low level stuff. And that's the way I happen to use langgraph. And that's why I like Langgraph. And that's actually why I found like a lot of customers like langgraph. It's not necessarily for the agent abstraction, which I agree can be much trickier. Some people like agent abstractions. That's completely fine as long as you understand what's under the hood. But I think that's a very interesting debate about frameworks. I think the critique is it should be made a little bit more on abstractions because often people don't know what's under the hood.
- [54:13]
Swix
For those who are looking for resources, it was a bit hard to find the Shopify talk.
- [54:18]
Lance Martin
Yeah, it's unlisted now. I don't know why it's unlisted, but it's a nice talk.
- [54:22]
Swix
I found it through this Chinese rip off of the talk.
- [54:26]
Lance Martin
Yeah, it's actually hard to find now.
- [54:28]
Swix
I think there should be a browse comp where you find obscure YouTube videos because that's something I'm very good at. Just kind of my bread and butt.
- [54:36]
Lance Martin
It's good. And you know what's funny is this talk follows exactly the arc we often see when we're talking to companies about Langgraph. It is people want to build agents and workflows internally. Everyone rolls their own. It becomes hard to kind of manage and coordinate and review code in this context of large organizations, it can be very helpful to have a standard library or framework that people are using with low level components that are easily composable. That's what they build with Roast. That's effectively what Landgraph is. And that's why a lot of people like langgraph. I actually thought the talk on MCP that I believe it was, it was John Welsh.
- [55:12]
Swix
Yes. I think that was like a super underrated talk. I tried yelling about it, no one listened to me. But like, you know, if you listen this far into the podcast, do us a favor, actually listen to John Welch's talk. It's actually very good.
- [55:25]
Lance Martin
It's very good. He makes a case for a lot of the reason why people actually, for example enterprises, larger companies like Langgraph, which is the fact that when tool calling got good within anthropic and you know, sometime mid last year, he actually makes this point explicitly. So he mentions, okay, so you're in anthropic. Tool calling gets good in mid 2024, everyone's building their own integrations. It becomes complete chaos. And that's actually where kind of MCP came from. Let's build a kind of a standard protocol for accessing tools. Everyone adopts it much easier to kind of have auth and have review and you minimize cognitive load. And this is actually the argument for standardized tooling, whether it be frameworks or otherwise within larger orgs is practicality. And he actually his whole talk is making that very pragmatic point, which is actually why people do tend to like frameworks, for example, in larger organizations and.
- [56:15]
Swix
Then ship it as a gateway. This is the other big thing that they do.
- [56:21]
Lance Martin
That's right.
- [56:21]
Swix
Lance, you've been so generous of your time. Thank you. Any shameless plugs, calls to action, stuff like that?
- [56:27]
Lance Martin
Yeah, if you'll made it this far. Thanks for listening. We have a bunch of different courses I've taught. One on ambient agents, one on building open deep research. So I actually was very inspired by Karpathy. Had a tweet a long time ago talking about building on ramps. So he talked about he had his micrograd repo. A few people looked at it, but not that many. He made a YouTube video and that created an onramp and the repo skyrocketed in popularity. So I like this one two punch of building a thing like OpenDeep Research, then creating a class so people can actually understand how to build it themselves. And I kind of like that. Build a thing, create an on ramp for it. So I have a class on building opendeep research. Feel free to it's for free, but it walks through a bunch of notebooks as to how I build it. And you can see the agent is quite good. We even have better results coming out soon with GPT5. So if you want kind of an open source deep research agent, have a look at it. It's been pretty fun to build. And that's exactly what I talked about in that Bitter Lesson blog post as well.
- [57:18]
Alessio
Awesome. Lance, thank you for joining.
- [57:20]
Lance Martin
Yeah, a lot of fun. Great to be on.